This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
Bring your raw Google Analytics data to Snowflake with just a few clicks The Snowflake Connector for Google Analytics makes it a breeze to get your Google Analytics data, either aggregateddata or raw data, into your Snowflake account. Here’s a quick guide to get started: 1. The connector changes that!
It also provides an advanced materialized view engine to enable live aggregateddatasets to be accessible by other applications via a simple REST API. Data decays. Yes, data has a shelf life. This allows users to run continuous queries on data streams over specific time windows.
In this article, we will be discussing 4 types of d ata Science Projects for resume that can strengthen your skills and enhance your resume: Data Cleaning Exploratory Data Analysis Data Visualization Machine Learning Data Cleaning A data scientist, most likely spend nearly 80% of their time cleaning data.
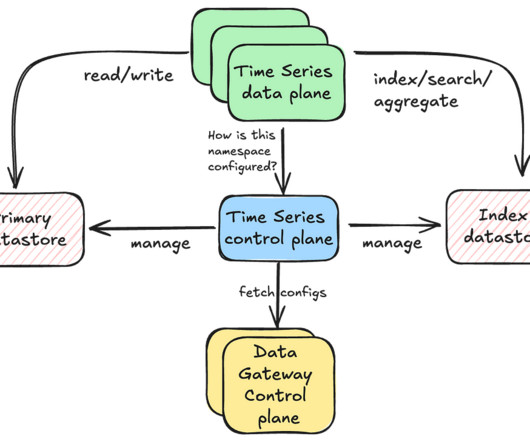
However, storing and querying such data presents a unique set of challenges: High Throughput : Managing up to 10 million writes per second while maintaining high availability. Configurability : TimeSeries offers a range of tunable options for each dataset, providing the flexibility needed to accommodate a wide array of use cases.
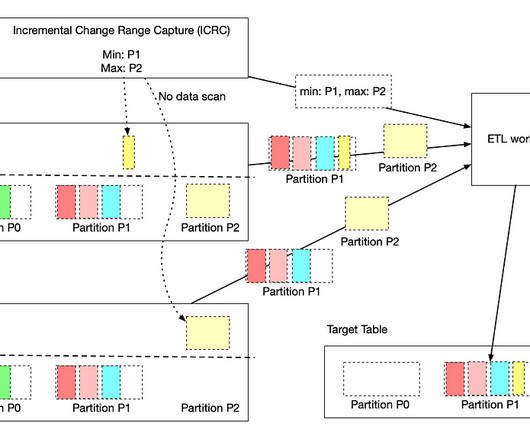
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
However, consuming this raw data presents several pain points: The number of requests varies across models; some receive a large number of requests, while others receive only a few. For some models, aggregatingdata with simple queries is easy, while for others the data is too large to process on a single machine.
Gatekeeper accomplishes its prescribed task by aggregatingdata from multiple upstream systems, applying some business logic, then producing an output detailing the status of each video in each country. High-Density : encoding, bit-packing, and deduplication techniques are employed to optimize the memory footprint of the dataset.
At Lyft, we used rollup as a data preprocessing technique which aggregates and reduces the granularity of data prior to being stored in segments. Pre-aggregatingdata at ingestion time helped optimize our query performance and reduce our storage costs. An example of how we use Druid rollup at Lyft.
Integrated across the Enterprise Data Lifecycle . Cloudera Operational Database (COD) plays the crucial role of a data store in the enterprise data lifecycle. You can use COD with: Cloudera DataFlow to ingest and aggregatedata from various sources. Cloudera Data Warehouse to perform ETL operations.
The process of merging and summarizing data from various sources in order to generate insightful conclusions is known as dataaggregation. The purpose of dataaggregation is to make it easier to analyze and interpret large amounts of data. Let's look at the use case of dataaggregation below.
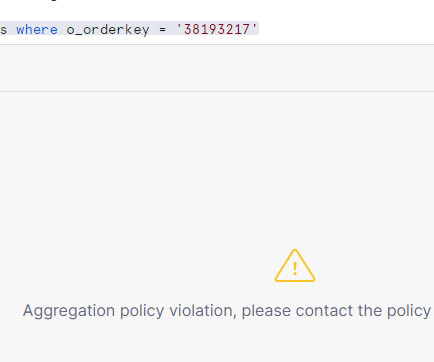
Data Privacy: Protecting the confidentiality of individual customer details and adhering to any relevant data privacy regulations. To address this concern, Cloudyard implements an aggregation policy on the shared transaction dataset.
Apache Impala is synonymous with high-performance processing of extremely large datasets, but what if our data isn’t huge? It turns out that Apache Impala scales down with data just as well as it scales up. So clearly Impala is used extensively with datasets both small and large. The entire collection is available here.
