

Data Engineering Weekly #210
Data Engineering Weekly
MARCH 2, 2025
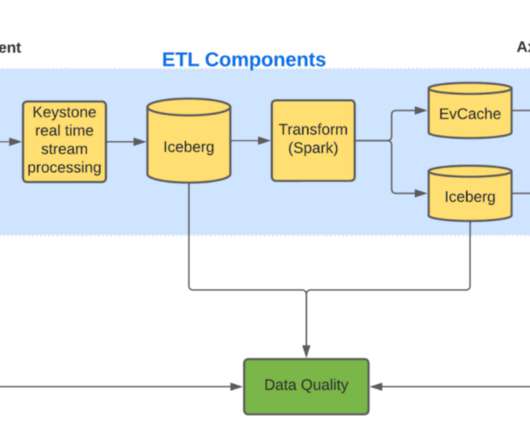
[link] Netflix: Cloud Efficiency at Netflix Data is the Key Optimization starts with collecting data and asking the right questions. Netflix writes an excellent article describing its approach to cloud efficiency, starting with data collection to questioning the business process.




































Let's personalize your content