This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
(Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today.
The next evolution in data is making it AI ready. For years, an essential tenet of digital transformation has been to make dataaccessible, to break down silos so that the enterprise can draw value from all of its data. For this reason, internal-facing AI will continue to be the focus for the next couple of years.
AI agents, autonomous systems that perform tasks using AI, can enhance business productivity by handling complex, multi-step operations in minutes. Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. text, audio) and structured (e.g.,
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. Traditionally, SQL has been limited to structureddata neatly organized in tables.
Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew. The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems.
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structureddata (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases.
As my thoughts started wandering around our Banking systems and Cosmos Bank Cyber-attack 2018. There is a rapid increase in banking frauds like identity theft, phishing, vishing, smishing, access to debit/credit card details, and UPI/QR code scams. The system should time and again monitor and report audit authorities.
Data Silos: Breaking down barriers between data sources. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). Start the Data Governance Process: Don't wait until the last minute to build the data governance framework.
I found the product blog from QuantumBlack gives a view of data quality in unstructured data. link] Pinterest: Advancements in Embedding-Based Retrieval at Pinterest Homefeed Pinterest writes about its embedding-based retrieval system enhancements for Homefeed personalization and engagement.
You’ll learn about the types of recommender systems, their differences, strengths, weaknesses, and real-life examples. Personalization and recommender systems in a nutshell. Primarily developed to help users deal with a large range of choices they encounter, recommender systems come into play. Amazon, Booking.com) and.
Along with SNP Glue, the Snowflake Native App gives customers a simple, flexible and cost-effective solution to get data out of SAP and into Snowflake quickly and accurately. What’s the challenge with unlocking SAP data? Getting direct access to SAP data is critical because it holds such a breadth of ERP information.
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Here are six key components that are fundamental to building and maintaining an effective data pipeline. It offers scalable and high-performance tools that enable efficient dataaccess and utilization.
For this reason, a new data management for ML framework has emerged to help manage this complexity: the “feature store.” Feature store As described in Tecton’s blog , a feature store is a data management system for managing ML feature pipelines, including the management of feature engineering code and data.
It provides access to industry-leading large language models (LLMs), enabling users to easily build and deploy AI-powered applications. By using Cortex, enterprises can bring AI directly to the governed data to quickly extend access and governance policies to the models.
Rather than defining schema upfront, a user can decide which data and schema they need for their use case. Snowflake has long supported semi-structureddata types and file formats like JSON, XML, Parquet, and more recently storage and processing of unstructured data such as PDF documents, images, videos, and audio files.
So I decided to focus my energies in research data management. Open Context is an open accessdata publishing service for archaeology. It started because we need better ways of dissminating structureddata and digital media than is possible with conventional articles, books and reports.
As a result, a Big Data analytics task is split up, with each machine performing its own little part in parallel. Hadoop hides away the complexities of distributed computing, offering an abstracted API to get direct access to the system’s functionality and its benefits — such as. A file stored in the system ?an’t
For example, when theres an issue, only the ML, BE, or engineers have access to the AI stack, system, and logs to understand the issue, and only the data scientists have the expertise to actually solve it. With that expansion comes new challenges and new learning opportunities when it comes to GenAI development.
For example, when theres an issue, only the ML, BE, or engineers have access to the AI stack, system, and logs to understand the issue, and only the data scientists have the expertise to actually solve it. With that expansion comes new challenges and new learning opportunities when it comes to GenAI development.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
Create Snowflake dynamic tables In Snowflake, create dynamic tables by writing SQL queries that define how data should be transformed and materialized. Grant ThoughtSpot access In Snowflake, grant the ThoughtSpot service account USAGE privileges on the schemas containing the dynamic tables. Set refresh schedules as needed.
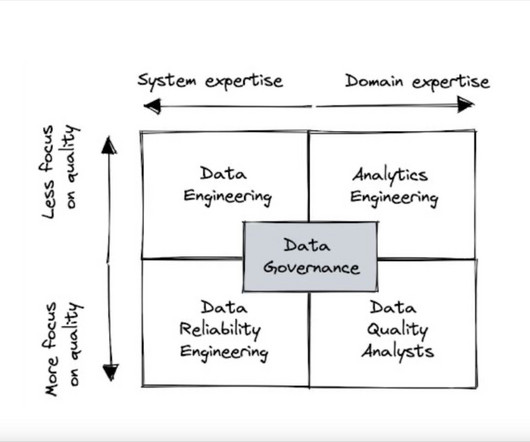
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Having the data engineering team lead the response to data quality is by far the most common pattern. It is deployed by about half of all organizations that use a modern data stack.
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Photo by Luke Chesser on Unsplash Having the data engineering team lead the response to data quality is by far the most common pattern. There are downsides to this approach however.
As mentioned in my previous blog on the topic , the recent shift to remote working has seen an increase in conversations around how data is managed. Toolsets and strategies have had to shift to ensure controlled access to data. Driving innovation with secure and governed data .
We recently launched a new artificial intelligence (AI) data extraction API called Scrapinghub AutoExtract , which turns article and product pages into structureddata. At Scrapinghub, we specialize in web data extraction , and our products empower everyone from programmers to CEOs to extract web data quickly and effectively.
