This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Storing data: datacollected is stored to allow for historical comparisons. Benchmarking: for new server types identified – or ones that need an updated benchmark executed to avoid data becoming stale – those instances have a benchmark started on them.
In this post, the Binary Search Algorithm will be covered. Finding a certain element in the list is the process of searching. Finding a certain element in the list is the process of searching. We'll talk about the Binary Search Algorithm here. A quick search algorithm with run- time complexity of O is a binary search.
The Importance of Mainframe Data in the AI Landscape For decades, mainframes have been the backbone of enterprise IT systems, especially in industries such as banking, insurance, healthcare, and government. These systems store massive amounts of historical datadata that has been accumulated, processed, and secured over decades of operation.
Introduction to Data Structures and AlgorithmsData Structures and Algorithms are two of the most important coding concepts you need to learn if you want to build a bright career in Development. Topics to help you get started What are Data Structures and Algorithms?
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. This article will focus on explaining the contributions of generative AI in the future of telecommunications services.
If you’re AI-first, that means you have figured out how to leverage artificial intelligence to boost organizational agility so you can continuously adapt operational processes to deliver the right business outcomes. . Datacollection and interpretation when purchasing products and services can make a big difference. Procurement.
Shopping Experience Enhancement Expanding the dynamic header system to other Pinterest surfaces Developing new shopping-specific modules Further optimizing the gift discovery algorithm 3. Gift-Specific Filtering: A post-ranking filter removes utilitarian products while elevating items with strong giftsignals.
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
We’ve seen organizations invest in big data solutions, and now, we’ve increasingly seen them want to build on that investment and move towards building a modern architecture that’ll help them leverage stream processing and streaming analytics. Cloudera Data Platform (CDP) is the new data cloud built for the enterprise.
To use such tools effectively, though, government organizations need a consolidated data platform–an infrastructure that enables the seamless ingestion and integration of widely varied data, across disparate systems, at speed and scale. Analyzing historical data is an important strategy for anomaly detection.
For more information, check out the best Data Science certification. A data scientist’s job description focuses on the following – Automating the collectionprocess and identifying the valuable data. Research and implement machine learning tools and algorithms. Choose data sets.
In reality, computers, data, and algorithms are not entirely objective. Data analysis can indeed aid in better decision-making, yet bias can still creep in. It’s we, humans, that technologies and algorithms. In more detail, let’s examine some biases affecting data analysis and data-driven decision-making. .
Today, generative AI-powered tools and algorithms are being used for diagnostics, predicting disease outbreaks and targeted treatment plans — and the industry is just getting started. Life sciences generate enormous amounts of data that gen AI can harvest to uncover new insights.
This can be done by finding regularities in the data, such as correlations or trends, or by identifying specific features in the data. Pattern recognition is used in a wide variety of applications, including Image processing, Speech recognition, Biometrics, Medical diagnosis, and Fraud detection.
This is where Data Science comes into the picture. The art of analysing the data, extracting patterns, applying algorithms, tweaking the data to suit our requirements, and more – are all part s of data science. All these are different processes in the world of data analytics.
The goal is to define, implement and offer a data lifecycle platform enabling and optimizing future connected and autonomous vehicle systems that would train connected vehicle AI/ML models faster with higher accuracy and delivering a lower cost.
Our brains are constantly processing sounds to give us important information about our environment. But first, let’s go over the basics: What is the audio analysis, and what makes audio data so challenging to deal with. Audio analysis is a process of transforming, exploring, and interpreting audio signals recorded by digital devices.
This speeds up the process of making content and makes it easier to scale. DeepBrain AI is driven by powerful machine learning algorithms and natural language processing. DataCollection and Preprocessing: DeepBrain AI begins by putting together big sets of data that include speech patterns, text, and other useful information.
and In my view, Data Science primarily focuses on engineering, processing, interpreting, and analyzing data to facilitate effective and informed decision-making. These streams basically consist of algorithms that seek to make either predictions or classifications by creating expert systems that are based on the input data.
