This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Built for the AI era, Components offers compartmentalized code units with proper guardrails that prevent "AI slop" while supporting code generation. If you look at all the BI or UI-based ETL tools, the code is a black box for us, but we validate the outcome generated by the black-box.
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. Brief overview of image coding formats The JPEG format was introduced in 1992 and is widely popular. This is followed by quantization and entropy coding. Advanced Video Coding ( AVC ) format.
Existing algorithms have reliably secured data for a long time. However, Shor’s algorithm can efficiently break these cryptosystems using a sufficiently large quantum computer. The liboqs library implements post-quantum cryptography algorithms for key encapsulation and signature mechanisms, including Kyber.
The project will focus on creating a user-friendly interface as a web / Desktop application and incorporating robust algorithms to assess password strength accurately. Source code 2. Source code 3. Source code 4. Source Code Cyber Security Final Year Projects 1. Source code 2.
An Avro file is formatted with the following bytes: Figure 1: Avro file and data block byte layout The Avro file consists of four “magic” bytes, file metadata (including a schema, which all objects in this file must conform to), a 16-byte file-specific sync marker, and a sequence of data blocks separated by the file’s sync marker.
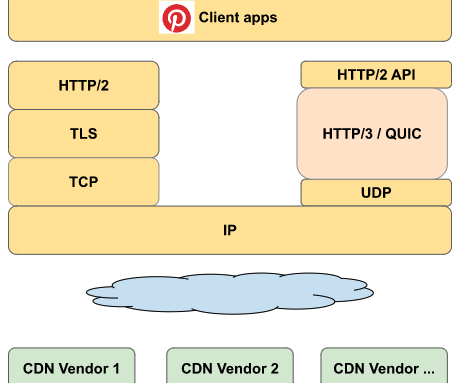
These advancements fit well with Pinterest use cases — enabling faster connection establishment (time to first byte of first request), improved congestion control (large media as we have), multiplexing without TCP head-of-line blocking (multiple downloads at the same time), and continued in-flight requests when pinners’ device network/ip changes.
There are a variety of industry-standard algorithms that are used to generate OTP tokens such as SHA256, however, they require two inputs, a static value known as a secret key and a moving factor which changes each time an OTP value is generated. We can now use hotp to generate the code. val counter = 5 val code = hotp.
That is, all mounted files that were opened and every single byte range read that MezzFS received. Finally, MezzFS will record various statistics about the mount, including: total bytes downloaded, total bytes read, total time spent reading, etc. Actions ?—?MezzFS The different colors mean different things?—?green
The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). Seagate Technology forecasts that enterprise data will double from approximately 1 to 2 Petabytes (one Petabyte is 10^15 bytes) between 2020 and 2022. Data annotation.
Much of the code used by modern astronomers is written in Python, so the ZTF alert distribution system endpoints need to at least support Python. We built our alert distribution code in Python, based around Confluent’s Python client for Apache Kafka. Downstream filtering algorithms classify and separate different types of objects.
Job information after creating a clustered table(Image by author) Execution details after creating a clustered table(Image by author) From the job info and execution details, you can see the number of bytes processed and records scanned reduced significantly(from 1.5 GB to 55 MB and 7M to 260k). At the end of the day, it’s not a free lunch.
This framework does not require any code changes to the system-under-test that is being validated. Over time we can do more intrusive whitebox testing by enabling and disabling various join points and delay-points within the Ozone code. No changes to Ozone code required for simulating failures. How does it work?
quintillion bytes of data are created every single day, and it’s only going to grow from there. MapReduce is written in Java and the APIs are a bit complex to code for new programmers, so there is a steep learning curve involved. Almost all machine learning algorithms work iteratively. As estimated by DOMO : Over 2.5
Better performance, lower cost and less code complexity Xiao Li, Kapil Bajaj, Monil Mukesh Sanghavi and Zhenxiao Luo Introduction In the dynamic arena of real-time analytics, the need for precision and speed is non-negotiable. To assess the frequency of these GC pauses, we measure the time interval between each young collection.
Numeric data consists of four sub-types: Integer type (INT64) Numeric type (NUMERIC DECIMAL) Bignumeric type (BIGNUMERIC BIGDECIMAL) Floating point type (FLOAT64) BYTES Although they work with raw bytes rather than Unicode characters, BYTES also represent variable-length data.
This process is almost indispensable even for more complex algorithms like Optical Character Recognition, around which companies like Microsoft have built and deployed entire products (i.e., Alternatively, you could attempt to implement other Grayscaling algorithms like the Lightness and the Average Method. Microsoft OCR).
Full code on GitHub. Note that the MappingProcessor and FilteringProcessor code is omitted here for clarity. Full code on GitHub. Full code on GitHub. Full code on GitHub. The join algorithms here are similar to the collocated hash join algorithm in parallel database systems. println(builder.
I’d been hearing lots of talk about Bun, particularly on the Bytes email blast but hadn’t had a chance to properly check it out so I was particularly interested in seeing how it did. Despite myself, I started thinking about Christmas things, and more specifically… Advent of Code. running the same code? projects to Bun?
The ML for large-scale production systems highlights the improvement made from the existing heuristic in the YouTube cache replacement algorithm with a new hybrid algorithm that combines a simple heuristic with a learned model, improving the byte miss ratio at the peak by ~9%.
Detecting cancerous cells in microscopic photography of cells (Whole Slide Images, aka WSIs) is usually done with segmentation algorithms, which NNs are very good at. Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation.
