This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, if your metric dashboard shows users experiencing higher latency as they scroll through their home feed, then that could be caused by anything from an OS upgrade, a logging or data pipeline error, an unusually large increase in user traffic, a code change landed recently, etc. a new recommendation algorithm).
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
As a CDO, I need full data life cycle capability. I must store data efficiently and resiliently, pipe and aggregatedata into data lakehouses, and apply machine learning algorithms and AI to uncover actionable insights for our business units. Second, reach. Thing#1 and Thing#2. CDP gets me all of it.
By leveraging cutting-edge technologies, machine learning algorithms, and a dedicated team, we remain committed to ensuring a secure and trustworthy space for professionals to connect, share insights, and foster their career journeys. These algorithms consider the diversity and context of signals to make informed decisions.
After all, machine learning with Python requires the use of algorithms that allow computer programs to constantly learn, but building that infrastructure is several levels higher in complexity. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. For now, we’ll focus on Kafka.
Silver Layer: In this zone, data undergoes cleaning, transformation, and enrichment, becoming suitable for analytics and reporting. Access expands to data analysts and scientists, though sensitive elements should remain masked or anonymized. Grab’s blog on migrating from RBAC to ABAC is an excellent reference design.
In this blog post, we talk about the landscape and the challenges in workflows at Netflix. IPS enables users to continue to use the data processing patterns with minimal changes. Introduction Netflix relies on data to power its business in all phases. This enables auto propagation of backfill data in multi-stage pipelines.
Internally, we apply a recursive algorithm to eliminate subsets of the data that contribute most to imbalance, similar to what an experimenter would do in the process of salvaging data from SRM. Using weights in regression allows efficient scaling of the algorithm, even when interacting with large datasets.
The most advanced AI algorithms achieved the accuracy of almost 97 percent. Source: AWS Machine Learning Blog. Data de-identification / anonymization. Under regulations, all sensitive details that link an image to a particular individual must be removed or hidden before you feed data to your algorithm.
Data visualization: Showcasing analyzed data in an easily understandable format through dashboards, charts, and graphs, to enable interpretation by teams in charge of maintaining system health, and other stakeholders in the organization. Observability Platform vs. Observability Tools: What Is the Difference?
Building a full customer 360 requires aggregatingdata sets into a single view. DOCOMO Digital uses algorithms to determine the best advertising content that helps maximize consumer conversion rates. You can also read about Cloudera Data Science and Engineering here. Driving customer insights with machine learning.
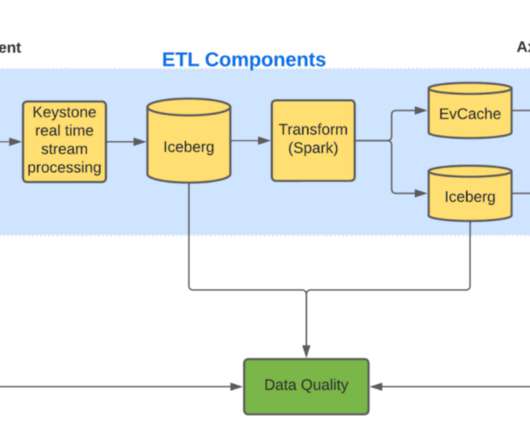
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
To achieve this, we rely on Machine Learning (ML) algorithms. ML algorithms can be only as good as the data that we provide to it. This post will focus on the large volume of high-quality data stored in Axion?—?our The Iceberg table created by Keystone contains large blobs of unstructured data.
The latter create integrated, higher-value data products that are geared towards requirements of the data consumers on the business side; for example, a customer 360 domain aggregatingdata from multiple sources. Some teams are data producers but not data consumers. It’s not just the data teams.
Azure Data Engineers are in high demand due to the growth of cloud-based data solutions. In this article, we will examine the duties of an Azure Data Engineer as well as the typical pay in this industry. Conclusion So this was all about the salary, job description, and skills of an Azure Data Engineer.
It doesn't matter if you're a data expert or just starting out; knowing how to clean your data is a must-have skill. The future is all about big data. This blog is here to help you understand not only the basics but also the cool new ways and tools to make your data squeaky clean.
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. Finally, you'll find a list of PySpark projects to help you gain hands-on experience and land an ideal job in Data Science or Big Data.
In this blog, we’ll describe how Klarna implemented real-time anomaly detection at scale, halved the resolution time and saved millions of dollars using Rockset. Furthermore, Rockset’s ability to pre-aggregatedata at ingestion time reduced the cost of storage and sped up queries, making the solution cost-effective at scale.
The credit for coining the new role goes to Michael Kaminsky , a former Director of Analytics at Harry’s Grooming and a founder of Recast, who wrote the article about analytics engineering on the Locally Optimistic blog in 2019. Analytics engineers may also take care of writing cleansing algorithms to further improve the quality of data.
Table of Contents 20 Open Source Big Data Projects To Contribute How to Contribute to Open Source Big Data Projects? 20 Open Source Big Data Projects To Contribute There are thousands of open-source projects in action today. This blog will walk through the most popular and fascinating open source big data projects.
Data professionals who work with raw data like data engineers, data analysts, machine learning scientists , and machine learning engineers also play a crucial role in any data science project. And, out of these professions, this blog will discuss the data engineering job role.
This Python library is closely linked with NumPy and pandas data structures. Seaborn strives to make visualization a key component of data analysis and exploration, and its dataset-oriented plotting algorithms use data frames comprising entire datasets. Altair features dependencies such as python 3.6,
SQL Projects For Data Analysis Hoping the example above has fueled you with the zeal to enhance your programming skills in SQL , we present you with an exciting list of SQL projects for practice. You can use these SQL projects for data analysis and add them to your data analyst portfolio.
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry.
Since data fuels the growth of smart cities, it is crucial for governments to invest in data management and data security platforms, advanced analytics, and machine learning. Cost-effectively ingest, store and utilize data from all IoT devices.
Experimentation is embedded into DoorDash’s product development and growth strategy, and we run a lot of experiments with different features , products , and algorithms to improve the user experience, increase efficiency, and also gather insights that can be used to power future decisions.
This is the second post in a series by Rockset's CTO Dhruba Borthakur on Designing the Next Generation of Data Systems for Real-Time Analytics. We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! This ensures that queries access the latest, correct version of data.
Minerva takes fact and dimension tables as inputs, performs data denormalization, and serves the aggregateddata to downstream applications. For example, data scientists have built a time series analysis tool and an email reporting framework using this API over the last two years.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content