This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern IT environments require comprehensive data for successful AIOps, that includes incorporating data from legacy systems like IBM i and IBM Z into ITOps platforms. AIOps presents enormous promise, but many organizations face hurdles in its implementation: Complex ecosystems made of multiple, fragmented systems that lack interoperability.
Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. With data volumes skyrocketing, and complexities increasing in variety and platforms, traditional centralized data management systems often struggle to keep up.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
This is crucial for applications that require up-to-date information, such as fraud detection systems or recommendation engines. Data Integration : By capturing changes, CDC facilitates seamless data integration between different systems. Finally, the control plane emits enriched metrics to enable effective monitoring of the system.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
It provides a simplified, intuitive interface where users can explore AI/BI Dashboards, ask questions using natural language via Genie, and access custom Databricks Apps. This feature allows tables governed in Unity Catalog to be accessed by Microsoft Fabric, enabling interoperability via Unity Catalog Open APIs.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service.
These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. The simple idea was, hey how can we get more value from the transactional data in our operational systems spanning finance, sales, customer relationship management, and other siloed functions.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products. Hack, C++, Python, etc.)
User code and data transformation are abstracted so they can be easily moved to any other data processing systems. Cross-Platform Abstraction : Abstracted data transformations can be run in serving systems or any other ML data processing framework such as Spark, PyTorch, Huggingface, etc. CUSTOM: For customized joining.
But as technology speeds forward, organizations of all sizes are realizing that generative AI isn’t just aspirational: It’s accessible and applicable now. Alberta Health Services ER doctors automate note-taking to treat 15% more patients The integrated health system of Alberta, Canada’s third-most-populous province, with 4.5
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
To put it simply, it is a system that collects data from various sources, transforms, enriches, and optimizes it, and then delivers it to one or more target destinations. Its key goals are to store data in a format that supports fast querying and scalability and to enable real-time or near-real-time access for decision-making.
APIs facilitate communication between different systems, allowing data to flow seamlessly across platforms. Encrypting data both at rest and in transit ensures that sensitive information remains protected from unauthorized access. Access Controls Access controls are another critical component of data pipeline security.
Thus, securing suitable data is crucial for any data professional, and data pipelines are the systems designed for this purpose. Data pipelines are systems designed to move and transform data from one source to another. Load data into an accessible storage location. Transform data into a valid format.
On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Are your tools simple to implement and accessible to users with diverse skill sets? Create a Plan for Integration: Automation tools need to work seamlessly with existing systems to be effective.
How can a system that continuously updates decisions consider these constantly changing and uncertain factors? The answer lies in building a dynamic inventory optimisation system. This requires a scalable and efficient forecasting system.
Last year, we unveiled data intelligence – AI that can reason on your enterprise data – with the arrival of the Databricks Mosaic AI stack for building and deploying agent systems. Agents deployed on AWS, GCP, or even on-premise systems can now be connected to MLflow 3 for agent observability.
Data ingestion systems such as Kafka , for example, offer a seamless and quick data ingestion process while also allowing data engineers to locate appropriate data sources, analyze them, and ingest data for further processing. It can also access structured and unstructured data from various sources.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks.
[link] Booking.com: Unlocking the Power of Customization: How Our Enrichment System Transforms Recommendation Data Enrichments Booking.com shares how it revamped its Recommendation Platform’s enrichment layer to tackle issues of tight coupling and low reusability when attaching data like prices, wishlist counts, and images to recommendations.
Last year, the promise of data intelligence – building AI that can reason over your data – arrived with Mosaic AI, a comprehensive platform for building, evaluating, monitoring, and securing AI systems. Too many knobs : Agents are complex AI systems with many components, each that have their own knobs.
Sync audience and guest data to email platforms, customer relationship management (CRM) systems, advertising platforms or any other marketing tool that drives personalized travel experiences. A Composable CDP benefits from Snowflake’s built-in governance to help customers manage how data is accessed.
With the surge of new tools, platforms, and data types, managing these systems effectively is an ongoing challenge. Ultimately, they are trying to serve data in their marketplace and make it accessible to business and data consumers,” Yoğurtçu says. However, they require a strong data foundation to be effective.
This technique is vital for ensuring consistency and accuracy across datasets, especially in organizations that rely on multiple data systems. Integration facilitates seamless data flow and accessibility, which is crucial for real-time analytics and decision-making.
Introduction Encouraged by its growing popularity and increasing adoption in the Big Data community, we explored Kubernetes (K8s)-based systems as the most likely replacement for Hadoop 2.x. Built-in Container Support Unlike Hadoop, Kubernetes was built as a container orchestration system, first and foremost.
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance.
AWS CloudWatch With the help of AWS CloudWatch , you can consolidate all of your system, application, and AWS service logs into a single, highly scalable service. Amazon IAM AWS Identity and Access Management (IAM) is another popular AWS service that enables you to control access to AWS resources.
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. Enter DataJunction (DJ).
With a beautiful and streamlined user interface as well as access to curated AI/BI Genie spaces, Dashboards and Databricks Apps, Databricks One is designed to help business teams make smarter decisions without needing to be expert technical practitioners. The full Databricks One experience will enter beta later this summer.
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
To eliminate data redundancy, data modeling brings together data from diverse systems. It makes data more accessible. A primary key is a column or set of columns in a relational database management system table that uniquely identifies each record. What is a hierarchical database management system (DBMS)?
Meanwhile, customers are responsible for protecting resources within the cloud, including operating systems, applications, data, and the configuration of security controls such as Identity and Access Management (IAM) and security groups. Shared Controls Responsibilities are split between AWS and the customer.
Building Reliable Foundations for Data + AI Systems It’s no big revelation that data teams are being challenged to do more with AI. But when it comes to AI systems, the playbook for trust is still largely unwritten. Pipelines can traverse a multitude of systems and teams with limited oversight. But AI ≠ traditional software.
As a big data architect or a big data developer, when working with Microservices-based systems, you might often end up in a dilemma whether to use Apache Kafka or RabbitMQ for messaging. Apache Kafka and RabbitMQ are messaging systems used in distributed computing to handle big data streams– read, write, processing, etc.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Data Engineer Jobs- The Demand Data Scientist was declared the sexiest job of the 21st century about ten years ago. The role of a data engineer is to use tools for interacting with the database management systems.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. To address these challenges, AI Data Engineers have emerged as key players, designing scalable data workflows that fuel the next generation of AI systems. How does a self-driving car understand a chaotic street scene?
It serves as a vital protective measure, ensuring proper data access while managing risks like data breaches and unauthorized use. Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems.
Data pipelines are crucial in managing the information lifecycle, ensuring its quality, reliability, and accessibility. Check out the following insightful post by Leon Jose , a professional data analyst, shedding light on the pivotal role of data pipelines in ensuring data quality, accessibility, and cost savings for businesses.
Uber stores its data in a combination of Hadoop and Cassandra for high availability and low latency access. Every time you play, skip, or save a song, Spotify notes the behavior and passes it to their recommendation system through Kafka. Flink then gets to work finding the nearest available driver and calculating your fare.
Vector and raster each have their use cases, and sometimes you need to access both; the quickstart tackles that head-on. But really, these are just representative files to showcase how we can access these types of files in Snowflake and ultimately use them in a specific analysis. Load the shapefile. Running Kepler.gl
Manager, Technical Marketing Content Get the newsletter Subscribe to get our latest insights and product updates delivered to your inbox once a month As organizations adopt more tools and platforms, their data becomes increasingly fragmented across systems. And as the global data integration market is projected to grow from $17.10
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












