This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Shopping Experience Enhancement Expanding the dynamic header system to other Pinterest surfaces Developing new shopping-specific modules Further optimizing the gift discovery algorithm 3. Gift-Specific Filtering: A post-ranking filter removes utilitarian products while elevating items with strong giftsignals.
It means your company has automated the processes of collecting, understanding and acting on data across the board, from production to purchasing to product development to understanding customer priorities and preferences. Datacollection and interpretation when purchasing products and services can make a big difference.
Without them, datacollected by IoT sensors, cameras and other devices would have to travel to a data center located hundreds or thousands of miles away. In such a scenario, data latency is essentially unavoidable — and, when real-time action is required, inadmissible. Real-time Demands.
To use such tools effectively, though, government organizations need a consolidated data platform–an infrastructure that enables the seamless ingestion and integration of widely varied data, across disparate systems, at speed and scale. Analyzing historical data is an important strategy for anomaly detection.
In this blog, we’ll look at how DeepBrain AI is altering industries, increasing creativity, and opening up new possibilities in human-machine connection. DeepBrain AI is driven by powerful machine learning algorithms and natural language processing. Let’s plunge in! This is where DeepBrain AI comes in.
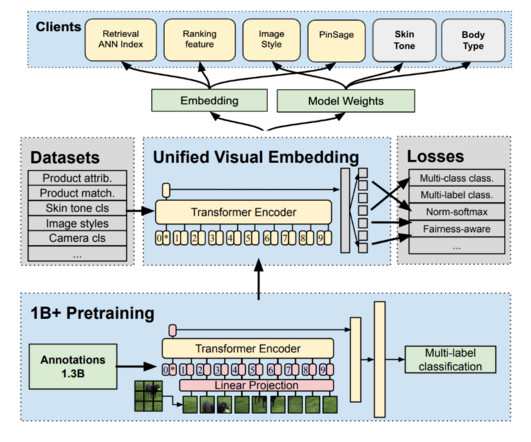
These teams work together to ensure algorithmic fairness, inclusive design, and representation are an integral part of our platform and product experience. Signal Development and Indexing The process of developing our visual body type signal essentially begins with datacollection.
The goal is to define, implement and offer a data lifecycle platform enabling and optimizing future connected and autonomous vehicle systems that would train connected vehicle AI/ML models faster with higher accuracy and delivering a lower cost. This author is passionate about industry 4.0,
We can think of model lineage as the specific combination of data and transformations on that data that create a model. This maps to the datacollection, data engineering, model tuning and model training stages of the data science lifecycle. So, we have workspaces, projects and sessions in that order.
A database is a structured datacollection that is stored and accessed electronically. According to a database model, the organization of data is known as database design. Blogs KDnuggets: It is one of the compelling and regularly updated sites for blogs on analytics, Data Science, Big Data and machine learning.
Let’s study them further below: Machine learning : Tools for machine learning are algorithmic uses of artificial intelligence that enable systems to learn and advance without a lot of human input. Matplotlib : Contains Python skills for a wide range of data visualizations. This book is rated 4.16 Teaches Python crash course.
In this blog, we’ll be covering the challenges and corresponding solutions that enable us to migrate thousands of Spark applications from Monarch to Moka while maintaining resource efficiency and a high quality of service. At the time of writing this blog, we have migrated half of the Spark workload running on Monarch to Moka.
CDP is the next generation big data solution that manages and secures the end-to-end data lifecycle – collecting, enriching, processing, analyzing, and predicting with their streaming data – to drive actionable insights and data-driven decision making. Why upgrade to CDP now?
Database Structures and Algorithms Different organizations use different data structures to store information in a database, and the algorithms help complete the task. Software developers play an important role in datacollection and analysis to ensure the company's security.
Finally, data science can be used to develop better products. For example, entrepreneurs can identify opportunities for new features or products by analyzing customer data. Data science can also be used to develop better algorithms for existing products, such as recommender systems.
In its initial years, Spotify used machine learning algorithms like collaborative filtering to recommend music to its subscribers. Collaborative Filtering It is a recommendation model that tries to estimate user preferences based on datacollected from different users.
