This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Uber leverages real-time analytics on aggregatedata to improve the user experience across our products, from fighting fraudulent behavior on Uber Eats to forecasting demand on our platform. .
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
For example, if your metric dashboard shows users experiencing higher latency as they scroll through their home feed, then that could be caused by anything from an OS upgrade, a logging or data pipeline error, an unusually large increase in user traffic, a code change landed recently, etc. The possible reasons go on andon.
This allows users to run continuous queries on data streams over specific time windows. You can also join multiple data streams and perform aggregations. This again liberates the value locked up in real-time data streams to more applications across the enterprise. Register NOW!
As a CDO, I need full data life cycle capability. I must store data efficiently and resiliently, pipe and aggregatedata into data lakehouses, and apply machine learning algorithms and AI to uncover actionable insights for our business units. The post Why I Prefer Cloudera CDP appeared first on Cloudera Blog.
In the previous blog post , we looked at some of the application development concepts for the Cloudera Operational Database (COD). In this blog post, we’ll see how you can use other CDP services with COD. Integrated across the Enterprise Data Lifecycle . Cloudera Data Engineering to ingest bulk data and data from mainframes.
In a previous blog post , we explored the architecture and challenges of the platform. In our previous blog , we discussed the various challenges we faced in model monitoring and our strategy to address some of these issues. We briefly discussed using z-scores to find anomalies.
Most AI apps and ML models need different types of data – real-time data from devices, equipment, and assets and traditional enterprise data – operational, customer, service records. . But it isn’t just aggregatingdata for models. Data needs to be prepared and analyzed.
To improve go-to-market (GTM) efficiency, Snowflake created a bi-directional data share with Outreach that provides consistent access to the current version of all our customer engagement data. In this blog, we’ll take a look at how Snowflake is using data sharing to benefit our SDR teams and marketing data analysts.
Pair this with Snowflake , the cloud data warehouse that acts as a vault for your insights, and you have a recipe for data-driven success. Get ready to explore the realm where data dreams become reality! In this blog, we will cover: What is Airbyte? With Airbyte and Snowflake, data integration is now a breeze.
This blog is the final post of a 4-part series. You can read the first blog posts, here: 1. This retailer deployed Cloudera DataFlow to tap real-time streaming data from thousands of cold storage sensors across its vast network of brick-and-mortar stores. Get to Know Your Retail Customer: 2.
Streamline KYC and AML, too While Know Your Customer (KYC) and Anti-Money-Laundering (AML) processes didn’t play a role in the recent collapses, institutions can also leverage the combination of a modern, open data architecture, advanced analytics, and machine automation to transform KYC and AML.
This is part of our series of blog posts on recent enhancements to Impala. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? It turns out that Apache Impala scales down with data just as well as it scales up. The entire collection is available here.
Secondly, we utilize various signals and aggregatedata such as understanding of content popularity on Netflix to enable highly relevant ads. Monet helps drive incremental conversions, engagement with our product and in general, present a rich story about our content and the Netflix brand to users around the world.
In this blog post, we talk about the landscape and the challenges in workflows at Netflix. Downstream workflows (if there is no business logic change) will be triggered by the data change due to backfill. This enables auto propagation of backfill data in multi-stage pipelines.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Our goal was to develop foundations that would enable the hundreds of ML developers at Lyft to efficiently develop new models and enhance existing models with streaming data. In this blog post, we will discuss what we built in support of that goal and some of the lessons we learned along the way.
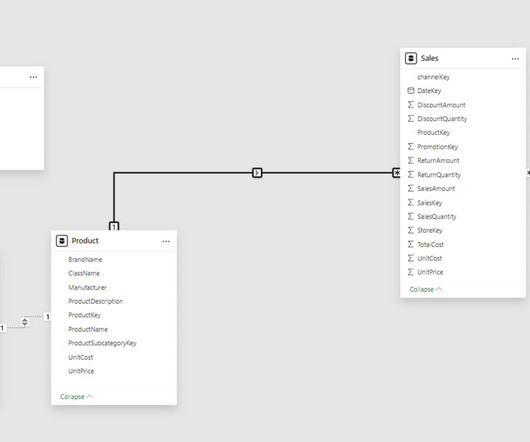
Use Case: 1: Cardinality is necessary for creating data models that aggregatedata, such as those used to monitor product sales, client interactions, or order histories. Many-to-many tables are appropriate when examining non-aggregation among them where no unique keys exist in both tables.
