This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
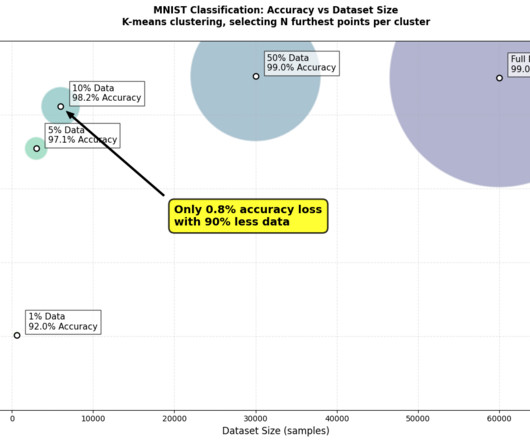
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. Best runs for furthest-from-centroid selection compared to full dataset. In my recent experiments with the MNIST dataset, thats exactly what happened. Images from the MNIST dataset , reproduced by theauthor. Image byauthor.
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Machine learning uses algorithms that comb through data sets and continuously improve the machine learning model.
Types of Machine Learning: Machine Learning can broadly be classified into three types: Supervised Learning: If the available dataset has predefined features and labels, on which the machine learning models are trained, then the type of learning is known as Supervised Machine Learning. A sample of the dataset is shown below.
A €150K ($165K) grant, three people, and 10 months to build it. The historical dataset is over 20M records at the time of writing! ” Like most startups, Spare Cores also made their own “expensive mistake” while building the product: “We accidentally accumulated a $3,000 bill in 1.5 Tech stack.
Building an accurate machine learning and AI model requires a high-quality dataset. Introduction In this era of Generative Al, data generation is at its peak.
There is no end to what can be achieved with the right ML algorithm. Machine Learning is comprised of different types of algorithms, each of which performs a unique task. U sers deploy these algorithms based on the problem statement and complexity of the problem they deal with.
” In this article, we are going to discuss time complexity of algorithms and how they are significant to us. As a software developer, I have been building applications and I know how important it becomes for us to deliver solutions that are fast and efficient. Let's first understand what an algorithm is.
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. In this article, we will look at 31 different places to find free datasets for data science projects. What is a Data Science Dataset?
The algorithms for generating text based 10 blue-links are very different from finding visually similar or related images. In this article, we will explain one such method to build a visual search engine. We will use the Caltech 101 dataset which contains images of common objects used in daily life.
The algorithms for generating text based 10 blue-links are very different from finding visually similar or related images. In this article, we will explain one such method to build a visual search engine. We will use the Caltech 101 dataset which contains images of common objects used in daily life.
Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets. Beyond technical tasks, AI Data Engineers uphold ethical standards and privacy requirements, making their contributions vital to building trustworthy AI systems.
Snowflake users are already taking advantage of LLMs to build really cool apps with integrations to web-hosted LLM APIs using external functions , and using Streamlit as an interactive front end for LLM-powered apps such as AI plagiarism detection , AI assistant , and MathGPT. Join us in Vegas at our Summit to learn more.
Aiming at understanding sound data, it applies a range of technologies, including state-of-the-art deep learning algorithms. Another application of musical audio analysis is genre classification: Say, Spotify runs its proprietary algorithm to group tracks into categories (their database holds more than 5,000 genres ).
These teams work together to ensure algorithmic fairness, inclusive design, and representation are an integral part of our platform and product experience. Our commitment is evidenced by our history of building products that champion inclusivity. “Everyone” has been the north star for our Inclusive AI and Inclusive Product teams.
The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. For instance, suppose a new dataset from an IoT device is meant to be ingested daily into the Bronze layer. How do you ensure data quality in every layer?
However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly. These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system.
At LinkedIn, trust is the cornerstone for building meaningful connections and professional relationships. By leveraging cutting-edge technologies, machine learning algorithms, and a dedicated team, we remain committed to ensuring a secure and trustworthy space for professionals to connect, share insights, and foster their career journeys.
Machine learning is a field that encompasses probability, statistics, computer science and algorithms that are used to create intelligent applications. Since machine learning is all about the study and use of algorithms, it is important that you have a base in mathematics. It works on a large dataset.
But since 2020, Skyscanner’s data leaders have been on a journey to simplify and modernize their data stack — building trust in data and establishing an organization-wide approach to data and AI governance along the way. The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months.
But since 2020, Skyscanner’s data leaders have been on a journey to simplify and modernize their data stack — building trust in data and establishing an organization-wide approach to data and AI governance along the way. The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months.
With its capabilities of efficiently training deep learning models (with GPU-ready features), it has become a machine learning engineer and data scientist’s best friend when it comes to train complex neural network algorithms. In this blog post, we are finally going to bring out the big guns and train our first computer vision algorithm.
Tools you can use to build NLP models. But today’s programs, armed with machine learning and deep learning algorithms, go beyond picking the right line in reply, and help with many text and speech processing problems. In NLP tasks, this process is called building a corpus. Preparing an NLP dataset. Main NLP use cases.
