This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
If you've ever wished you could use the simplicity of SQL while working with large datasets in Pandas, PandaSQL is here to make your life easier. This blog will introduce you to PandaSQL , a Python library that helps you execute SQL queries directly on Pandas DataFrames.
With its intuitive data structures and vast array of functions, Pandas empowers data scientists to efficiently clean, transform, and explore datasets, making it an indispensable tool in their toolkit. Handling missing values: Missing values are a common occurrence in datasets. Is R or Python better for data wrangling?
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
Data professionals who work with raw data, like data engineers, data analysts, machine learning scientists , and machine learning engineers , also play a crucial role in any data science project. This project will help analyze user data for actionable insights.
One of the core features of ADF is the ability to preview your data while creating your data flows efficiently and to evaluate the outcome against a sample of data before completing and implementing your pipelines. Such features make Azure data flow a highly popular tool among data engineers.
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform raw data into actionable insights. In this blog, you’ll build a complete ETL pipeline in Python to perform data extraction from the Spotify API, followed by data manipulation and transformation for analysis.
The scripts demonstrate how to easily extract data from a source into Vantage with Airbyte, perform necessary transformations using dbt, and seamlessly orchestrate the entire pipeline with Dagster. These are the core of your project, where you write SQL to transform raw data into an analytics-friendly format.
Table of Contents 20 Open Source Big Data Projects To Contribute How to Contribute to Open Source Big Data Projects? 20 Open Source Big Data Projects To Contribute There are thousands of open-source projects in action today. This blog will walk through the most popular and fascinating open source big data projects.
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. Finally, you'll find a list of PySpark projects to help you gain hands-on experience and land an ideal job in Data Science or Big Data.
Learning Snowflake data Warehouse is like gaining a superpower for handling and analyzing data in the cloud. This blog is a definitive guide to mastering how to learn Snowflake data warehouse for all aspiring data engineers. That's exactly what Snowflake Data Warehouse enables you to do!
Become an ETL wizard and demystify the world of data transformation with our detailed blog on How to Learn ETL. So, if you are willing to build a successful big data career, this is the perfect ETL tutorial for you! Imagine an organization gathering heaps of data daily, like sales figures, customer data, and product inventory.
In a previous blog post , we explored the architecture and challenges of the platform. In our previous blog , we discussed the various challenges we faced in model monitoring and our strategy to address some of these issues. The profiles are very compact and efficiently describe the dataset with high fidelity.
It also provides an advanced materialized view engine to enable live aggregateddatasets to be accessible by other applications via a simple REST API. Data decays. Yes, data has a shelf life. This allows users to run continuous queries on data streams over specific time windows. Register NOW!
However, it might not be ideal for time series data because it requires importing all helper classes for the year, month, week, and day formatters. It's also inconvenient when dealing with several datasets, but converting a dataset into a long format and plotting it is simple. total size of data’).
This blog answers all your questions about how to learn AIOps- the latest marvel in the tech world that empowers organizations to thrive in an increasingly dynamic and competitive landscape of AI. AIOps analyzes extensive IT data in real time, offering actionable insights to detect and address issues before they escalate.
Are you struggling to adapt data analysis techniques? Look no further than Pandas Functions to streamline your efforts and advance your skills in data manipulation. This blog is a guided tour through the must-know Pandas functions that will empower you to manipulate, transform, and extract insights from your data like never before.
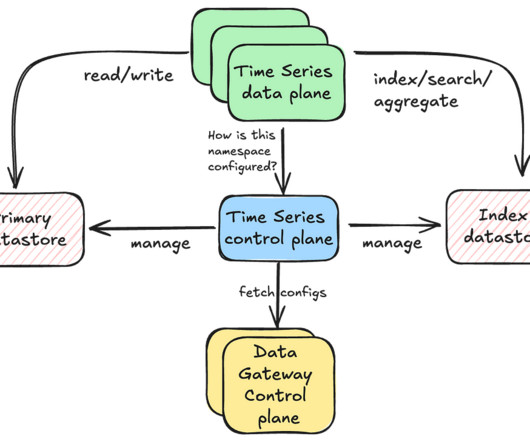
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
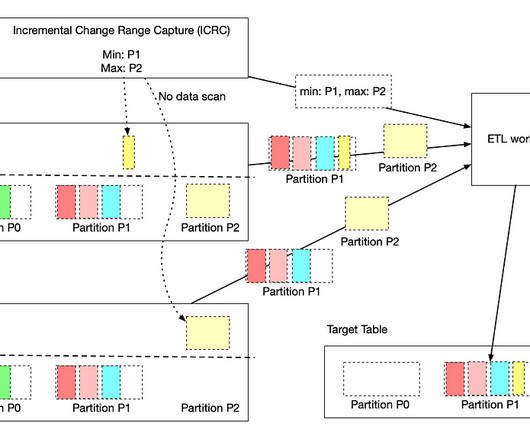
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
In the previous blog post , we looked at some of the application development concepts for the Cloudera Operational Database (COD). In this blog post, we’ll see how you can use other CDP services with COD. Integrated across the Enterprise Data Lifecycle . Cloudera Data Engineering to ingest bulk data and data from mainframes.
Are you passionate about data but lack experience as a data analyst? This comprehensive blog will show you how to become a data analyst with no experience, breaking down the process into simple steps and providing you with resources and tools to help you along the way. Filter, sort, and aggregatedata with ease.
