This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To improve the way they model and manage risk, institutions must modernize their data management and data governance practices. Implementing a modern dataarchitecture makes it possible for financial institutions to break down legacy data silos, simplifying data management, governance, and integration — and driving down costs.
Netflix writes an excellent article describing its approach to cloud efficiency, starting with data collection to questioning the business process. link] Adevinta: From Lakehouse architecture to data mesh One of DEW’s 2025 predictions is that we will see increased adoption of the data Mesh principles.
Uber leverages real-time analytics on aggregatedata to improve the user experience across our products, from fighting fraudulent behavior on Uber Eats to forecasting demand on our platform. .
Intermediate Data Transformation Techniques Data engineers often find themselves in the thick of transforming data into formats that are not only usable but also insightful. Intermediate data transformation techniques are where the magic truly begins.
I’ve gathered the best minds in tech who also believe in the importance of the work we’re doing, and are dedicated to serving the lives we’re impacting with this innovative approach to healthcare data. What’s the coolest thing you’re doing with data? What role does Snowflake play in your data strategy?
Rockset introduces a new architecture that enables separate virtual instances to isolate streaming ingestion from queries and one application from another. Benefits of Compute-Compute Separation In this new architecture, virtual instances contain the compute and memory needed for streaming ingest and queries.
As part of this change, we adopted a more modular app architecture (inspired by Uber’s Riblets ) in order to reduce the amount of sweeping changes. We had cut the lead time for most features almost in half by reducing the amount of code to write and unifying our architecture.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
Most AI apps and ML models need different types of data – real-time data from devices, equipment, and assets and traditional enterprise data – operational, customer, service records. . But it isn’t just aggregatingdata for models. Data needs to be prepared and analyzed.
Druid leverages the concept of segments , a unit of storage that allows for parallel querying and columnar storage, complemented with efficient compression and data retrieval. At Lyft, we used rollup as a data preprocessing technique which aggregates and reduces the granularity of data prior to being stored in segments.
For example, GDPR and HIPAA require strict access controls to protect sensitive data. Using Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) in LakeHouse architectures helps enforce this model. Access expands to data analysts and scientists, though sensitive elements should remain masked or anonymized.
It will help to detect an issue fast and solve it right before the end-users are affected by aggregatingdata on application behavior. These patterns will form a foundation for the construction of powerful cloud architectures, improving the resilience of your DevOps process and helping to increase efficiency.
In this post, we’ll share our journey in updating our front-end architecture and our learnings in introducing GraphQL into the Marketing Tech system. Secondly, we utilize various signals and aggregatedata such as understanding of content popularity on Netflix to enable highly relevant ads.
The sudden failing of a complex data pipeline can lead to devastating consequences — especially if it goes unnoticed. Architecture First, we would like to introduce the architecture of job notifications. In the figure below, you can see the architecture of a project from the perspective of job notifications.
The serving and monitoring infrastructure need to fit into your overall enterprise architecture and tool stack. Data scientists combining Python and Jupyter with scalable streaming architectures. Data scientists use tools like Jupyter Notebooks to analyze, transform, enrich, filter and process data.
In a previous blog post , we explored the architecture and challenges of the platform. However, consuming this raw data presents several pain points: The number of requests varies across models; some receive a large number of requests, while others receive only a few.
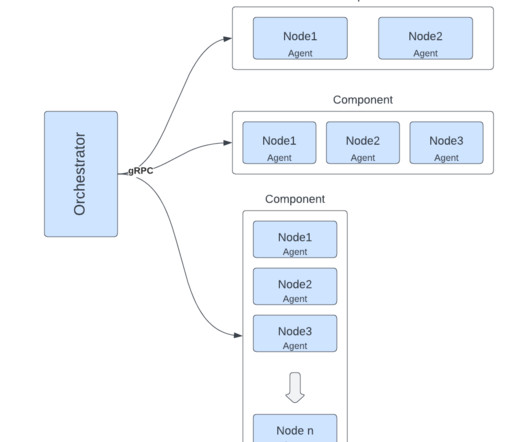
The historical upgrade system couldn’t adapt to architectural changes like the introduction of an observer namenode (Now handling a massive influx of read requests – 150K QPS – from services such as Trino ), ZKFC auto-failover, HDFS federation , etc. The orchestrator’s implementation of the upgrade procedure’s logic performs most of the work.