By implementing an observability pipeline, which typically consists of multiple technologies and processes, organizations can gain insights into data pipeline performance, including metrics, errors, and resource usage. This ensures the reliability and accuracy of data-driven decision-making processes.
Read this blog to learn more about how the insurance industry benefits from implementing AI and ML solutions, which highlights the most practical applications and real-world use cases of machine learning in insurance and how it brings a new level of precision and effciency to the industry.
However, with data coming from so many different sources, it doesn’t always come in a format that’s easy for ML models to understand. In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about data preparation.
After all, machine learning with Python requires the use of algorithms that allow computer programs to constantly learn, but building that infrastructure is several levels higher in complexity. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. For now, we’ll focus on Kafka.
This mainly happened because data that is collected in recent times is vast and the source of collection of such data is varied, for example, datacollected from text files, financial documents, multimedia data, sensors, etc. This is one of the major reasons behind the popularity of data science.
A well-designed data pipeline ensures that data is not only transferred from source to destination but also properly cleaned, enriched, and transformed to meet the specific needs of AI algorithms. Why are data pipelines important? Where does Striim Come into Play When Building Data Pipelines?
The state-of-the-art neural networks that power generative AI are the subject of this blog, which delves into their effects on innovation and intelligent design’s potential. Algorithmic Trading: Predicting stock trends using historical data for automated trading strategies. What are neural networks?
The Internet of Things (IoT) is a network of physical objects like cars, appliances, and other household things that are equipped with connectivity, software, and sensors to collect and share data. In this blog, we will discuss the top 10 Internet of Things research topics and ideas for 2024.
This blog introduces the critical differences that one encounters when anyone performs an analysis of logistic regression vs linear regression. Firstly, we introduce the two machine learning algorithms in detail and then move on to their practical applications to answer questions like when to use linear regression vs logistic regression.
Data governance used to be considered a “nice to have” function within an enterprise, but it didn’t receive serious attention until the sheer volume of business and personal data started taking off with the introduction of smartphones in the mid-2000s. Companies indeed are taking notice.
Data analysis: Processing and studying the collecteddata to recognize patterns, trends, and irregularities that can aid in diagnosing issues or boosting performance. This enables seamless correlation between various data types and easier identification of root causes.
These anomalies can significantly impact data analysis, leading to incorrect or misleading insights. Unintentional anomalies are data points that deviate from the norm due to errors or noise in the datacollection process. These anomalies can distort the dataset, making it challenging to derive accurate insights.
They subsequently adjust the experiment’s start date so that it does not include metric datacollected prior to the bug fix. Internally, we apply a recursive algorithm to eliminate subsets of the data that contribute most to imbalance, similar to what an experimenter would do in the process of salvaging data from SRM.
AI algorithms analyze massive sensor-collecteddata from machines containing temperature, vibration, and pressure, among other operational parameters. Data Integration: The data is then fed into a central system, where it is processed and stored. AI algorithms can be used to access this data to start its analysis.
Or maybe, how can we generate synthetic data to enhance computer vision? Synthetic data helps us better understand the object or scene getting observed. It’s also a prerequisite for building novel algorithms for computer vision systems, but this is just a general talk. Let’s find out more about synthetic data in detail.
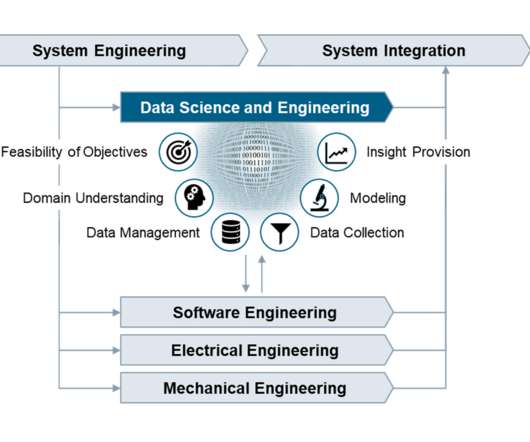
We need the same kind of professionalism in dealing with data that has been achieved in the established branches of engineering. Data Management Develop the data management strategy, define policies on data lifecycle management, design the specific solution architecture, and validate the technical solution after implementation.