The sudden failing of a complex data pipeline can lead to devastating consequences — especially if it goes unnoticed. This is why we build job notifications functionality into SSB, to deliver maximum reliability in your complex real-time data pipelines.
Silver Layer: In this zone, data undergoes cleaning, transformation, and enrichment, becoming suitable for analytics and reporting. Access expands to data analysts and scientists, though sensitive elements should remain masked or anonymized. Grab’s blog on migrating from RBAC to ABAC is an excellent reference design.
The latter create integrated, higher-value data products that are geared towards requirements of the data consumers on the business side; for example, a customer 360 domain aggregatingdata from multiple sources. Some teams are data producers but not data consumers. It’s not just the data teams.
Types of data products In a previous blog post, I discussed different forms a data product can take using the sand, glass, or lamp metaphor , depending on the consumer of the data and the use case. Some data products will be components in a more complex analysis or context-specific business application.
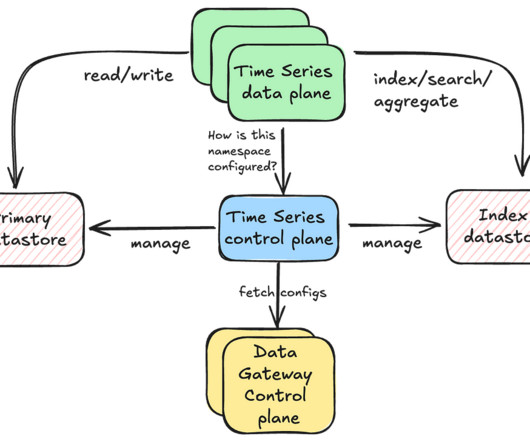
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
In this particular blog post, we explain how Druid has been used at Lyft and what led us to adopt ClickHouse for our sub-second analytic system. Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data.
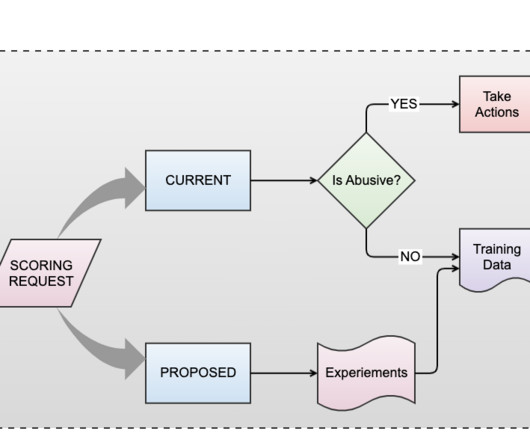
In this blog post, we discuss how we are harnessing AI to help us with abuse prevention and share an overview of our infrastructure and the role it plays in identifying and mitigating abusive behavior on our platform. Standing still in the realm of abuse prevention is synonymous with regression.
Faster issue diagnosis: Aggregatingdata from multiple sources enables engineers to correlate events more easily when troubleshooting problems, allowing them to resolve issues more quickly and prevent future occurrences through proactive measures such as capacity planning or automated remediation actions based on observed trends.
Building a full customer 360 requires aggregatingdata sets into a single view. You can also read about Cloudera Data Science and Engineering here. The post Machine Learning, the DOCOMO Digital way: Two Core Use Cases appeared first on Cloudera Blog. Driving customer insights with machine learning.
The latest Rockset release, SQL-based rollups, has made real-time analytics on streaming data a lot more affordable and accessible. Anyone who knows SQL, the lingua franca of analytics, can now rollup, transform, enrich and aggregate real-time data at massive scale. You can also optionally use WHERE clauses to filter out data.
This blog outlines best practices from customers I have helped migrate from Elasticsearch to Rockset , reducing risk and avoiding common pitfalls. In this blog, we distilled their migration journeys into 5 steps. We often see ingest queries aggregatedata by time.
