This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Kafka can continue the list of brand names that became generic terms for the entire type of technology. Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. What is Kafka? What Kafka is used for.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
In this particular blog post, we explain how Druid has been used at Lyft and what led us to adopt ClickHouse for our sub-second analytic system. Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data.
In the previous blog post , we looked at some of the application development concepts for the Cloudera Operational Database (COD). In this blog post, we’ll see how you can use other CDP services with COD. Integrated across the Enterprise Data Lifecycle . Cloudera Data Engineering to ingest bulk data and data from mainframes.
Apache Kafka is breaking barriers and eliminating the slow batch processing method that is used by Hadoop. This is just one of the reasons why Apache Kafka was developed in LinkedIn. Kafka was mainly developed to make working with Hadoop easier. This data is constantly changing, and is voluminous.
Our goal was to develop foundations that would enable the hundreds of ML developers at Lyft to efficiently develop new models and enhance existing models with streaming data. In this blog post, we will discuss what we built in support of that goal and some of the lessons we learned along the way.
The sudden failing of a complex data pipeline can lead to devastating consequences — especially if it goes unnoticed. This is why we build job notifications functionality into SSB, to deliver maximum reliability in your complex real-time data pipelines.
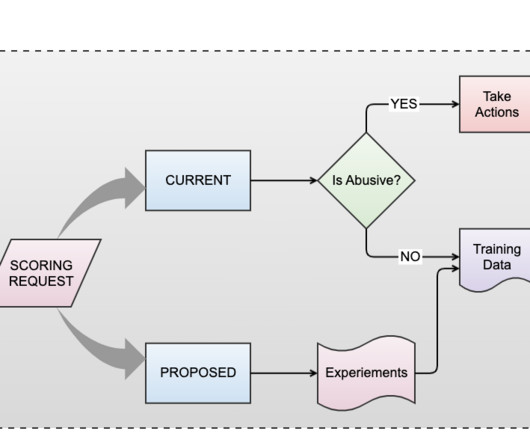
In this blog post, we discuss how we are harnessing AI to help us with abuse prevention and share an overview of our infrastructure and the role it plays in identifying and mitigating abusive behavior on our platform. To achieve this, we leverage Kafka messages, a robust and scalable event streaming platform.
Apache Kafka has made acquiring real-time data more mainstream, but only a small sliver are turning batch analytics, run nightly, into real-time analytical dashboards with alerts and automatic anomaly detection. But until this release, all these data sources involved indexing the incoming raw data on a record by record basis.
We use the RabbitMQ Source connector for Apache Kafka Connect. One may wonder why don’t we replace RabbitMQ with Apache Kafka everywhere? In order to answer the first question, we should take a closer look at the difference between RabbitMQ and Apache Kafka in terms of services parallelism.
We stream these events to Kafka and then store them in Snowflake. Users can query this data to troubleshoot their experiments. We then send this aggregateddata to another Kafka topic. Next, we had to save the data that is aggregated by the time-window into a datastore. For this we used Apache Pinot.
This framework operates on the scheduler, periodically polls relevant metrics, aggregatesdata, and determines which nodes have drifted. This process continuously sends metadata information to Kafka , including health reports and version data, among other details.
It produces high-quality signals and publishes them to Kafka topics. The second type of pipeline ingests Kafka topics and aggregatesdata into standard ML features. Get insights on how we overcame data skewness during our initial rollout. Learn more about various use cases of streaming at Lyft in this blog post.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. You can use big-data processing tools like Apache Spark , Kafka , and more to create such pipelines.
Here’s What You Need to Know About PySpark This blog will take you through the basics of PySpark, the PySpark architecture, and a few popular PySpark libraries , among other things. Finally, you'll find a list of PySpark projects to help you gain hands-on experience and land an ideal job in Data Science or Big Data.
This blog outlines best practices from customers I have helped migrate from Elasticsearch to Rockset , reducing risk and avoiding common pitfalls. In this blog, we distilled their migration journeys into 5 steps. We often see ingest queries aggregatedata by time.
Azure Data Engineers are in high demand due to the growth of cloud-based data solutions. In this article, we will examine the duties of an Azure Data Engineer as well as the typical pay in this industry. Data engineers frequently work in groups and should enjoy collaborating with other data engineers.
In this blog, we’ll describe how Klarna implemented real-time anomaly detection at scale, halved the resolution time and saved millions of dollars using Rockset. Furthermore, Rockset’s ability to pre-aggregatedata at ingestion time reduced the cost of storage and sped up queries, making the solution cost-effective at scale.
Data professionals who work with raw data like data engineers, data analysts, machine learning scientists , and machine learning engineers also play a crucial role in any data science project. And, out of these professions, this blog will discuss the data engineering job role. This is called Hot Path.
Rockset, on the other hand, provides full-featured SQL and an API endpoint interface that allows developers to quickly join across data sources like DynamoDB and Kafka. With the many data sources in today’s modern architecture, this can be difficult. From there, you can join and aggregatedata without using complex code.
Table of Contents 20 Open Source Big Data Projects To Contribute How to Contribute to Open Source Big Data Projects? 20 Open Source Big Data Projects To Contribute There are thousands of open-source projects in action today. This blog will walk through the most popular and fascinating open source big data projects.
There are many blog posts detailing how to build an Express API, I’ll concentrate on what is required on top of this to make calls to Elasticsearch. To experience how Rockset provides full-featured SQL queries on complex, semi-structured data, you can get started with a free Rockset account.
This blog is your one-stop solution for the top 100+ Data Engineer Interview Questions and Answers. In this blog, we have collated the frequently asked data engineer interview questions based on tools and technologies that are highly useful for a data engineer in the Big Data industry.
It offers a slick user interface for writing SQL queries to run against real-time data streams in Apache Kafka or Apache Flink. This enables developers, data analysts and data scientists to write streaming applications using just SQL. This allows users to run continuous queries on data streams over specific time windows.
This is the second post in a series by Rockset's CTO Dhruba Borthakur on Designing the Next Generation of Data Systems for Real-Time Analytics. We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! Many (Kafka, Spark and Flink) were open source.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content