By enabling their event analysts to monitor and analyze events in real time, as well as directly in their data visualization tool, and also rate and give feedback to the system interactively, they increased their data to insight productivity by a factor of 10. . This led them to fall behind.
They build scalable data processing pipelines and provide analytical insights to business users. A Data Engineer also designs, builds, integrates, and manages large-scale data processing systems. It’s not just the data itself that is important, but also how that data can be used to make better decisions.
Sharvit deconstructs the elements of complexity that sometimes seems inevitable with OOP and summarizes the main principles of DOP that helps us make the system more manageable. As its name suggests, DOP puts data first and foremost. to control who can access/change data in Python. These principles are language-agnostic.
paintings, songs, code) Historical data relevant to the prediction task (e.g., Unlike traditional AI systems that operate on pre-existing data, generative AI models learn the underlying patterns and relationships within their training data and use that knowledge to create novel outputs that did not previously exist.
In fact, data product development introduces an additional requirement that wasn’t as relevant in the past as it is today: That of scalability in permissioning and authorization given the number and multitude of different roles of data constituents, both internal and external accessing a data product.
A database is a structureddata collection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloud storage keeps larger datasets. According to a database model, the organization of data is known as database design.
According to the Cybercrime Magazine, the global data storage is projected to be 200+ zettabytes (1 zettabyte = 10 12 gigabytes) by 2025, including the data stored on the cloud, personal devices, and public and private IT infrastructures. Data Analyst Scientist.
Flexibility and Modularity : The modular design of LangChain lets coders change how parts work, connect them to other systems, and try out different setups. External API Calls LLMs can talk to APIs to get data in real time, do calculations, or connect to outside systems like databases and search engines. How does LangChain work?
Among governments’ priorities are encouraging digital adoption, facilitating access and usage of relevant government services alongside enabling more digital transactions. Among the use cases for the government organizations that we are working on is one which leverages machine learning to detect fraud in payment systems nationwide.
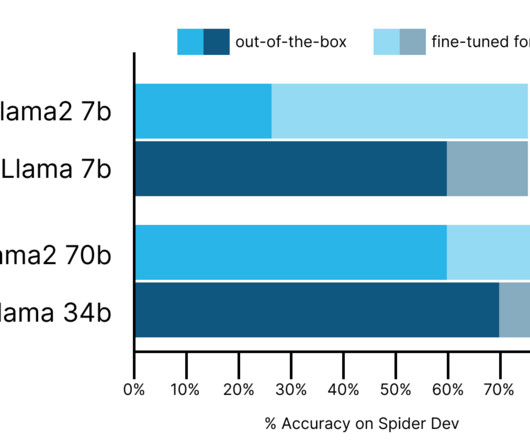
Our Code Llama fine-tuned (7b, 34b) for text-to-SQL outperforms base Code Llama (7b, 34b) by 16 and 9 percent-accuracy points respectively Evaluating performance of SQL-generation models Performance of our text-to-SQL models is reported against the “dev” subset of the Spider data set.
This data pipeline is a great example of a use case for Apache Kafka ®. Observational astronomers study many different types of objects, from asteroids in our own solar system to galaxies that are billions of lightyears away. The technology underlying the ZTF system should be a prototype that reliably scales to LSST needs.
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
The motivation for Machine Unlearning is critical from the privacy perspective and for model correction, fixing outdated knowledge, and access revocation of the training dataset. link] LinkedIn: LakeChime - A Data Trigger Service for Modern Data Lakes LinkedIn points out two critical flaws in a partitioned approach to data management.
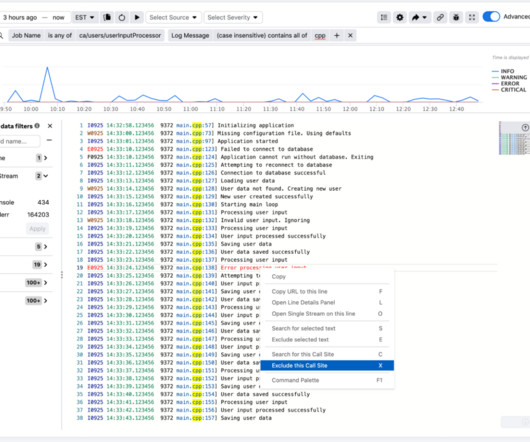
This operational component places some cognitive load on our engineers, requiring them to develop deep understanding of telemetry and alerting systems, capacity provisioning process, security and reliability best practices, and a vast amount of informal knowledge about the cloud infrastructure.
Systems and application logs play a key role in operations, observability, and debugging workflows at Meta. We designed the system to support service-level guarantees on log freshness, completeness, durability, query latency, and query result completeness. PyTorch, data readers, checkpointing, framework code, and hardware).
Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is Data Warehouse? . Built to make strategic use of data, a Data Warehouse is a combination of technologies and components. Data Warehouse in DBMS: .
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). While functional, our current setup for managing tables is fragmented.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, data warehouses can experience limitations and scalability challenges.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, data warehouses can experience limitations and scalability challenges.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content