This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here we mostly focus on structured vs unstructureddata. In terms of representation, data can be broadly classified into two types: structured and unstructured. Structured data can be defined as data that can be stored in relational databases, and unstructureddata as everything else.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructureddata processing—a field that powers modern artificial intelligence (AI) systems. How does a self-driving car understand a chaotic street scene?
Generative AI and large language models (LLMs) are revolutionizing many aspects of both developer and non-coder productivity with automation of repetitive tasks and fast generation of insights from large amounts of data. LLMs have the potential to help both developers and less-technically inclined users make sense of the world’s data.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. The considerable amount of unstructureddata required Random Trees to create AI models that ensure privacy and data handling.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
[link] QuantumBlack: Solving data quality for gen AI applications Unstructureddata processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructureddata is a top question for every organization.
Aiming at understanding sound data, it applies a range of technologies, including state-of-the-art deep learning algorithms. Another application of musical audio analysis is genre classification: Say, Spotify runs its proprietary algorithm to group tracks into categories (their database holds more than 5,000 genres ).
Join me and Rockset VP of Engineering Louis Brandy for a tech talk, From Spam Fighting at Facebook to Vector Search at Rockset: How to Build Real-Time Machine Learning at Scale , on May 17th at 9am PT/ 12pm ET. Due to these difficulties, unstructureddata has remained largely underutilized. Why use vector search?
By leveraging an organization’s proprietary data, GenAI models can produce highly relevant and customized outputs that align with the business’s specific needs and objectives. Structured data is highly organized and formatted in a way that makes it easily searchable in databases and data warehouses.
Its how you integrate AI with your first-party data to deliver new business value that sets you apart. And its not sufficient to simply build these data + AI applications – as in any other technological discipline, you have to do it reliably, too. So, what does it mean to achieve trusted data + AI?
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. Generative AI demands the processing of vast amounts of diverse, unstructureddata (e.g.,
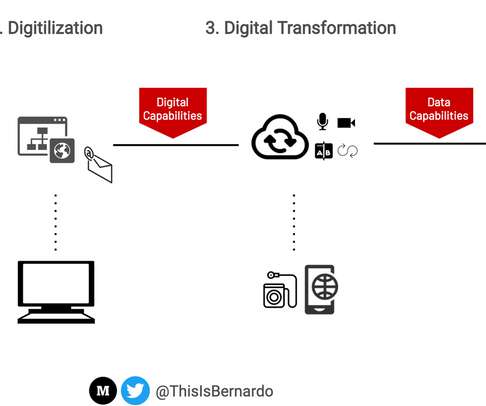
It was mainly a "product first, customers second" mentality of building products and services. ✅ Explain the link between Digital Transformation and Product Development With this wave of digitalization came the need to build proper information technology teams and promoting digital literacy, mainly in the workplace.
As data engineers we are responsible for building and managing the platforms that power these models. What is involved in building a data pipeline and production infrastructure for a deep learning product? How does that differ from other types of analytics projects such as data warehousing or traditional ML?
paintings, songs, code) Historical data relevant to the prediction task (e.g., paintings, songs, code) Historical data relevant to the prediction task (e.g., Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data.
Now, implementation is possible through AI algorithms that you can learn through a renowned Artificial Intelligence online course. There are AI algorithms Python, and other programming languages, that you would have to learn and see how they can make a difference. What is an AI algorithm? How Do AI Algorithms Work?
Generative AI uses neural networks and deep learning algorithms from LLMs to identify patterns in existing data to generate original content. But while the potential is theoretically limitless, there are a number of data challenges and risks HCLS executives need to be aware of when using AI that can create new content.
Market intelligence and portfolio management: Gen AI can help deduce market sentiment and financial trends by analyzing unstructureddata such as filings, reports and news articles. Enhanced algorithmic simulations, fueled by extensive forecasting data, can provide more accurate and reliable risk-model recommendations.
The hype around generative AI is real, and data and ML teams are feeling the heat. Across industries, executives are pushing their data leaders to build AI-powered products that will save time, drive revenue, or give them a competitive advantage. Image courtesy of author.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. Analytics - Spark can be very useful when building real-time analytics from a stream of incoming data. to enhance the recommendations to customers based on new trends.
Machine Learning without data sets will not exist because ML depends on data sets to bring out relevant insights and solve real-world problems. Machine learning uses algorithms that comb through data sets and continuously improve the machine learning model. Alternatively, we also can make our own datasets.
To start, they look to traditional financial services data, combining and correlating account activity, borrowing history, core banking, investments, and call center data. Rabobank runs sophisticated machine learning algorithms and financial models to help customers manage their financial obligations, including loan repayments. .
To the data scientists pushing the boundaries of what’s possible, the AI experts and enthusiasts who see beyond the horizon, and the techies building tomorrow’s solutions today — this manifesto is for you. The key to unlocking AI’s full potential lies in real time data.
As Data Science is an intersection of fields like Mathematics and Statistics, Computer Science, and Business, every role would require some level of experience and skills in each of these areas. To build these necessary skills, a comprehensive course from a reputed source is a great place to start.
The Modern Story: Navigating Complexity and Rethinking Data in The Business Landscape Enterprises face a data landscape marked by the proliferation of IoT-generated data, an influx of unstructureddata, and a pervasive need for comprehensive data analytics.