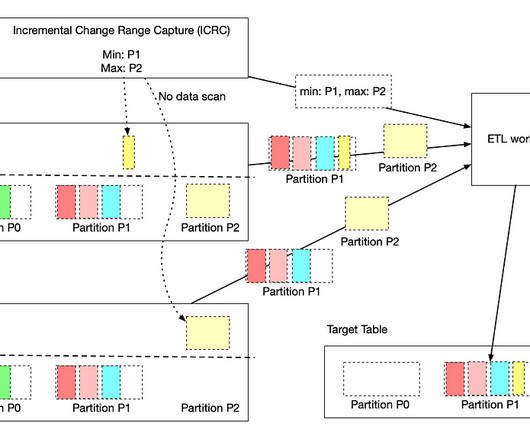
The version drift framework consolidates data from various sources, as shown in Figure 6, to create a comprehensive list of worker nodes currently running outdated versions. This framework operates on the scheduler, periodically polls relevant metrics, aggregatesdata, and determines which nodes have drifted.
Challenges of ad-hoc SQLs Our initial goal with Curie was to standardize the analysis methodologies and simplify the experiment analysis process for data scientists. Acknowledgements Special thanks to Sagar Akella, Bhawana Goel, and Ezra Berger for their invaluable help in reviewing this blog article.
One of the core features of ADF is the ability to preview your data while creating your data flows efficiently and to evaluate the outcome against a sample of data before completing and implementing your pipelines. Such features make Azure data flow a highly popular tool among data engineers.
My colleague Oliver Cronk has set out some of the principal risks in this blog post. In this blog post, I’ll provide an overview of how it worked. They can’t ask the bot to expose data on other customers or anything else outside of the Knowledge Graph’s purview. So, how do you mitigate the risks and harness the potential?
That’s where data enrichment comes into the picture. In this blog post, we’ll explain what data enrichment is, why you need it, how it works, and how B2B companies can use enriched data to drive results. What is data enrichment? How does data enrichment work?
In this blog post, we aim to share practical insights and techniques based on our real-world experience in developing data lake infrastructures for our clients - let's start! The Data Lake acts as the central repository for aggregatingdata from diverse sources in its raw format.
Azure Data Engineers are in high demand due to the growth of cloud-based data solutions. In this article, we will examine the duties of an Azure Data Engineer as well as the typical pay in this industry. Conclusion So this was all about the salary, job description, and skills of an Azure Data Engineer.
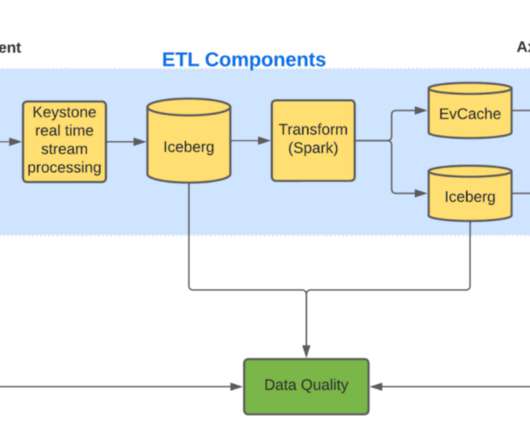
The Iceberg table created by Keystone contains large blobs of unstructured data. These large unstructured blogs are not efficient for querying, so we need to transform and store this data in a different format to allow efficient queries. Was data corrupted at rest? Compute applications follow daily trends.
As training data increases, deep learning requires scalability. Typically, data warehouses are set to read-only for analysts, who primarily read and aggregatedata. It is not necessary to insert or update data since it is already clean and archival. . Conclusion . .
It doesn't matter if you're a data expert or just starting out; knowing how to clean your data is a must-have skill. The future is all about big data. This blog is here to help you understand not only the basics but also the cool new ways and tools to make your data squeaky clean.
The main strategy to alleviate some of the pressure on the primary database is to offload some of the work to a secondary data store, and I will share some of the common patterns of this strategy in this blog series. In future articles I will discuss offloading to other types of systems.
Together, they empower developers to build performant internal tools, such as customer 360 and logistics monitoring apps, by solely using data APIs and pre-built UI components. In this blog, we’ll be building a customer 360 app using Rockset and Retool. From there, we’ll create a data API for the SQL query we write in Rockset.
AggregateData: If you don't need granularity, consider aggregatingdata before loading it into Power BI to reduce the volume of data. Sort and Filter Early: Apply sorting and filtering in your queries as early as possible to reduce the amount of data transferred and processed.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content