This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of merging and summarizing data from various sources in order to generate insightful conclusions is known as dataaggregation. The purpose of dataaggregation is to make it easier to analyze and interpret large amounts of data. BigQuery is scalable and can handle large volumes of data.
Flink, Kafka and MySQL. As real-time analytics databases, Rockset and ClickHouse are built for low-latency analytics on large data sets. They possess distributed architectures that allow for scalability to handle performance or data volume requirements. ClickHouse has several storage engines that can pre-aggregatedata.
A Quick Primer on Indexing in Rockset Rockset allows users to connect real-time data sources — data streams (Kafka, Kinesis), OLTP databases (DynamoDB, MongoDB, MySQL, PostgreSQL) and also data lakes (S3, GCS) — using built-in connectors. You can also optionally use WHERE clauses to filter out data.
This serverless data integration service can automatically and quickly discover structured or unstructured enterprise data when stored in data lakes in Amazon S3, data warehouses in Amazon Redshift, and other databases that are a component of the Amazon Relational Database Service.
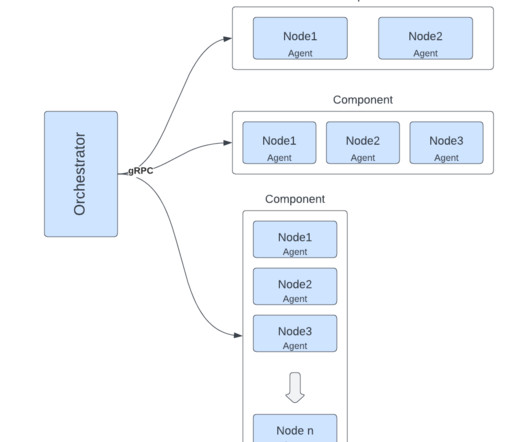
The version drift framework consolidates data from various sources, as shown in Figure 6, to create a comprehensive list of worker nodes currently running outdated versions. This framework operates on the scheduler, periodically polls relevant metrics, aggregatesdata, and determines which nodes have drifted.
Skills acquired : Relational database concepts Retrieving data using the SQL SELECT statement. Sorting and restricting data. Using Conditional Expressions and Conversion functions Reporting AggregatedData Using Group Functions Displaying data taken from multiple tables. Oracle Certified Professional, MySQL 8.0
Examples of relational databases include MySQL or Microsoft SQL Server. Data lakes: These are large-scale data storage systems that are designed to store and process large amounts of raw, unstructured data. Examples of technologies able to aggregatedata in data lake format include Amazon S3 or Azure Data Lake.
The benefit of these tools is that they’re built specifically for data analytics. They support joins and their column orientation allows you to quickly and effectively carry out aggregations. Data warehouses scale well and are well-suited to BI and advanced analytics use cases.
ETL processes often involve aggregatingdata from various sources into a data warehouse or data lake. Bucketing can be used during the transformation phase to aggregatedata into predefined buckets or intervals. It plays a […]
This enables systems using Kafka to aggregatedata from many sources and to make it consistent. Instead of interfering with each other, Kafka consumers create groups and split data among themselves. cloud data warehouses — for example, Snowflake , Google BigQuery, and Amazon Redshift.
Apache Sqoop (SQL-to-Hadoop) is a lifesaver for anyone who is experiencing difficulties in moving data from the data warehouse into the Hadoop environment. Apache Sqoop is an effective hadoop tool used for importing data from RDBMS’s like MySQL, Oracle, etc. into HBase, Hive or HDFS.
Use Case: Transforming monthly sales data to weekly averages import dask.dataframe as dd data = dd.read_csv('large_dataset.csv') mean_values = data.groupby('category').mean().compute() compute() Data Storage Python extends its mastery to data storage, boasting smooth integrations with both SQL and NoSQL databases.
Your data systems will also need to take advantage of indexing in order to improve performance. Row Indexing Most standard databases, like Postgres, MySQL or SQL Server, store data in row formats. When you query in these databases, your response is an entire row of data.
Source Code: Visualize Daily Wikipedia Trends with Hive, Zeppelin, and Airflow (projectpro.io) 7) DataAggregationDataAggregation refers to collecting data from multiple sources and drawing insightful conclusions from it. to accumulate data over a given period for better analysis.
Talend Real-Time Project for ETL Process Automation This Talend big data project will teach you how to create an ETL pipeline in Talend Open Studio and automate file loading and processing. You must first create a connection to the MySQL database to use Talend to extract data.
Further, data is king, and users want to be able to slice and dice aggregateddata as needed to find insights. Users don't want to wait for data engineers to provision new indexes or build new ETL chains. They want unfettered access to the freshest data available.
Non-relational databases are ideal if you need flexibility for storing the data since you cannot create documents without having a fixed schema. E.g. PostgreSQL, MySQL, Oracle, Microsoft SQL Server. E.g. Redis, MongoDB, Cassandra, HBase , Neo4j, CouchDB What is data modeling? Hadoop is a user-friendly open source framework.
The issue is how the downstream database stores updates and late-arriving data. Traditional transactional databases, such as Oracle or MySQL, were designed with the assumption that data would need to be continuously updated to maintain accuracy. That is called at-least-once semantics.
The project will guide you in performing data analysis with the help of group-by and exit command. It will also teach you about filtering aggregateddata. Check fares before booking, and also check their bookings. Check the available trains, etc. You will also learn about the inline view and accumulating values in a single row.
There are various kinds of hadoop projects that professionals can choose to work on which can be around data collection and aggregation, data processing, data transformation or visualization. Followed by MySQL is the Microsoft SQL Server. Transferring the data from MySQL to HDFS.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content