This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. The industry relies more or less on S3 as a de facto data storage, and I found the experimentation on optimizing the S3 read optimization to be an excellent reference.
In the article, Bret Greenstein, data, analytics and AI partner at PwC identifies that, “No matter how organizations move toward scaling AI in the coming year, it’s important to understand the significant differences between using AI as a ‘proof of concept’ and scaling those efforts.” But it isn’t just aggregatingdata for models.
In the backend, we developed a real-time rule evaluation service that enables anyone in Picnic with some basic coding skills to create and modify rules that integrate with our systems landscape. Rule evaluations are triggered by events occurring in our systems (e.g. sending a push notification, changing an in-app configuration).
To explain Apache Kafka in a simple manner would be to compare it to a central nervous system than collectsdata from various sources. This data is constantly changing, and is voluminous. This data can be anything from clickstream data, activity/ web logs, consumer data, etc.
The process of gathering and compiling data from various sources is known as dataAggregation. Businesses and groups gather enormous amounts of data from a variety of sources, including social media, customer databases, transactional systems, and many more. This can be done manually or with a data cleansing tool.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. You need to think about the whole model lifecycle.
To ensure this availability we need to be able to see what our systems are doing at any point making the observability of our systems essential. Datadog aggregatesdata based on the specific “operations” they are associated with, such as acting as a server, client, RabbitMQ interaction, database query, or various methods.
Observability platforms gather, examine, and display telemetry data from various sources like logs, metrics, and trace data. By offering a comprehensive view of system performance and user experience, these platforms enable teams to proactively identify issues and enhance application performance.
Change Data Capture (CDC) plays a key role here by capturing and streaming only the changes (inserts, updates, deletes) in real time, ensuring efficient data handling and up-to-date information across systems. Why are Data Pipelines Significant? Now that we’ve answered the question, ‘What is a data pipeline?’
DataCollection and Integration: Data is gathered from various sources, including sensor and IoT data, transportation management systems, transactional systems, and external data sources such as economic indicators or traffic data. Here’s the process. The next phase is model development.
Traditionally, leads are scored based on how well they fit the company’s customer profile (demographic data) and their engagement (behavioral data). Traditional lead scoring is better than having no lead scoring, but it’s not a perfect system either. Key data points for predictive lead scoring. Data security.
They subsequently adjust the experiment’s start date so that it does not include metric datacollected prior to the bug fix. Supported internally at DoorDash, Flink is used by many teams to run their processing jobs on streaming data. We use Flink’s built-in time-window-based aggregation functions on exposure time.
This ensures that the datacollected and analyzed will provide meaningful insights into the areas of interest, such as productivity, quality, or customer satisfaction. Tools should be capable of automatically capturing the required data with minimal manual intervention to ensure consistency and accuracy.
ELT (Extract, Load, Transform) is a data integration technique that collects raw data from multiple sources and directly loads it into the target system, typically a cloud data warehouse. Extract The initial stage of the ELT process is the extraction of data from various source systems.
One was to create another data pipeline that would aggregatedata as it was ingested into DynamoDB. It also enabled us to run giveaways and contests for users who had complete set collections of NFTs in our system or spent X dollars in the marketplace. A Faster, Friendlier Solution We considered a few alternatives.
This article will define in simple terms what a data warehouse is, how it’s different from a database, fundamentals of how they work, and an overview of today’s most popular data warehouses. What is a data warehouse? An ETL tool or API-based batch processing/streaming is used to pump all of this data into a data warehouse.
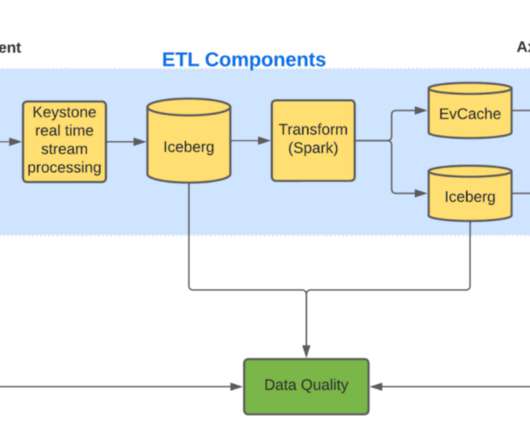
Since we train our models on several weeks of data, this method is slow for us as we will have to wait for several weeks for the datacollection. For Axion to become the defacto fact store for all Personalization ML models, the research teams needed to trust the quality of data stored. Was data corrupted at rest?
New Analytics Strategy vs. Existing Analytics Strategy Business Intelligence is concerned with aggregateddatacollected from various sources (like databases) and analyzed for insights about a business' performance. Ease of Operations BI systems make it easy for businesses to store, access and analyze data.
In summary, Python’s combination of simplicity, power, and extensive support makes it a compelling choice for data engineering. Whether an engineer is starting on a fresh project or integrating into existing systems, Python provides the tools and community to ensure success. csv') data_excel = pd.read_excel('data2.xlsx')
Users: Who are users that will interact with your data and what's their technical proficiency? Data Sources: How different are your data sources? Latency: What is the minimum expected latency between datacollection and analytics? And what is their format?
When it comes to adding value to data, there are many things you have to take into account — both inside and outside your company. For example, an enterprise might be using Amazon Web Services (AWS) as a cloud provider, and you want to store and query data from various systems.
From those home-made beginnings as Compass, Elasticsearch has matured into one of the leading enterprise search engines, standing among the top 10 most popular database management systems globally according to the Stack Overflow 2023 Developer Survey. Fluentd is a data collector and a lighter-weight alternative to Logstash.
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. Another reason to use PySpark is that it has the benefit of being able to scale to far more giant data sets compared to the Python Pandas library.
With the trending advance of IoT in every facet of life, technology has enabled us to handle a large amount of data ingested with high velocity. This big data project discusses IoT architecture with a sample use case. to accumulate data over a given period for better analysis.
Data Engineer Interview Questions on Big Data Any organization that relies on data must perform big data engineering to stand out from the crowd. But datacollection, storage, and large-scale data processing are only the first steps in the complex process of big data analysis.
From integrated eligibility programs and Medicaid enterprise systems to child welfare information systems and other human service program modernizations, money has been set aside to ensure federal, state and local governments are keeping up with the ever-changing tech landscape. IESs are the technological backbone for U.S.
Since this suggests that the impact of smart cities depends on the use of technology, it is crucial to prevent the misuse of digital tools and systems. These digital tools will allow them to: Effectively aggregatedata from various systems and organizations to support multi-functional analytic applications.
There are various kinds of hadoop projects that professionals can choose to work on which can be around datacollection and aggregation, data processing, data transformation or visualization. Learn to build a music recommendation system using Collaborative Filtering method. What is Data Engineering?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content