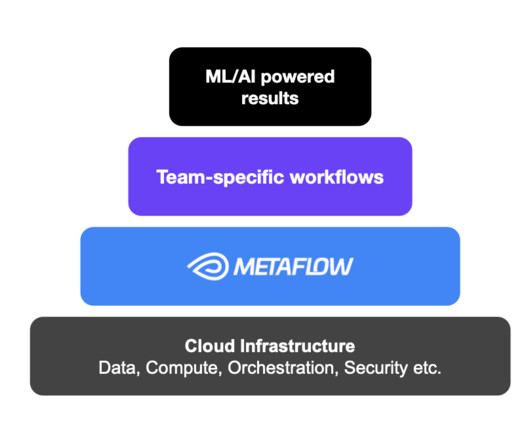








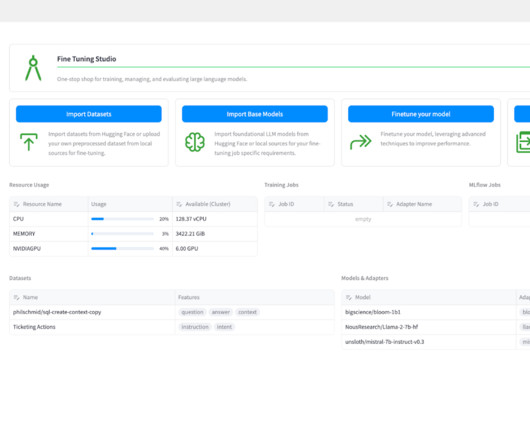




















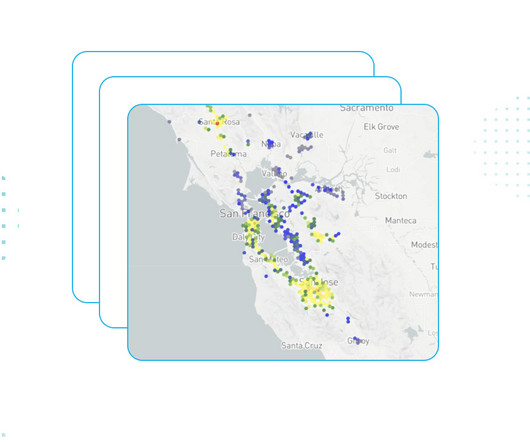







Let's personalize your content