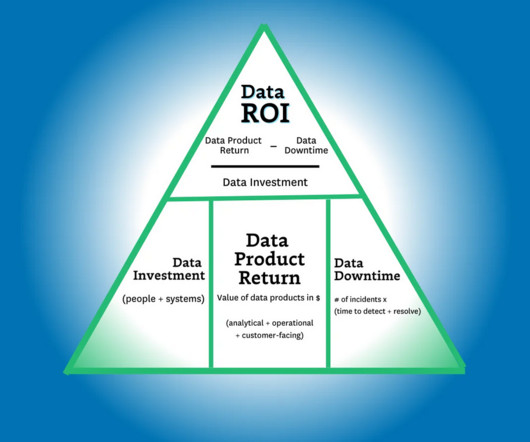
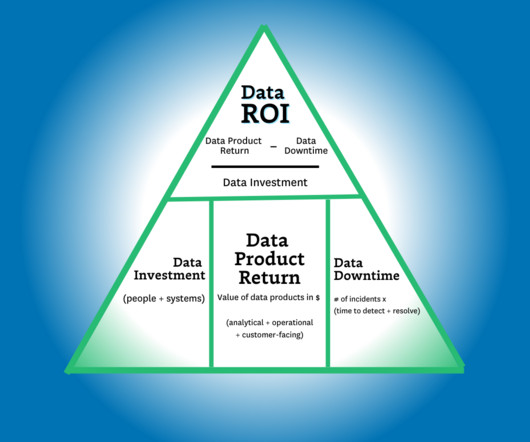
And while there’s certainly value in its simplicity, it doesn’t capture the full value of the data team. If the data systems went down, these activities would still happen, but they would be considerably more painful. But in this case, we aren’t as interested in the aggregatedata downtime or the efficiency of the team (yet).
Imagine you’re tasked with managing a critical data pipeline in Snowflake that processes and transforms large datasets. This pipeline consists of several sequential tasks: Task A: Loads raw data into a staging table. Task B: Transforms the data in the staging table.
View A broader view of data Narrower view of dataDataData is gleaned from diverse sources. Results Broader and exploratory results Targeted results Big Data vs Data Mining Here is a more detailed illustration of the difference between big data and data mining:- 1.
Similarly to rapid prototyping with these libraries, you can do interactive queries and data preprocessing with ksql-python. Check out the KSQL quick start and KSQL recipes to understand how to write a KSQL query to easily filter, transform, enrich or aggregatedata. The use case is fraud detection for credit card payments.
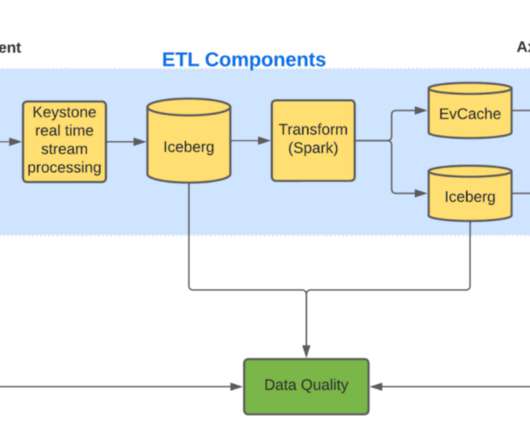
Each of these models are trained with different datasets and features along with different stratification and objectives. Given that Axion is used as the defacto Fact store for assembling the training dataset for all these models, it is important for Axion to log and store enough facts that would be sufficient for all these models.
Scale Existing Python Code with Ray Python is popular among data scientists and developers because it is user-friendly and offers extensive built-in data processing libraries. For analyzing huge datasets, they want to employ familiar Python primitive types. Then Redshift can be used as a data warehousing tool for this.
Rockset offers a number of benefits along with vector search support to create relevant experiences: Real-Time Data: Ingest and index incoming data in real-time with support for updates. Feature Generation: Transform and aggregatedata during the ingest process to generate complex features and reduce data storage volumes.
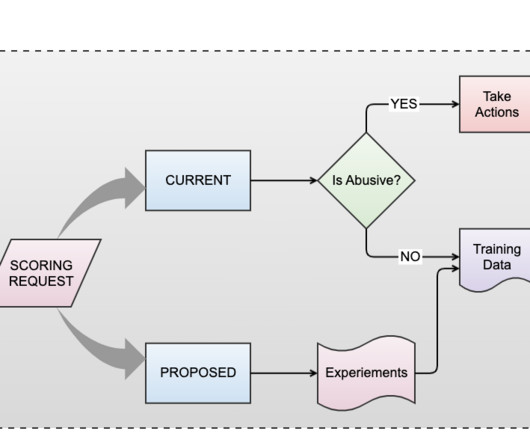
At the core of inference at scale lies the fusion of ML with a wealth of data. ML models, meticulously trained on diverse and high-quality datasets, are the linchpin of our Abuse detection efforts. By scrutinizing patterns with abuse data, we pinpoint emerging trends, allowing us to fine-tune our models and systems in real-time.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
Streamline Data Volume for Efficiency: While Snowflake is capable of handling large datasets, it’s essential to be mindful of data volume. Focus on sending relevant, necessary data to Snowflake to prevent overwhelming the integration process.
While we have previously shared how we ingest data into our data warehouse and how to enable users to conduct their own analyses with contextual data , we have not yet discussed the middle layer: how to properly model and transform data into accurate, analysis-ready datasets. Our work hardly stopped there, however.
