This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Storing data: datacollected is stored to allow for historical comparisons. The historical dataset is over 20M records at the time of writing! The current database includes 2,000 server types in 130 regions and 340 zones. This means about 275,000 up-to-date server prices, and around 240,000 benchmark scores.
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. Your data should possess the maximum available information to perform meaningful analysis. What is a Data Science Dataset?
This bias can be introduced at various stages of the AI development process, from datacollection to algorithm design, and it can have far-reaching consequences. For example, a biased AI algorithm used in hiring might favor certain demographics over others, perpetuating inequalities in employment opportunities.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. This article will focus on explaining the contributions of generative AI in the future of telecommunications services.
Today, we will delve into the intricacies the problem of missing data , discover the different types of missing data we may find in the wild, and explore how we can identify and mark missing values in real-world datasets. Image by Author. Let’s consider an example. Image by Author. Image by Author.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
Regardless of industry, data is considered a valuable resource that helps companies outperform their rivals, and healthcare is not an exception. In this post, we’ll briefly discuss challenges you face when working with medical data and make an overview of publucly available healthcare datasets, along with practical tasks they help solve.
Machine learning is a field that encompasses probability, statistics, computer science and algorithms that are used to create intelligent applications. These applications have the capability to glean useful and insightful information from data that is useful to arrive business insights. It works on a large dataset.
Aiming at understanding sound data, it applies a range of technologies, including state-of-the-art deep learning algorithms. Another application of musical audio analysis is genre classification: Say, Spotify runs its proprietary algorithm to group tracks into categories (their database holds more than 5,000 genres ).
To make sure they were measuring real world impacts, Koller and Bosley selected two publicly available datasets characterized by large volumes and imbalanced classifications, reflective of real-world scenarios where classification algorithms often need to detect rare events such as fraud, purchasing intent, or toxic behavior.
To make sure they were measuring real world impacts, Koller and Bosley selected two publicly available datasets characterized by large volumes and imbalanced classifications, reflective of real-world scenarios where classification algorithms often need to detect rare events such as fraud, purchasing intent, or toxic behavior.
Here are some key technical benefits and features of recognizing patterns: Automation: Pattern recognition enables the automation of tasks that require the identification or classification of patterns within data. These features help capture the essential characteristics of the patterns and improve the performance of recognition algorithms.
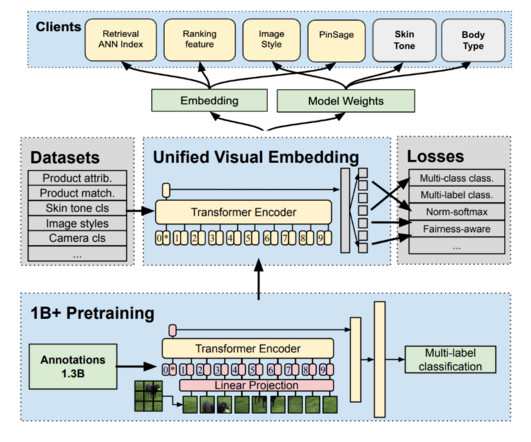
These teams work together to ensure algorithmic fairness, inclusive design, and representation are an integral part of our platform and product experience. Signal Development and Indexing The process of developing our visual body type signal essentially begins with datacollection.
A large hospital group partnered with Intel, the world’s leading chipmaker, and Cloudera, a Big Data platform built on Apache Hadoop , to create AI mechanisms predicting a discharge date at the time of admission. The built-in algorithm learns from every case, enhancing its results over time. Inpatient data anonymization.
An inaccuracy known as bias in data occurs when specific dataset components are overweighted or overrepresented. In reality, computers, data, and algorithms are not entirely objective. Data analysis can indeed aid in better decision-making, yet bias can still creep in. What Does Bias Mean in Data Analytics? .
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured datacollection that is stored and accessed electronically.
These projects typically involve a collaborative team of software developers, data scientists, machine learning engineers, and subject matter experts. The development process may include tasks such as building and training machine learning models, datacollection and cleaning, and testing and optimizing the final product.
Monitoring has given us a distinct advantage in our efforts to proactively detect and remove weak cryptographic algorithms and has assisted with our general change safety and reliability efforts. More generally, improved understanding helps us to make emergency algorithm migrations when a vulnerability of a primitive is discovered.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. In this article, we will look at some of the top Data Science job roles that are in demand in 2024.
The invisible pieces of code that form the gears and cogs of the modern machine age, algorithms have given the world everything from social media feeds to search engines and satellite navigation to music recommendation systems. Recommender Systems – An Introduction Datacollection is ubiquitous now.
Summary Industrial applications are one of the primary adopters of Internet of Things (IoT) technologies, with business critical operations being informed by datacollected across a fleet of sensors. With Select Star’s data catalog, a single source of truth for your data is built in minutes, even across thousands of datasets.