Furthermore, one cannot combine and aggregatedata from publicly available job boards into custom graphs or dashboards. The client needed to build its own internal data pipeline with enough flexibility to meet the business requirements for a job market analysis platform & dashboard.
Furthermore, one cannot combine and aggregatedata from publicly available job boards into custom graphs or dashboards. The client needed to build its own internal data pipeline with enough flexibility to meet the business requirements for a job market analysis platform & dashboard.
Gatekeeper accomplishes its prescribed task by aggregatingdata from multiple upstream systems, applying some business logic, then producing an output detailing the status of each video in each country. and we can do so with a higher level of safety than was possible in the previous architecture.
Instead, if you can “rollup” data as it is being generated, then you can define metrics that can be tracked in real time across a number of dimensions with better performance and lower cost. This greatly reduces both the amount of data stored and the compute for queries. Efficiency.
The reality is that data warehousing contains a large variety of queries both small and large; there are many circumstances where Impala queries small amounts of data; when end users are iterating on a use case, filtering down to a specific time window, working with dimension tables, or pre-aggregateddata.
Change data capture (CDC) streams from OLTP databases, which may provide sales, demographic or inventory data, are another valuable source of data for real-time analytics use cases. Architecture ClickHouse was developed, beginning in 2008, to handle web analytics use cases at Yandex in Russia. Flink, Kafka and MySQL.
The number of possible applications tends to grow due to the rise of IoT , Big Data analytics , streaming media, smart manufacturing, predictive maintenance , and other data-intensive technologies. Kafka architecture. But for high availability and data loss prevention, it’s recommended that you have at least three brokers.
Architecture and data modeling decisions can be challenging. We’ve gathered some of the questions most frequently asked: What is the best way to introduce a data mesh in an organization? How do you convince a potential domain owner to become a domain owner and be responsible for its data (products)?
Why Striim Stands Out As detailed in the GigaOm Radar Report, Striim’s unified data integration and streaming service platform excels due to its distributed, in-memory architecture that extensively utilizes SQL for essential operations such as transforming, filtering, enriching, and aggregatingdata.
Whether the data sits in Pandas DataFrames, Spark DataFrames, SQL databases, or cloud data warehouses, the GX flexible Batch processing architecture allows users to select which slices or subsets of processed data they want to evaluate.
Furthermore, Rockset’s ability to pre-aggregatedata at ingestion time reduced the cost of storage and sped up queries, making the solution cost-effective at scale. With Rockset’s flexible data model , the team could easily define new metrics, add new data and onboard customers without significant engineering resources.
The final solution architecture: Observability as a Code: Observability as Code is a critical part of our approach. Datadog aggregatesdata based on the specific “operations” they are associated with, such as acting as a server, client, RabbitMQ interaction, database query, or various methods.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
These steps guarantee that data is accurate, reliable, and meaningful by the time it reaches its destination, making it possible for teams to generate insights and make data-driven decisions. This architecture can vary based on the needs of the organization and the type of data being processed.
Data represents our present and our future, and therein lies a significant problem: the more data you’re dealing with, the more challenging it will be to scale your company in a sustainable and standardized way. It provides a more distributed, decentralized, and resilient approach to data management. So, what’s the solution?
Data represents our present and our future, and therein lies a significant problem: the more data you’re dealing with, the more challenging it will be to scale your company in a sustainable and standardized way. It provides a more distributed, decentralized, and resilient approach to data management. So, what’s the solution?
Data lakes can also be organized and queried using other technologies, such as . Atlas Data Lake powered by MongoDB. . Data Lake Architecture Diagram . The process of adding new data elements to a data warehouse involves changing the design, implementing, or refactoring structured storage for the data.
