This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
(Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. A data lake!
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. With these functions, teams can run tasks such as semantic filters and joins across unstructureddata sets using familiar SQL syntax.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
Multiple levels: Rawdata is accepted by the input layer. What follows is a list of what each neuron does: Input Reception: Neurons receive inputs from other neurons or rawdata. There is a distinct function for each layer in the processing of data: Input Layer: The first layer of the network.
In the real world, data is not open source , as it is confidential and may contain very sensitive information related to an item , user or product. But rawdata is available as open source for beginners and learners who wish to learn technologies associated with data.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collection process and identifying the valuable data. Data Architects The data architect's job is to create blueprints for data management systems.
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructuredrawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
We will also address some of the key distinctions between platforms like Hadoop and Snowflake, which have emerged as valuable tools in the quest to process and analyze ever larger volumes of structured, semi-structured, and unstructureddata. They may want to look at those numbers on a daily or weekly basis.
Statistics are used by data scientists to collect, assess, analyze, and derive conclusions from data, as well as to apply quantifiable mathematical models to relevant variables. Microsoft Excel An effective Excel spreadsheet will arrange unstructureddata into a legible format, making it simpler to glean insights that can be used.
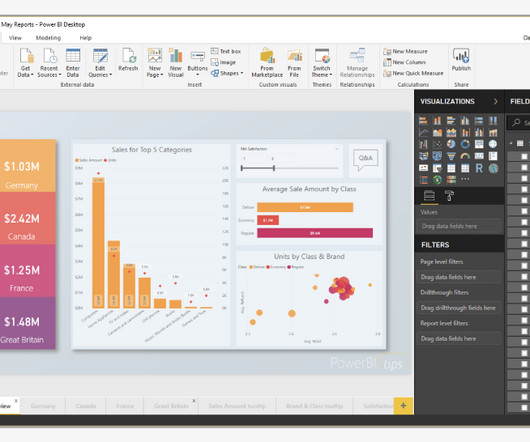
Power BI is a technology-driven business intelligence tool or an array of software services, apps, and connectors to convert unrelated and rawdata into visually immersive, coherent, actionable, and interactive insights and information. Microsoft developed it and combines business analytics, data visualization, and best practices.
Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. The data lakes store data from a wide variety of sources, including IoT devices, real-time social media streams, user data, and web application transactions.
Basically, no more partial updates or data conflictseverything stays accurate and intact, even with multiple users accessing the data at once. Data Versioning: Want to know how your data changed over time? Improved Performance: Rawdata lakes can be slow since they require scanning every file during a search.
The spectrum of sources from which data is collected for the study in Data Science is broad. These data have been accessible to us because of the advanced and latest technologies which are used in the collection of data. What is the role of a Data Engineer?
With pre-built functionalities and robust SQL support, data warehouses are tailor-made to enable swift, actionable querying for data analytics teams working primarily with structured data. This is particularly useful to data scientists and engineers as it provides more control over their calculations. Or maybe both.)
When it comes to storing large volumes of data, a simple database will be impractical due to the processing and throughput inefficiencies that emerge when managing and accessing big data. This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle.
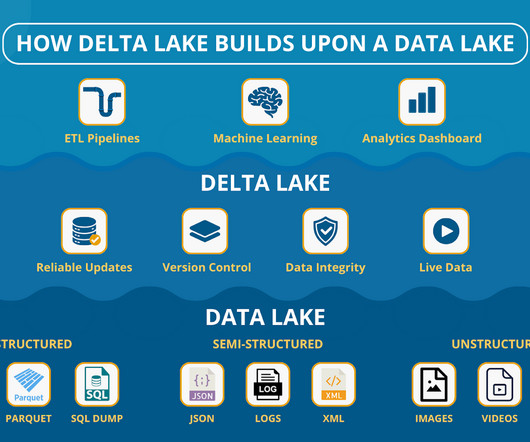
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. The collection of source data shown on your left is composed of both structured and unstructureddata from the organization’s internal and external sources.