Use Stack Overflow Data for Analytic Purposes Project Overview: What if you had access to all or most of the public repos on GitHub? As part of similar research, Felipe Hoffa analysed gigabytes of data spread over many publications from Google's BigQuery datacollection. Which queries do you have?
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful Big Data tool, Apache Hadoop alone is far from being almighty.
Let’s study them further below: Machine learning : Tools for machine learning are algorithmic uses of artificial intelligence that enable systems to learn and advance without a lot of human input. Matplotlib : Contains Python skills for a wide range of data visualizations. This book is rated 4.16 Teaches Python crash course.
Then the server will apply the same hash algorithm and blinding operation with secret key b to all the passwords from the leaked password dataset. First, hashing and blinding each password in the leaked password dataset at runtime cause a lot of latency at the server side. Sharding the leaked password dataset.
These streams basically consist of algorithms that seek to make either predictions or classifications by creating expert systems that are based on the input data. Even Email spam filters that we enable or use in our mailboxes are examples of weak AI where an algorithm is used to classify spam emails and move them to other folders.
Data Anomaly: Types, Causes, Detection, and Resolution Helen Soloveichik July 6, 2023 What Is Data Anomaly? A data anomaly, also known as an outlier, is an observation or data point that deviates significantly from the norm, making it inconsistent with the rest of the dataset.
Learning Outcomes: You will understand the processes and technology necessary to operate large data warehouses. Engineering and problem-solving abilities based on Big Data solutions may also be taught. Possible Careers: Data analyst Marketing analyst Data mining analyst Data engineer Quantitative analyst 3.
Or maybe, how can we generate synthetic data to enhance computer vision? Synthetic data helps us better understand the object or scene getting observed. It’s also a prerequisite for building novel algorithms for computer vision systems, but this is just a general talk. Let’s find out more about synthetic data in detail.
A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured. This is one of the major reasons behind the popularity of data science. An exploratory study of the given data set.
Recognizing the difference between big data and machine learning is crucial since big data involves managing and processing extensive datasets, while machine learning revolves around creating algorithms and models to extract valuable information and make data-driven predictions.
A well-designed data pipeline ensures that data is not only transferred from source to destination but also properly cleaned, enriched, and transformed to meet the specific needs of AI algorithms. Why are data pipelines important? Where does Striim Come into Play When Building Data Pipelines?
Parameters Machine Learning (ML) Deep Learning (DL) Feature Engineering ML algorithms rely on explicit feature extraction and engineering, where human experts define relevant features for the model. DL models automatically learn features from raw data, eliminating the need for explicit feature engineering. What is Machine Learning?
Firstly, we introduce the two machine learning algorithms in detail and then move on to their practical applications to answer questions like when to use linear regression vs logistic regression. Machine Learning , as the name suggests, is about training a machine to learn hidden patterns in a dataset through mathematical algorithms.
This is done by first elaborating on the dataset curation stage?—?specially Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the data engineering that goes along with it. The dataset will thus be very biased/skewed.
Preparing the data for use in the model is paramount to the benefits of machine learning predictions , so let’s review what steps to take to ensure you’re getting the most out of your model. Data Preprocessing Even though you now have clean, consistent data, it’s still not ready to train your model.
This would help you lead teams, build predictive models, identify trends, and provide recommendations to management based on findings from the data analysed using advanced statistics, machine learning algorithms, mathematical models, and techniques. What are Data Analytics Projects? to build a predictive model from a dataset.
To achieve this, we rely on Machine Learning (ML) algorithms. ML algorithms can be only as good as the data that we provide to it. This post will focus on the large volume of high-quality data stored in Axion?—?our However, for a given ML model, we only require a subset of the data stored in Axion for its training needs.
This blog post will delve into the challenges, approaches, and algorithms involved in hotel price prediction. Hotel price prediction is the process of using machine learning algorithms to forecast the rates of hotel rooms based on various factors such as date, location, room type, demand, and historical prices. Data relevance.
Top 20 Python Projects for Data Science Without much ado, it’s time for you to get your hands dirty with Python Projects for Data Science and explore various ways of approaching a business problem for data-driven insights. 1) Music Recommendation System on KKBox Dataset Music in today’s time is all around us.
However, data scientists are primarily concerned with working with massive datasets. Data Science is strongly influenced by the value of accurate estimates, data analysis results, and understanding of those results. Get to know more about SQL for data science.
This blog offers an exclusive glimpse into the daily rituals, challenges, and moments of triumph that punctuate the professional journey of a data scientist. The primary objective of a data scientist is to analyze complex datasets to uncover patterns, trends, and valuable information that can aid in informed decision-making.
Machine Learning is a scientific field of study which involves the use of algorithms and statistics to perform a given task by relying on inference from data instead of explicit instructions. It has become a norm for Data scientists today to have a machine learning with Python certification.
Various machine learning models — whether these are simpler algorithms like decision trees or state-of-the-art neural networks — need a certain metric or multiple metrics to evaluate their performance. The first ones involve datacollection and preparation to ensure it’s of high quality and fits the task.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content