Our campaign decision engine already relies on ML-trained algorithms, but they were built using a limited dataset due to the high cost of integrating disparate datasets. That’s not an issue with Rockset, which naturally aggregatesdata as it is ingested.
Google BigQuery BigQuery is famous for giving users access to public health datasets and geospatial data. It has connectors to retrieve data from Google Analytics and all other Google platforms. It also natively integrates with Apache Spark. It has its own notebooks, dataflow integrations, and spark job definitions.
High Performance Python is inherently efficient and robust, enabling data engineers to handle large datasets with ease: Speed & Reliability: At its core, Python is designed to handle large datasets swiftly , making it ideal for data-intensive tasks.
And while there’s certainly value in its simplicity, it doesn’t capture the full value of the data team. If the data systems went down, these activities would still happen, but they would be considerably more painful. But in this case, we aren’t as interested in the aggregatedata downtime or the efficiency of the team (yet).
As per Microsoft, “A Power BI report is a multi-perspective view of a dataset, with visuals representing different findings and insights from that dataset. ” Reports and dashboards are the two vital components of the Power BI platform, which are used to analyze and visualize data. Use descriptive names.
SPICE, an in-memory computation engine, is used to ensure rapid data analysis. SPICE is capable of handling large datasets, allowing for real-time analytics and interactive dashboards Power BI's DAX (Data Analysis Expressions) language prioritizes performance.
She also says that they need more data related to fertility. They are very much anxious to know what the app might do and what they may be able to learn from the aggregateddata. Source: [link] Journey Analytics: A Killer App for Big Data? Glow has developed an app which allows to track the menstrual cycles.
If you feel like you strike a match with predictive analytics, keep reading to learn a crucial part: what data the system will require to determine winning attributes. Key data points for predictive lead scoring. Let’s review all data points that can help the engine identify key attributes. Demographic data.
However, it might not be ideal for time series data because it requires importing all helper classes for the year, month, week, and day formatters. It's also inconvenient when dealing with several datasets, but converting a dataset into a long format and plotting it is simple. total size of data’).
The next step would be to transform it and load it into a data warehouse for further analysis. Azure Data Factory Dataflows can come in handy for this big data project for - Joining and aggregatingdata from diverse sources like social media, sales, and customer behavior data to build a single 360 degree of the customer.
For more detailed information on data science team roles, check our video. An analytics engineer is a modern data team member that is responsible for modeling data to provide clean, accurate datasets so that different users within the company can work with them. Data modeling. What is an analytics engineer?
This process can encompass a wide range of activities, each aiming to enhance the data’s usability and relevance. For example: AggregatingData: This includes summing up numerical values and applying mathematical functions to create summarized insights from the raw data.
Furthermore, PySpark allows you to interact with Resilient Distributed Datasets (RDDs) in Apache Spark and Python. Because of its interoperability, it is the best framework for processing large datasets. Easy Processing- PySpark enables us to process data rapidly, around 100 times quicker in memory and ten times faster on storage.
New Analytics Strategy vs. Existing Analytics Strategy Business Intelligence is concerned with aggregateddata collected from various sources (like databases) and analyzed for insights about a business' performance. BAs help companies make better decisions by identifying patterns and trends in existing data sets.
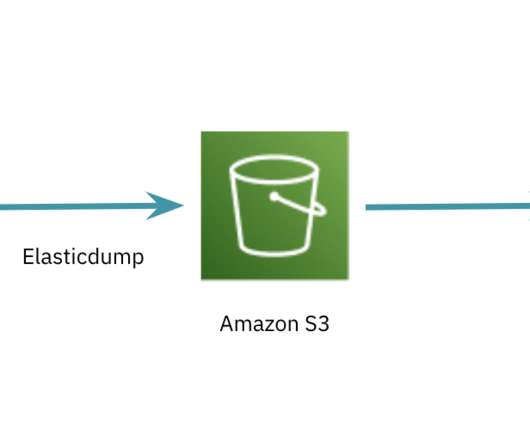
Here’s an example: SELECT NGRAMS(my_text_string, 1, 3) AS my_text_array, * FROM _input Aggregation It is common to pre-aggregatedata before it arrives into Elasticsearch for use cases involving metrics. We often see ingest queries aggregatedata by time.
Understanding SQL You must be able to write and optimize SQL queries because you will be dealing with enormous datasets as an Azure Data Engineer. To be an Azure Data Engineer, you must have a working knowledge of SQL (Structured Query Language), which is used to extract and manipulate data from relational databases.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
Data transformation includes normalizing data, encoding categorical variables, and aggregatingdata at the appropriate granularity. This step is pivotal in ensuring data consistency and relevance, essential for the accuracy of subsequent predictive models. The next phase is model development.
The lack of tracking for the quality and freshness of upstream datasets used in the metric definitions posed a risk of basing important business decisions on outdated or low-quality data. After considering the aforementioned factors and studying other existing metric frameworks, we decided to adopt standard BI data models.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content