This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Volume refers to the amount of data being ingested; Velocity refers to the speed of arrival of data in the pipeline; Variety refers to different types of data, such as structured and unstructureddata. Why do you need a Data Ingestion Layer in a Data Engineering Project? application logs).
Both services support structured and unstructureddata. Both platforms are designed for data transformation and preparation. Both services are capable of cleaning, transforming, and aggregatingdata. Both services allow you to focus on business logic and data transformation.
Sqoop in Hadoop is mostly used to extract structured data from databases like Teradata, Oracle, etc., and Flume in Hadoop is used to sources data which is stored in various sources like and deals mostly with unstructureddata. The complexity of the big data system increases with each data source.
Create The Connector for Source Database The first step is having the source database, which can be any S3, Aurora, and RDS that can hold structured and unstructureddata. Glue works absolutely fine with structured as well as unstructureddata.
Their role involves data extraction from multiple databases, APIs, and third-party platforms, transforming it to ensure data quality, integrity, and consistency, and then loading it into centralized data storage systems. Clean, reformat, and aggregatedata to ensure consistency and readiness for analysis.
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. Step 2- Internal Data transformation at LakeHouse.
Relational Database Management Systems (RDBMS) Non-relational Database Management Systems Relational Databases primarily work with structured data using SQL (Structured Query Language). SQL works on data arranged in a predefined schema. Non-relational databases support dynamic schema for unstructureddata.
This can include tasks like data validation, data type conversion, deduplication, and aggregatingdata from different sources. Data Loading: The transformed data is loaded into a data warehouse or data lake, depending on the architecture of your data ecosystem.
Non-Relational Databases or NoSQL Databases Non-relational or NoSQL databases offer a flexible alternative to traditional relational databases, accommodating diverse data types and volumes. Their schema-less nature simplifies storage but requires careful data modeling for effective querying.
In the big data industry, Hadoop has emerged as a popular framework for processing and analyzing large datasets, with its ability to handle massive amounts of structured and unstructureddata. With Hadoop and Pig platform one can achieve next-level extraction and interpretation of such complex unstructureddata.
Use Cloud SQL to store the collected data and build dashboards that allow analysts to track KPIs in real-time. Build a data warehouse that aggregatesdata from multiple sources such as transactional databases and third-party APIs.
Domain Algorithms Domain algorithms in AIOps intelligently comprehend rules and patterns extracted from data sources. Dive into topics such as data collection, aggregation, data analysis , and data visualization.
Topic modelling finds applications in organization of large blocks of textual data, information retrieval from unstructureddata and for data clustering. For e-commerce websites, data scientists often use topic modelling to group customer reviews and identify common issues faced by consumers.
AI-powered project estimation tools first ingest structured and unstructureddata, from past project outcomes and resource allocations to task completion trends. Microsoft Project uses AI through Copilot to automate project status reporting based on key performance indicators (KPIs), work progress, and historical data.
Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data. Comprehending and understanding how to leverage unstructureddata has remained challenging and costly, requiring technical depth and domain expertise.
Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. The data lakes store data from a wide variety of sources, including IoT devices, real-time social media streams, user data, and web application transactions.
Data can be loaded using a loading wizard, cloud storage like S3, programmatically via REST API, third-party integrators like Hevo, Fivetran, etc. Data can be loaded in batches or can be streamed in near real-time. Structured, semi-structured, and unstructureddata can be loaded.
Here are a couple of resources to learn more: Data Talks Club Data Ingestion Week Coder2J Airflow Tutorial Data Storage In the context of data engineering, data storage refers to the systems and technologies that are used to store and manage data within an organization.
Create The Connector for Source Database The first step is having the source database, which can be any S3, Aurora, and RDS that can hold structured and unstructureddata. Glue works absolutely fine with structured as well as unstructureddata.
It concentrates on structured data within predefined parameters or hypotheses to find specific patterns or relationships. Data Big DataData Mining Big data is related to sizable and complex datasets that include structured, semi-structured, and unstructureddata from a variety of sources.
Additionally, legacy systems frequently struggle with diverse data types, such as structured, semi-structured, and unstructureddata. Contemporary pipelines simplify data management by supporting a wide array of data formats and automating many processes.