Today, we’ll talk about how Machine Learning (ML) can be used to build a movie recommendation system - from researching data sets & understanding user preferences all the way through training models & deploying them in applications. The heart of this system lies in the algorithm used in movie recommendation system.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. The telecom field is at a promising stage, and generative AI is leading the way in this stimulating quest to build new innovations.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. Data Normalization Data normalization is the process of adjusting related datasets recorded with different scales to a common scale, without distorting differences in the ranges of values.
These methods can provide rich information for decision making, such as in experimentation platforms (“XP”) or in algorithmic policy engines. Computation can explode and become overwhelming when this is done with large datasets, with high dimensional features, with many possible actions to choose from, and with many responses.
Today, we will delve into the intricacies the problem of missing data , discover the different types of missing data we may find in the wild, and explore how we can identify and mark missing values in real-world datasets. For that matter, we’ll take a look at the adolescent tobacco study example , used in the paper. Image by Author.
In the hands of an experienced practitioner, AutoML holds much promise for automating away some of the tedious parts of building machine learning systems. TPOT is a library for performing sophisticated search over whole ML pipelines, selecting preprocessing steps and algorithm hyperparameters to optimize for your use case.
One of the most exciting parts of our work is that we get to play a part in helping progress a skills-first labor market through our team’s ongoing engineering work in building our Skills Graph. soft or hard skill), descriptions of the skill (“the study of computer algorithms…”), and more. What is the skills taxonomy?
Certify your datasets 6. To treat any data asset as a product means combining a useful dataset with product management, a domain semantic layer, business logic, and access to deliver a final product thats appropriate and reliable for a given business use-case. Data contracts can help keep a log of changes to a dataset as well.
It was trained on a large dataset containing 15T tokens (compared to 2T for Llama 2). Structured generative AI — Oren explains how you can constraint generative algorithms to produce structured outputs (like JSON or SQL—seen as an AST). Llama has a larger tokeniser and the context window grew to 8192 tokens as input.
Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data. These models are trained on vast datasets which allow them to identify intricate patterns and relationships that human eyes might overlook.
CycleGAN, unlike traditional GANs, does not require paired datasets, in which each image in one domain corresponds to an image in another. CycleGAN is a framework for building image-to-image translation models without using paired samples. What is CycleGAN? Collecting such information can be time-consuming and costly.
Understanding data structures and algorithms (DSA) in C++ is key for writing efficient and optimised code. Some basic DSA in C++ that every programmer should know include arrays, linked lists, stacks, queues, trees, graphs, sorting algorithms like quicksort and merge sort, and search algorithms like binary search.
This method is effective, but it can significantly increase the completion times for operations with a single failure also In Spark, RDDs are the building blocks and Spark also uses it RDDs and DAG for fault tolerance. Dynamic nature: Spark offers over 80 high-level operators that make it easy to build parallel apps.
Since we know the applications of predictive model let us see how to build it. How do you build a predictive model in Python? Read the Dataset Assemble your info into a DataFrame with pandas. Example: Load a CSV file data = pd.read_csv('data.csv') print(data.head()) # Display the first few rows of the dataset 3.
To build a strong foundation and to stay updated on the concepts of Pattern recognition you can enroll in the Machine Learning course that would keep you ahead of the crowd. Data analysis and Interpretation: It helps in analyzing large and complex datasets by extracting meaningful patterns and structures. What Is Pattern Recognition?
Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models. They’re integral specialists in data science projects and cooperate with data scientists by backing up their algorithms with solid data pipelines. Choosing an algorithm. Let’s explore it.
Building a real-time, contextual and trustworthy knowledge base for AI applications revolves around RAG pipelines. Indexing vectors: Indexing algorithms can help to search across billions of vectors quickly and efficiently. What are the challenges building RAG pipelines? They also need to be designed for real-time updates.
Artificial Intelligence Projects for Beginners Building an AI system involves mirroring human traits and skills in a machine and then utilizing its computational power to outperform our skills. Datasets are obtained, and forecasts are made using a regression approach. Let’s get started on this.
The development process may include tasks such as building and training machine learning models, data collection and cleaning, and testing and optimizing the final product. Stock prediction aims to use AI to build models that can analyze historical stock data, spot patterns and trends, and forecast future prices.
Evolutionary Algorithms and their Applications 9. Machine Learning Algorithms 5. Machine Learning: Algorithms, Real-world Applications, and Research Directions Machine learning is the superset of Artificial Intelligence; a ground-breaking technology used to train machines to mimic human action and work. Data Mining 12.
On my side I'll talk about Apache Superset and what you can do to build a complete application with it. Capslocks and repetitions to make the algorithm understand. Commun Corpus — A HuggingFace dataset collection including public domain texts, newspapers and books in a lot of languages. Now give me the news.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. To build these necessary skills, a comprehensive course from a reputed source is a great place to start.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content