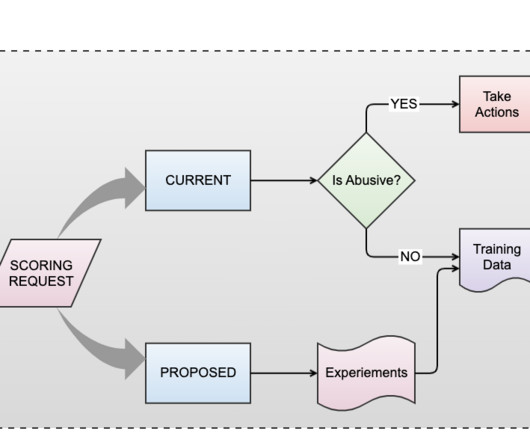
The feedback loop serves as a critical component of a dynamic defense strategy, constantly monitoring and aggregatingdata from abuse reports, member feedback, and reviewer input. By scrutinizing patterns with abuse data, we pinpoint emerging trends, allowing us to fine-tune our models and systems in real-time.
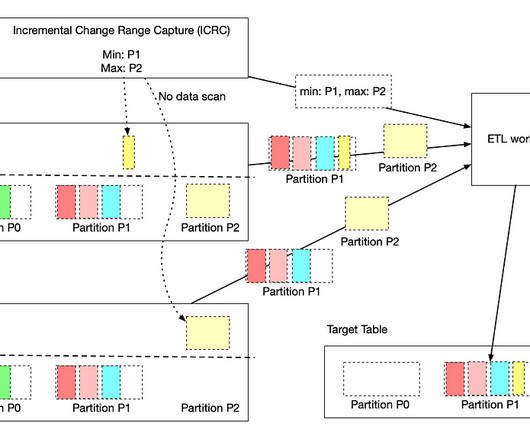
Instead of overwriting past X days of data completely by using a lookback window pattern, user workflows just need to MERGE the change data (including late arriving data) into the target table by processing the ICDC table.
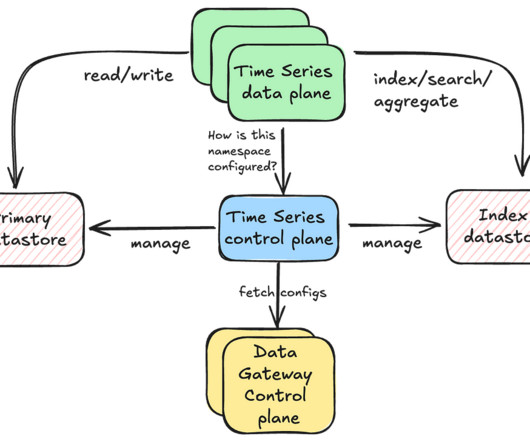
Understanding the Architecture No company is alike and no infrastructure will be alike. Although there are some guidelines that you can follow when setting up a data infrastructure, each company has it's own needs, processes and organizational structure. Data Sources: How different are your data sources?
The problem was architectural: The pipeline was doing too many things. We followed the microservice architecture in the new streaming pipeline design, and decided to split the pipelines into two (see Figure 2). The second type of pipeline ingests Kafka topics and aggregatesdata into standard ML features.
The lack of proper joins, immutable indexes that need constant vigil, a tightly coupled compute and storage architecture, and highly specific domain knowledge needed to develop and operate it has left many engineers seeking alternatives. We often see ingest queries aggregatedata by time.
Depending on a goal, it may take weeks or months to set up a data lake. Moreover, not all organizations use data lakes. Data mart vs data warehouse vs data lake architectures. Data marts shouldn’t be confused with OLAP cubes either. Data mart constructing.
She also says that they need more data related to fertility. They are very much anxious to know what the app might do and what they may be able to learn from the aggregateddata. Source: [link] Journey Analytics: A Killer App for Big Data? Glow has developed an app which allows to track the menstrual cycles.
Minerva takes fact and dimension tables as inputs, performs data denormalization, and serves the aggregateddata to downstream applications. This API serves a vital role in Airbnb’s next-generation data warehouse architecture. Data, Product Management, Finance, Engineering) and teams (e.g.,
Let us dive deeper into this data integration solution by AWS and understand how and why big data professionals leverage it in their data engineering projects. The ETL code for your data is automatically generated by AWS Glue when you specify your ETL process in the drag-and-drop job editor. How Does AWS Glue Work?
With the widespread adoption of microservices architectures, teams face greater challenges in achieving full observability for their systems and resolving issues promptly. Improved incident management: Observability platforms provide comprehensive visibility across all components in system architecture.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content