This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Kafka can continue the list of brand names that became generic terms for the entire type of technology. Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. What is Kafka? What Kafka is used for.
This is what it is like to visualize the message throughput of Apache Kafka ®. Traditionally, making sense of the data flowing in a distributed event streaming platform is done by charts and graphs of aggregateddata. What if you wanted to see every message inside of Kafka? Pagination in Kafka for a UI.
This is what it is like to visualize the message throughput of Apache Kafka ®. Traditionally, making sense of the data flowing in a distributed event streaming platform is done by charts and graphs of aggregateddata. What if you wanted to see every message inside of Kafka? Pagination in Kafka for a UI.
Recently, I’ve been looking at what’s possible with streams of Wi-Fi packet capture (pcap) data. I was prompted after initially setting up my Raspberry Pi to capture pcap data and […].
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
It offers a slick user interface for writing SQL queries to run against real-time data streams in Apache Kafka or Apache Flink. This enables developers, data analysts and data scientists to write streaming applications using just SQL. This allows users to run continuous queries on data streams over specific time windows.
At Lyft, we used rollup as a data preprocessing technique which aggregates and reduces the granularity of data prior to being stored in segments. Pre-aggregatingdata at ingestion time helped optimize our query performance and reduce our storage costs. ioConfig: Kafka server info, topic names, etc. (ex.
Apache Kafka is breaking barriers and eliminating the slow batch processing method that is used by Hadoop. This is just one of the reasons why Apache Kafka was developed in LinkedIn. Kafka was mainly developed to make working with Hadoop easier. This data is constantly changing, and is voluminous.
Integrated across the Enterprise Data Lifecycle . Cloudera Operational Database (COD) plays the crucial role of a data store in the enterprise data lifecycle. You can use COD with: Cloudera DataFlow to ingest and aggregatedata from various sources. Cloudera Data Warehouse to perform ETL operations.
At the time of writing, a Mapping team is working to utilize theEvent Driven Decisions product to rebuild Lyft’s Traffic infrastructure by aggregatingdata per geohash and applying a model. Shortly after we built it, it was utilized by another pod within our team to build a Real-time Anomaly Detection product.
The sudden failing of a complex data pipeline can lead to devastating consequences — especially if it goes unnoticed. This is why we build job notifications functionality into SSB, to deliver maximum reliability in your complex real-time data pipelines.
Apache Kafka has made acquiring real-time data more mainstream, but only a small sliver are turning batch analytics, run nightly, into real-time analytical dashboards with alerts and automatic anomaly detection. But until this release, all these data sources involved indexing the incoming raw data on a record by record basis.
Gatekeeper accomplishes its prescribed task by aggregatingdata from multiple upstream systems, applying some business logic, then producing an output detailing the status of each video in each country. If a message from the Kafka topic contains the exact same data as already reflected in the Hollow dataset, no action is taken.
Why Striim Stands Out As detailed in the GigaOm Radar Report, Striim’s unified data integration and streaming service platform excels due to its distributed, in-memory architecture that extensively utilizes SQL for essential operations such as transforming, filtering, enriching, and aggregatingdata.
Streaming data feeds many real-time analytics applications, from logistics tracking to real-time personalization. Event streams, such as clickstreams, IoT data and other time series data, are common sources of data into these apps. The broad adoption of Apache Kafka has helped make these event streams more accessible.
Rockset offers a number of benefits along with vector search support to create relevant experiences: Real-Time Data: Ingest and index incoming data in real-time with support for updates. Feature Generation: Transform and aggregatedata during the ingest process to generate complex features and reduce data storage volumes.
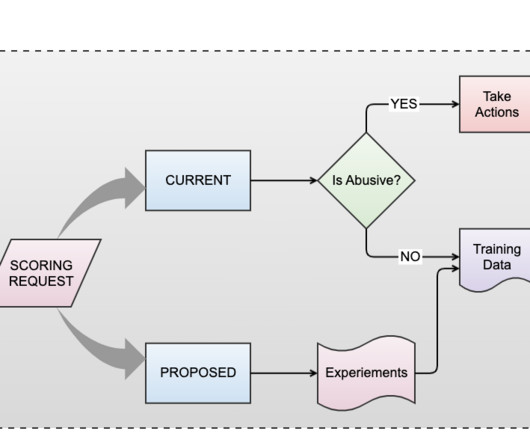
The feedback loop serves as a critical component of a dynamic defense strategy, constantly monitoring and aggregatingdata from abuse reports, member feedback, and reviewer input. By scrutinizing patterns with abuse data, we pinpoint emerging trends, allowing us to fine-tune our models and systems in real-time.
We stream these events to Kafka and then store them in Snowflake. Users can query this data to troubleshoot their experiments. We then send this aggregateddata to another Kafka topic. Next, we had to save the data that is aggregated by the time-window into a datastore. For this we used Apache Pinot.