Cleaning Bad data can derail an entire company, and the foundation of bad data is unclean data. Therefore it’s of immense importance that the data that enters a data warehouse needs to be cleaned. Data can be loaded in batches or can be streamed in near real-time.
Loading is the process of warehousing the data in an accessible location. The difference here is that warehoused data is in its raw form, with the transformation only performed on-demand following information access. One of the leaders in the space focused on data transforms is dbt.
If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructureddata on their models or analysis. For example, an industrial analytics team wants to use the logs from rawdata.
Viewing Data Lakes as a strategy rather than a product emphasizes their role as a staging area for structured and unstructureddata, potentially interacting with Data Warehouses.
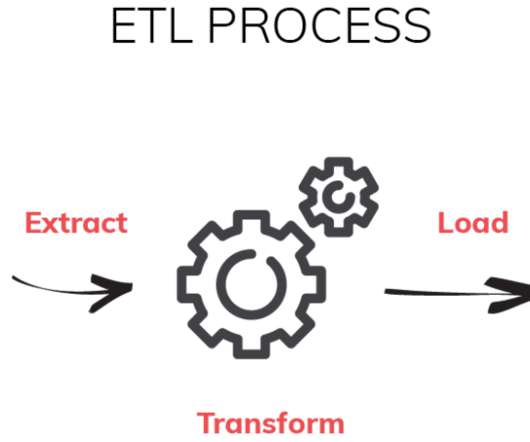
But in a world that favors the here and now, ETL processes lack in the area of providing analysts with new, fresh data. Low in Visibility End-users won’t be able to access all the data in the final destination, only the data that was transformed and loaded. This causes two issues. This is when ELT came in.
As the magnitude and role of data in society has changed, so have the tools for dealing with it. While a +3500 year data retention capability for data stored on clay tablets is impressive, the access latency and forward compatibility of clay tablets fall a little short.
What Is Data Engineering? Data engineering is the process of designing systems for collecting, storing, and analyzing large volumes of data. Put simply, it is the process of making rawdata usable and accessible to data scientists, business analysts, and other team members who rely on data.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Unstructureddata sources.
DL models automatically learn features from rawdata, eliminating the need for explicit feature engineering. Data Types and Dimensionality ML algorithms work well with structured and tabular data, where the number of features is relatively small.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Hadoop technology is the buzz word these days but most of the IT professionals still are not aware of the key components that comprise the Hadoop Ecosystem. What is Big Data and Hadoop?
Organisations and businesses are flooded with enormous amounts of data in the digital era. Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation.
By accommodating various data types, reducing preprocessing overhead, and offering scalability, data lakes have become an essential component of modern data platforms , particularly those serving streaming or machine learning use cases.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace. PREVIOUS NEXT <
It’s not a single technology, but rather an architectural approach that unites storages, data integration and orchestration tools. With a data hub, businesses receive the means to structure, and harmonize information collected from various sources. Data lake vs data hub. Dataaccess layer: data querying.
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
To reduce development time and increase data reliability, DataOps engineers automate manual processes, such as data extraction and testing. Managing the production of data pipelines. A DataOps engineer provides organizations with access to structured datasets and analytics they will further analyze and derive insights from.
However, with the rise of the internet and cloud computing, data is now generated and stored across multiple sources and platforms. This dispersed data environment creates a challenge for businesses that need to access and analyze their data. The Transform Phase During this phase, the data is prepared for analysis.
Data plays a crucial role in identifying opportunities for growth and decision-making in today's business landscape. Business intelligence collects techniques, tools, and methodologies organizations use to transform rawdata into valuable information and meaningful insights.
Data lakes provide the flexibility you need because they can store structured, unstructured, and semi-structured data in their native formats. Wants to leverage the power of advanced analytics, AI, and machine learning on large volumes of rawdata. Data lakes offer a scalable and cost-effective solution.
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. Accessing this information lets you engage in profitable stocks and ventures and make better financial decisions.
In today's world, where data rules the roost, data extraction is the key to unlocking its hidden treasures. As someone deeply immersed in the world of data science, I know that rawdata is the lifeblood of innovation, decision-making, and business progress. What is data extraction?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content