These projects typically involve a collaborative team of software developers, data scientists, machine learning engineers, and subject matter experts. The development process may include tasks such as building and training machine learning models, data collection and cleaning, and testing and optimizing the final product.
Big data vs machine learning is indispensable, and it is crucial to effectively discern their dissimilarities to harness their potential. Big Data vs Machine Learning Big data and machine learning serve distinct purposes in the realm of data analysis.
Although both Data Science and Software Engineering domains focus on math, code, data, etc., Is mastering data science beneficial or building software is a better career option? Data Science is a field of study that handles large volumes of data using technological and modern techniques.
Comparison Between Full Stack Developer vs Data Scientist Let’s compare Full stack vs data science to understand which is better, data science or full stack developer. Specifications Full stack developer Data scientist Term It is the creation of websites for the intranet, which is a public platform.
Also, while agencies view embracing AI as a strategic imperative that will enable them to accelerate the mission, they also face the challenge of finding readily available talent and resources to build AI solutions. Make sure to audit data regularly. Build public trust through education on AI. Develop mitigation strategies.
The Modern Story: Navigating Complexity and Rethinking Data in The Business Landscape Enterprises face a data landscape marked by the proliferation of IoT-generated data, an influx of unstructureddata, and a pervasive need for comprehensive data analytics.
This mainly happened because data that is collected in recent times is vast and the source of collection of such data is varied, for example, data collected from text files, financial documents, multimedia data, sensors, etc. This is one of the major reasons behind the popularity of data science.
However, many organizations have data silos, for instance when each department’s data is historically stored in disparate locations. Additionally, structured and unstructureddata is often separate. By eliminating data silos, your data insights enable smarter and more accurate business decisions.
Still, it’s one thing to show your boss a cool demo of a data discovery tool or text-to-SQL generator – it’s another thing to use it with your company’s proprietary data, or even more concerning, customer data. Think: SecOps for AI. We shouldn’t treat AI applications any differently. Take GPT-4 for example.
Data Science is one of the fastest-growing, trending tech career tracks. With such a huge demand for the role, a lot of professionals and graduates are trying to step into this field to quench the demand and build lucrative careers. Let us look at some of the areas in Mathematics that are the prerequisites to becoming a Data Scientist.
Key Components of a Neural Network Neurons: Basic building blocks that use activation functions to process information. Multiple levels: Raw data is accepted by the input layer. Neural Network Neurons Modeled after their biological counterparts in the brain, neurons serve as the building blocks of neural networks.
Suppose you’re among those fascinated by the endless possibilities of deep learning technology and curious about the popular deep learning algorithms behind the scenes of popular deep learning applications. Table of Contents Why Deep Learning Algorithms over Traditional Machine Learning Algorithms? What is Deep Learning?
The hype around generative AI is real, and data and ML teams are feeling the heat. Across industries, executives are pushing their data leaders to build AI-powered products that will save time, drive revenue, or give them a competitive advantage.
Credit scoring and risk assessment: Traditional credit scoring models rely on narrow and limited financial data, making it difficult for individuals without a well-established credit history to access loans or other financial products.
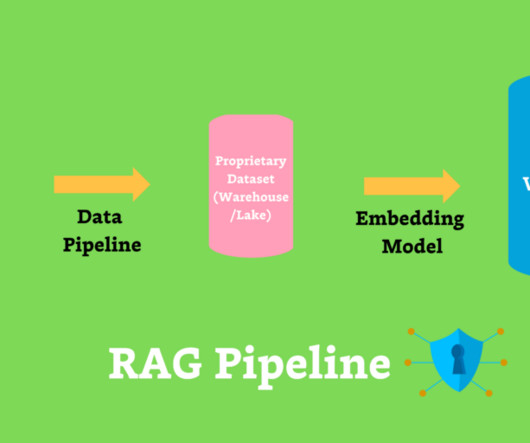
In this guide, we’ll dive into everything you need to know about data pipelines—whether you’re just getting started or looking to optimize your existing setup. We’ll answer the question, “What are data pipelines?” Then, we’ll dive deeper into how to builddata pipelines and why it’s imperative to make your data pipelines work for you.
Top 7 Data Science Applications in Finance Financial technology, or FinTech, refers to the use of technology by providers of financial services to optimize the usage and delivery of their services to customers. Algorithmic Trading Algorithmic trading is an exciting real-world application of data science in finance.
When it comes to big data vs data mining, big data focuses on managing large-scale data. In contrast, data mining goes beyond that by actively seeking patterns and extracting valuable insights. Big Data online can help you leverage big data skills and build a robust skill-set.
We founded Rockset to empower everyone from Fortune 500 to a five-person startup to build powerful search and AI applications and scale them efficiently in the cloud. We believe any engineer in the world should be able to quickly build powerful data apps. Building these apps should be as simple as constructing a SQL query.
By utilizing ML algorithms and data, it is possible to create smart models that can precisely predict customer intent and as such provide quality one-to-one recommendations. At the same time, the continuous growth of available data has led to information overload — when there are too many choices, complicating decision-making.
AI and ML for Risk Management ML models can analyze large volumes of data to identify patterns and anomalies indicating potential risks such as fraud, money laundering or credit default, enabling proactive mitigation. ML models enhance anti-money laundering (AML) compliance by detecting suspicious transaction patterns and customer behaviors.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content