In other words, you will write codes to carry out one step at a time and then feed the desired data into machine learning models for training sentimental analysis models or evaluating sentiments of reviews, depending on the use case. You can use big-data processing tools like Apache Spark , Kafka , and more to create such pipelines.
This framework operates on the scheduler, periodically polls relevant metrics, aggregatesdata, and determines which nodes have drifted. This process continuously sends metadata information to Kafka , including health reports and version data, among other details.
It produces high-quality signals and publishes them to Kafka topics. The second type of pipeline ingests Kafka topics and aggregatesdata into standard ML features. The first type of pipeline was mainly for event ingestion, filtration, hydration, and metadata tagging.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Step 1: Data Acquisition Elasticsearch is rarely the system of record which means the data in it comes from somewhere else for real-time analytics. Rockset has built-in connectors to stream real-time data for testing and simulating production workloads including Apache Kafka , Kinesis and Event Hubs.
Furthermore, Rockset’s ability to pre-aggregatedata at ingestion time reduced the cost of storage and sped up queries, making the solution cost-effective at scale. With Rockset’s flexible data model , the team could easily define new metrics, add new data and onboard customers without significant engineering resources.
This architecture shows that simulated sensor data is ingested from MQTT to Kafka. The data in Kafka is analyzed with Spark Streaming API, and the data is stored in a column store called HBase. Finally, the data is published and visualized on a Java-based custom Dashboard. This is called Hot Path.
Additionally, this modularity can help prevent vendor lock-in, giving organizations more flexibility and control over their data stack. Many components of a modern data stack (such as Apache Airflow, Kafka, Spark, and others) are open-source and free. Offered as open-source with active support by communities.
To supervise real-time business metric aggregation, data warehousing and querying, schema and data management, and related duties, familiarity with the computer coding languages python, java, Kafka, hive, or storm may be required.
Use Case: Storing data with PostgreSQL (example) import psycopg2 conn = psycopg2.connect(dbname="mydb", Tailored libraries like PySpark Streaming and Kafka-Python have made real-time data analysis and event processing a streamlined affair in Python. csv') data_excel = pd.read_excel('data2.xlsx')
It was built from the ground up for interactive analytics and can scale to the size of Facebook while approaching the speed of commercial data warehouses. Presto allows you to query data stored in Hive, Cassandra, relational databases, and even bespoke data storage. CMAK is developed to help the Kafka community.
Rockset, on the other hand, provides full-featured SQL and an API endpoint interface that allows developers to quickly join across data sources like DynamoDB and Kafka. With the many data sources in today’s modern architecture, this can be difficult. From there, you can join and aggregatedata without using complex code.
To be an Azure Data Engineer, you must have a working knowledge of SQL (Structured Query Language), which is used to extract and manipulate data from relational databases. You should be able to create intricate queries that use subqueries, join numerous tables, and aggregatedata.
Resource intensive tool While Elasticsearch excels in speed and performance, it’s important to note that it can be CPU-intensive, especially when handling multiple tasks like indexing, searching, and aggregatingdata concurrently. Framework Programming The Good and the Bad of Node.js
This likely requires you to aggregatedata from your ERP system, your supply chain system, potentially third-party vendors, and data around your internal business structure. Once the data has been collected from each system, a data engineer can determine how to optimally join the data sets.
By using Rockset, we may have to Tokenize our search fields on ingestion however we make up for it in firstly, the simplicity of processing this data on ingestion as well as easier querying, joining, and aggregatingdata. Read more about how Rockset compares to Elasticsearch and explore how to migrate to Rockset.
Further, data is king, and users want to be able to slice and dice aggregateddata as needed to find insights. Users don't want to wait for data engineers to provision new indexes or build new ETL chains. They want unfettered access to the freshest data available.
It involves creating a visual representation of an entire system of data or a part of it. The process of data modeling begins with stakeholders providing business requirements to the data engineering team. Data warehouse Operational database Data warehouses generally support high-volume analytical data processing - OLAP.
We use the RabbitMQ Source connector for Apache Kafka Connect. One may wonder why don’t we replace RabbitMQ with Apache Kafka everywhere? In order to answer the first question, we should take a closer look at the difference between RabbitMQ and Apache Kafka in terms of services parallelism.
Explosion in Streaming Data Before Kafka, Spark and Flink, streaming came in two flavors: Business Event Processing (BEP) and Complex Event Processing (CEP). Many (Kafka, Spark and Flink) were open source. Rockset not only continuously ingests data, but also can “rollup” the data as it is being generated.
There are various kinds of hadoop projects that professionals can choose to work on which can be around data collection and aggregation, data processing, data transformation or visualization. You will be introduced to exciting Big Data Tools like AWS, Kafka, NiFi, HDFS, PySpark, and Tableau.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content