This is part of our series of blog posts on recent enhancements to Impala. Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? It turns out that Apache Impala scales down with data just as well as it scales up. The entire collection is available here.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. A pipeline may include filtering, normalizing, and data consolidation to provide desired data.
Pair this with Snowflake , the cloud data warehouse that acts as a vault for your insights, and you have a recipe for data-driven success. Get ready to explore the realm where data dreams become reality! In this blog, we will cover: What is Airbyte? With Airbyte and Snowflake, data integration is now a breeze.
In this particular blog post, we explain how Druid has been used at Lyft and what led us to adopt ClickHouse for our sub-second analytic system. Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
It is also essential to practice with simple datasets initially, gradually advancing to more complex ones to create various visualizations, dashboards, and analyzes to hone your data skills. This integration enhances the depth and flexibility of data exploration, making complex data easier to understand and interpret.
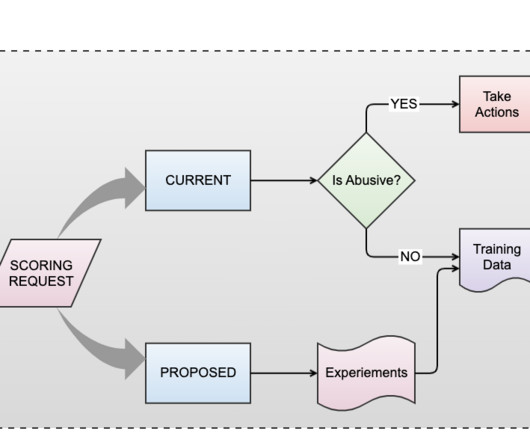
In this blog post, we discuss how we are harnessing AI to help us with abuse prevention and share an overview of our infrastructure and the role it plays in identifying and mitigating abusive behavior on our platform. At the core of inference at scale lies the fusion of ML with a wealth of data.
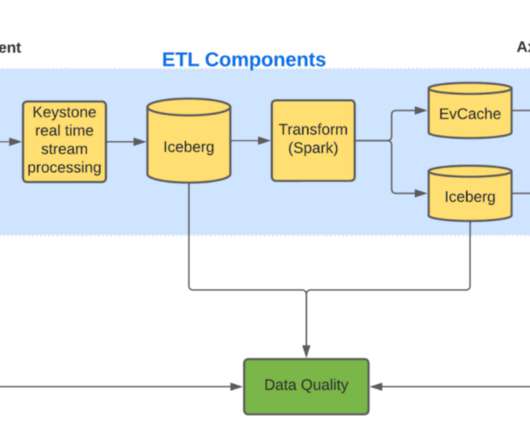
The Iceberg table created by Keystone contains large blobs of unstructured data. These large unstructured blogs are not efficient for querying, so we need to transform and store this data in a different format to allow efficient queries. As our label dataset was also random, presorting facts data also did not help.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
SQL provides a unified language for efficient interaction where data sources are diverse and complex. Despite the rise of NoSQL, SQL remains crucial for querying relational databases, data transformations, and data-driven decision-making.
It doesn't matter if you're a data expert or just starting out; knowing how to clean your data is a must-have skill. The future is all about big data. This blog is here to help you understand not only the basics but also the cool new ways and tools to make your data squeaky clean. What is Data Cleaning?
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry.
Challenges of ad-hoc SQLs Our initial goal with Curie was to standardize the analysis methodologies and simplify the experiment analysis process for data scientists. After considering the aforementioned factors and studying other existing metric frameworks, we decided to adopt standard BI data models.
As per Microsoft, “A Power BI report is a multi-perspective view of a dataset, with visuals representing different findings and insights from that dataset. ” Reports and dashboards are the two vital components of the Power BI platform, which are used to analyze and visualize data. Read Power BI blogs and articles.
One of the core features of ADF is the ability to preview your data while creating your data flows efficiently and to evaluate the outcome against a sample of data before completing and implementing your pipelines. Such features make Azure data flow a highly popular tool among data engineers.
While we have previously shared how we ingest data into our data warehouse and how to enable users to conduct their own analyses with contextual data , we have not yet discussed the middle layer: how to properly model and transform data into accurate, analysis-ready datasets. Our work hardly stopped there, however.
In this blog, we’ll explain how to use AI in project management more efficiently, the benefits it brings to the table, the top AI project management tools making waves, and some real-world examples on how AI is transforming project management. This leads to better planning, resource allocation, and risk management.
This blog outlines best practices from customers I have helped migrate from Elasticsearch to Rockset , reducing risk and avoiding common pitfalls. In this blog, we distilled their migration journeys into 5 steps. We often see ingest queries aggregatedata by time.
For more detailed information on data science team roles, check our video. An analytics engineer is a modern data team member that is responsible for modeling data to provide clean, accurate datasets so that different users within the company can work with them. Data modeling. What is an analytics engineer?
In this blog post, we aim to share practical insights and techniques based on our real-world experience in developing data lake infrastructures for our clients - let's start! The Data Lake acts as the central repository for aggregatingdata from diverse sources in its raw format.
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. Finally, you'll find a list of PySpark projects to help you gain hands-on experience and land an ideal job in Data Science or Big Data.
Using weights in regression allows efficient scaling of the algorithm, even when interacting with large datasets. With this approach, we don’t just perform the regression computation more efficiently, we also minimize any network transfer costs and latencies and can perform much of the aggregation to get the inputs on the data warehouse.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content