Much like intrepid adventurers venturing into the vast unknown, data scientists embark on a journey through the intricate maze of data, driven by the quest to unearth hidden treasures of insight. With a median base salary of $110,000, there is a significant demand for data scientists, and this trend is projected to continue.
The blog discusses fairness in ML and demonstrates why high accuracy doesn’t mean the algorithm is fair. link] Sponsored: [New Guide] The Ultimate Guide to Data Mesh Architecture If implementing data mesh is high on your list of priorities, you’re not alone.
By employing algorithms that pick up on the subtleties of the input or training data they are given, generative AI certainly provides a multifaceted approach to data generation. It accomplishes this through complex algorithms and neural network architectures, and it has vast potential across many fields.
According to Glassdoor, the average annual pay of a data scientist is USD 126,683. In this blog post, we will look at some of the world's highest paying data science jobs, what they entail, and what skills and experience you need to land them. What is Data Science? They bridge the gap between data and software.
It's like the hidden dance partner of algorithms and data, creating an awesome symphony known as "Math and Data Science." " So, get ready for a fun ride in this blog as we explore the fascinating world of math in data science. These concepts underpin many numerical algorithms used in data science.
In this blog post, we will introduce you to 10 current database research topic ideas that are likely to be at the forefront of the field in 2023. From blockchain-based database systems to real-time data processing with in-memory databases, these topics offer a glimpse into the exciting future of database research.
Data science develops predictive models using sophisticated machine learning algorithms. The data used for analysis can come from various sources and be presented in various formats. Your profile simply serves as proof of your data science resume that you can back up your claims.
This blog post will delve into the challenges, approaches, and algorithms involved in hotel price prediction. Hotel price prediction is the process of using machine learning algorithms to forecast the rates of hotel rooms based on various factors such as date, location, room type, demand, and historical prices.
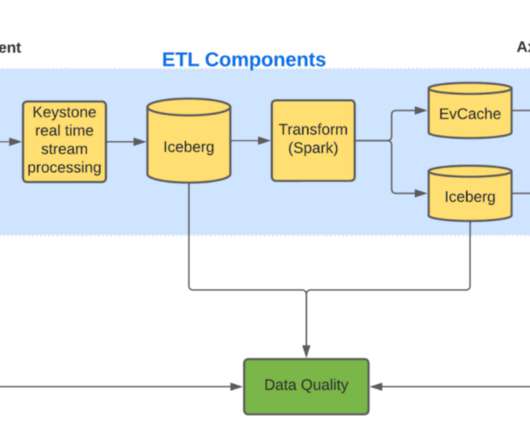
To achieve this, we rely on Machine Learning (ML) algorithms. ML algorithms can be only as good as the data that we provide to it. This post will focus on the large volume of high-quality data stored in Axion?—?our The Iceberg table created by Keystone contains large blobs of unstructured data.
FiveThirtyEight American website FiveThirtyEight specializes in opinion poll analysis, politics, economics, and sports blogging in the country. Using algorithms and statistical models, Silver and other analysts make forecasts about politics, sports, the economy, and other topics. Link to Dataset How are Data Science Datasets Created?
In this blog, I'll go into the interesting world of AI fraud detection, looking at how it works, its applications, benefits, and drawbacks. In essence, it's the use of AI anomaly detection algorithms, often covered in an Artificial Intelligence course for beginners , to analyze and identify suspicious activities or transactions.
However, collecting and annotating large amounts of data might not always be possible, and it is also expensive and time-consuming. Overfitting occurs when an ML model yields accurate results for training examples but not for unseen data. Data Augmentation Techniques How to do Data Augmentation in Keras?
Veracity meaning in big data is the degree of accuracy and trustworthiness of data, which plays a pivotal role in deriving meaningful insights and making informed decisions. This blog will delve into the importance of veracity in Big Data, exploring why accuracy matters and how it impacts decision-making processes.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content