Brotli is a lossless compression algorithm, designed and released by Google for use on the web. When we enabled brotli in a straightforward manner, it reduced bytes sent as expected. In the end, we decided that the brotli treatment was better mainly on the basis of sending 10% fewer bytes over the wire. Photo CC BY-SA 2.0
Programming is the process of developing software or applications by coding in a specific language. Programmers are the architects of the application, who design the logic, define the required functionality, and create the algorithms to achieve the desired result. What is Programming? What is Web Development?
Machine learning is a way in which artificial intelligence is used to train algorithms or computers. Machine learning algorithms can analyze potentially tera bytes of data, identify patterns from these data, and make predictions or decisions. Predictive Analytics can assist in early detection and intervention.
Such libraries use the advanced type system of the Scala language (and/or some macro magic for some specific information not provided by types alone) to generate code and compile-time that otherwise would have to be written by hand or by using reflection – and no-one wants to write those JsObjects by hand.
Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day. Data Scientists use ML algorithms to make predictions on the data sets. Basic knowledge of ML technologies and algorithms will enable you to collaborate with the engineering teams and the Data Scientists.
A Java professional, having learnt Hadoop will find it easier to dig deeper into the Hadoop codes and he would be in a better position to understand the functionality of a particular module and this is where Java professionals gain an edge over other professionals. zeta bytes during the current year.
Image encryption techniques employ mathematical algorithms and cryptographic methods to alter the pixel values or the visual representation of an image. These algorithms convert the original image into a ciphered or scrambled version, rendering it meaningless to anyone without the appropriate decryption key.
When a request is made to the recommender system, a query is made to this key-value store using the user ID, and the retrieved features are fed to the recommendation algorithm together with the data contained in the original request. They are essentially a lossy compression algorithm for your features. store = store self.
It also teaches how to derive and incorporate optimization algorithms for the models. An Intermediate NLP engineer with 3-6 years of experience earns $160,000 An Advanced NLP engineer with 6-9 years' of experience earns $200,000 NLP Engineer Salary: Based on Location India City Company Average Salary Bangalore Gnani Innovations 7.7
Image Credit: saphanatutorial.com At times, Hadoop developers might be required to dig deep into Hadoop code to understand the functionality of certain modules or why a particular piece of code is behaving strange. Java tutorials will help you understand and retain information with practical code snippets.
My department is Pricing Platform, and our main scope is pricing and discounting tools and algorithms. Every month, Tech Academy hosts a Coffee Bytes event, a casual coffee meet-up with no set agenda, allowing members of the tech community to connect and make friends. What's Next?
quintillion bytes of data today, and unless that data is organized properly, it is useless. Big data tools are used to perform predictive modeling, statistical algorithms and even what-if analyses. Xplenty Using minimal code allows you to build a data pipeline. A global data explosion is generating almost 2.5
For example, if you were measuring absolute table size, you would could trigger an event when: The current total size (bytes or rows) decreases to a specific volume The current total size remains the same for a specific amount of time Numeric distribution tests Is my data within an accepted range? Image courtesy of Monte Carlo.
Data structure is an essential part of computer science, whether knowledge is sought on subtle details of coding or data manipulation. Master the foundations of coding excellence: Enroll in the Best Data Structure online courses. Transform your potential with KnowledgeHut's best Coding Bootcamps for Software Engineering.
quintillion bytes. Data transformation involves changing the structure of your data set so that it can be better analyzed by Machine Learning algorithms (ML). For example, you could use data transformation to convert categorical variables into numerical ones for easier analysis by ML algorithms. . How to Clean Data? .
You then control the controller by providing colour data as an RGB byte sequence using just a single pin. This can greatly simplify application code by removing the need to explicitly maintain state machines and poll routines. For example, here’s the guts of the code from that post - let mut switch_state = switch_pin.is_low ().unwrap
One petabyte is equivalent to 20 million filing cabinets; worth of text or one quadrillion bytes. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Walmart was the world’s largest retailer in 2014 in terms of revenue. How Walmart uses Big Data?
There is great excitement around Apache Spark as it provides fundamental advantages in interactive data interrogation on in-memory data sets and in multi-pass iterative machine learning algorithms. With Apache Spark, you can write collection-oriented algorithms using Scala's functional programming language.
Data quality can be impacted by everything from software changes at the source all the way down to how an SDR inputs a country code. A couple days before they pull their report, one of your engineers pushes a code change to production that deletes a critical revenue column from a key table.
During the development phase, the team agreed on a blend of PyCharm for developing code and Jupyter for interactively running the code. Below is the entire code for removing duplicate rows- import pyspark from pyspark.sql import SparkSession from pyspark.sql.functions import expr spark = SparkSession.builder.appName('ProjectPro').getOrCreate()
Each micro-partition's column is automatically assigned the most effective compression algorithm by the snowflake storage layer. BigQuery charges users depending on how many bytes are read or scanned. Source Code- How to deal with slowly changing dimensions using Snowflake?
It is infinitely scalable, and individuals can upload files ranging from 0 bytes to 5 TB. Predictive: This scaling option leverages machine learning algorithms to schedule the correct number of EC2 instances with respect to changes in traffic. Data objects are stored redundantly across multiple devices in several locations.
Wrappers Method: This method employs the 'induction algorithm,' which may be used to generate a classifier. A user-defined function (UDF) is a common feature of programming languages, and the primary tool programmers use to build applications using reusable code. Metadata for a file, block, or directory typically takes 150 bytes.
Such use of an embedded protocol is a universal way for any type of distributed processes to coordinate with each other and implement their custom logic without requiring the Kafka broker’s code to be aware of their existence. This simplifies the broker’s code and enables clients to enrich their load balancing policies at will.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content