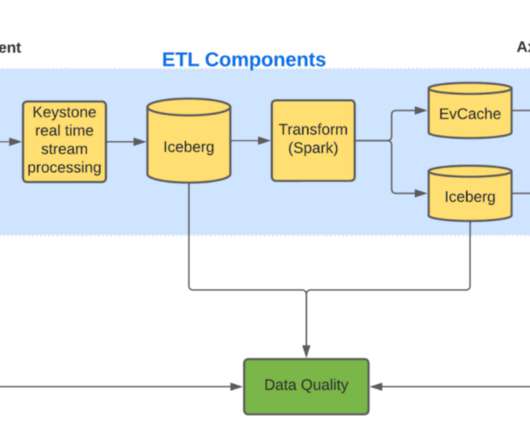
The Iceberg table created by Keystone contains large blobs of unstructureddata. These large unstructured blogs are not efficient for querying, so we need to transform and store this data in a different format to allow efficient queries. Was data corrupted at rest? Compute applications follow daily trends.
Both services support structured and unstructureddata. Both platforms are designed for data transformation and preparation. Both services are capable of cleaning, transforming, and aggregatingdata. Both services allow you to focus on business logic and data transformation.
Sqoop in Hadoop is mostly used to extract structured data from databases like Teradata, Oracle, etc., and Flume in Hadoop is used to sources data which is stored in various sources like and deals mostly with unstructureddata. The complexity of the big data system increases with each data source.
Encoding categorical variables, scaling numerical features, creating new features, aggregatingdata. One-hot encoding categorical variables, standardizing numerical features, aggregatingdata. Best Data cleaning tools and software Data cleaning is a crucial step in data preparation, ensuring data accuracy and reliability.
Extract The initial stage of the ELT process is the extraction of data from various source systems. This phase involves collecting raw data from the sources, which can range from structured data in SQL or NoSQL servers, CRM and ERP systems, to unstructureddata from text files, emails, and web pages.
We've seen this happen in dozens of our customers: data lakes serve as catalysts that empower analytical capabilities. If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructureddata on their models or analysis. And what is the reason for that?
They typically contain structured data and take less time for setup — normally 3 to 6 months for on-premise solutions. A data lake is a central repository used to store massive amounts of both structured and unstructureddata coming from a great variety of sources.
This is because the target system can perform data transformation and loading in parallel, which speeds up the process. A project requires large amounts of both structured and unstructureddata , such as data generated by sensors, GPS trackers, and video recorders. Aggregation.
Once big data is loaded into Hadoop, what is the best way to use this data? Collecting huge amounts of unstructureddata does not help unless there is an effective way to draw meaningful insights from it. Hadoop Developers have to filter and aggregate the data to leverage it for business analytics.
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. Step 2- Internal Data transformation at LakeHouse.
Relational Database Management Systems (RDBMS) Non-relational Database Management Systems Relational Databases primarily work with structured data using SQL (Structured Query Language). SQL works on data arranged in a predefined schema. Non-relational databases support dynamic schema for unstructureddata.
To achieve this, combine data from the sum of your sources. For this purpose, you can use ETL (extract, transform, and load) tools or build a custom data pipeline of your own and send the aggregateddata to a target system, such as a data warehouse.
These indices are specially designed data structures that map out the data for rapid searches, allowing for the retrieval of queries in milliseconds. As a result, Elasticsearch is exceptionally efficient in managing structured and unstructureddata.
This is an entry-level database certification, and it is a stepping stone for other role-based data-focused certifications, like Azure Data Engineer Associate, Azure Database Administrator Associate, Azure Developer Associate, or Power BI Data Analyst Associate. Skills acquired : Core data concepts. Data storage options.
This likely requires you to aggregatedata from your ERP system, your supply chain system, potentially third-party vendors, and data around your internal business structure. This is where data science comes into the picture. What is Data Modeling?
ETL is meant for extracting, transforming, and aggregatingdata. ETL is the first step in data warehousing. The data warehouse takes a long time to generate cross-tab reports from source tables. Data processing ETL loads data into the staging server and then to the target system.
Thus, as a learner, your goal should be to work on projects that help you explore structured and unstructureddata in different formats. Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content