This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This allows users to run continuous queries on data streams over specific time windows. You can also join multiple data streams and perform aggregations. This again liberates the value locked up in real-time data streams to more applications across the enterprise.
Streamline Data Volume for Efficiency: While Snowflake is capable of handling large datasets, it’s essential to be mindful of data volume. Focus on sending relevant, necessary data to Snowflake to prevent overwhelming the integration process. Adapt to Changing Data Schemas: Data sources aren’t static; they evolve.
Rockset offers a number of benefits along with vector search support to create relevant experiences: Real-Time Data: Ingest and index incoming data in real-time with support for updates. Feature Generation: Transform and aggregatedata during the ingest process to generate complex features and reduce data storage volumes.
Read our eBook TDWI Checklist Report: Best Practices for Data Integrity in Financial Services To learn more about driving meaningful transformation in the financial service industry, download our free ebook. As these organizations set out to implement game-changing technologies, challenges in data integrity require focused attention.
Similarly to rapid prototyping with these libraries, you can do interactive queries and data preprocessing with ksql-python. Check out the KSQL quick start and KSQL recipes to understand how to write a KSQL query to easily filter, transform, enrich or aggregatedata. Please try it out and let us know your thoughts.
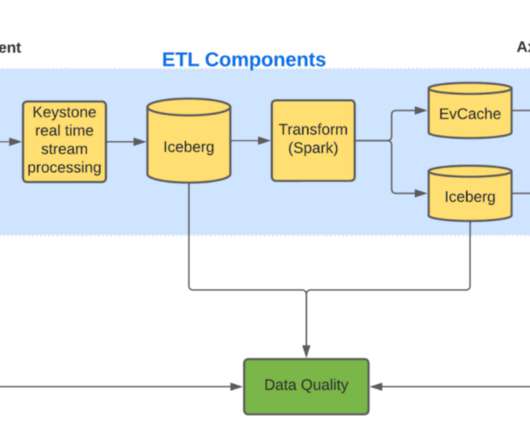
Even with bloom filters, the query performance was slow because the query was downloading all of the data from s3 and then dropping it. As our label dataset was also random, presorting facts data also did not help. We realized that our options with Iceberg were limited if we only needed data for a million rows?
When looking for a good participant for data cleaning projects, make certain that the data set: is spread across multiple files has a lot of nuances, null values, and cleaning approaches. These websites gather data from various sources without sorting it, making them excellent options for cleaning projects.
This enables systems using Kafka to aggregatedata from many sources and to make it consistent. Instead of interfering with each other, Kafka consumers create groups and split data among themselves. The section will help you set up the Kafka environment and begin to work with streams of data. Apache Kafka Quick Start.
How does data enrichment work? Explore the Precisely Data Guide to find the data you need to gain insight, drive growth, and minimize risk. Frequently asked questions about data enrichment: How is data enrichment useful for my business? Data enrichment can be useful in a variety of ways.
This includes such data points as: Minimum, maximum, and average amount of money spent. Sources : CRM, aggregateddata from card processors and other vendors. So-called implicit data, engagement information is collected from customers’ behavior and actions on your website. Number of downloads. Purchase frequency.
Your data may be efficiently organized, cleaned, improved, and reliably moved across different data stores and data streams with the help of AWS Glue. You can write code to migrate, transform, and aggregatedata from one source to another using the batch and streaming capabilities provided by AWS Glue ETL.
Kafka is extensively being used across industries for general – purpose messaging system where high availability and real time data integration and analytics are of utmost importance. Recommended Reading: Power BI vs Tableau - Find Your Perfect Match for a BI Tool Where is Kafka heading to?
Create a service account on GCP and download Google Cloud SDK(Software developer kit). Then, Python software and all other dependencies are downloaded and connected to the GCP account for other processes. to accumulate data over a given period for better analysis. Upload it to Azure Data lake storage manually.
Before putting raw data into tables or views, DLT gives users access to the full power of SQL or Python. Data transformation can take many forms, such as merging data from different data sets, aggregatingdata, sorting data, generating additional columns, changing data formats, or implementing validation procedures.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization European Soccer Game Analysis If you are a soccer fan and enjoy analyzing trends in sports teams, this project is for you. Dataset: Download this European Soccer Game Dataset from Kaggle.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content