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
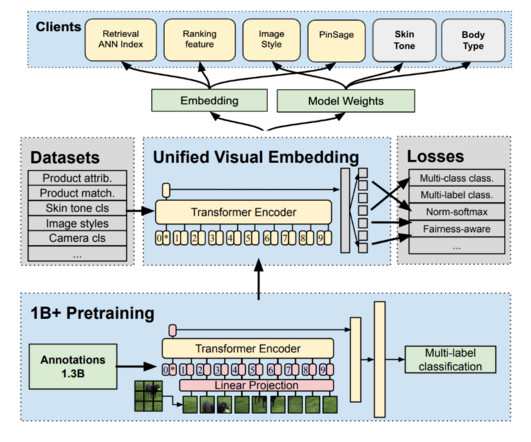
These teams work together to ensure algorithmic fairness, inclusive design, and representation are an integral part of our platform and product experience. Signal Development and Indexing The process of developing our visual body type signal essentially begins with datacollection.
Personalized insurance is the process of reaching insurance customers with targeted pricing, offers, and messages at the right time. Insurers use datacollected from smart devices to notify customers about harmful activities and lifestyles. What is personalized insurance, and why is it important? Personalized communications.
The Problem of Missing Data Missing Data is an interesting data imperfection since it may arise naturally due to the nature of the domain, or be inadvertently created during data, collection, transmission, or processing. Missing Completely At Random (MCAR): No harm, no foul! Image by Author.
Machine learning is a field that encompasses probability, statistics, computer science and algorithms that are used to create intelligent applications. These applications have the capability to glean useful and insightful information from data that is useful to arrive business insights. are the tools used in Inferential Statistics.
Today’s episode of the Data Engineering Podcast is sponsored by Datadog, a SaaS-based monitoring and analytics platform for cloud-scale infrastructure, applications, logs, and more. How uniform is the availability and formatting of data from different manufacturers?
An ML model is an algorithm (e.g., Decision Trees, Random Forests, or Neural Networks) that has been trained on data to generate predictions and help a computer system, a human, or their tandem make decisions. To enable algorithm fairness, you can: research biases and their causes in data (e.g., Source: SMBC Comics.
It also helps organizations to maintain complex dataprocessing systems with machine learning. To achieve this objective, companies need to group the following four major verticals of data science. These verticals include data engineering, data analysis, data modeling, and model deployment, also known as data monitoring.
A large hospital group partnered with Intel, the world’s leading chipmaker, and Cloudera, a Big Data platform built on Apache Hadoop , to create AI mechanisms predicting a discharge date at the time of admission. The built-in algorithm learns from every case, enhancing its results over time. Data preparation for LOS prediction.
It means a computer or a system designed with machine learning will identify, analyse and change accordingly and give the expected output when it comes across a new pattern of data, without any need of humans. Today, we all know that artificial neural networks play a key role in the thinking process of computers and machines.
Data Science is the fastest emerging field in the world. It analyzes data extraction, preparation, visualization, and maintenance. Data scientists use machine learning and algorithms to bring forth probable future occurrences. Data Science in the future will be the largest field of study. What is Data Science?
To make sure they were measuring real world impacts, Koller and Bosley selected two publicly available datasets characterized by large volumes and imbalanced classifications, reflective of real-world scenarios where classification algorithms often need to detect rare events such as fraud, purchasing intent, or toxic behavior.
To make sure they were measuring real world impacts, Koller and Bosley selected two publicly available datasets characterized by large volumes and imbalanced classifications, reflective of real-world scenarios where classification algorithms often need to detect rare events such as fraud, purchasing intent, or toxic behavior.
By analyzing performance metrics and consumer feedback, AI algorithms can identify areas for improvement and recommend strategic adjustments, such as optimal channels and times for engagement. This can free up time for content marketers to focus on the more creative, strategic aspects of their work and accelerate the ad production process.
You can execute this by learning data science with python and working on real projects. These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. Along with business understanding, you also need to have analytical skills.
Summary Industrial applications are one of the primary adopters of Internet of Things (IoT) technologies, with business critical operations being informed by datacollected across a fleet of sensors. What level of pre-processing/filtering is being done at the edge and how do you decide what information needs to be centralized?
Artificial intelligence (AI) projects are software-based initiatives that utilize machine learning, deep learning, natural language processing, computer vision, and other AI technologies to develop intelligent programs capable of performing various tasks with minimal human intervention.
We can think of model lineage as the specific combination of data and transformations on that data that create a model. This maps to the datacollection, data engineering, model tuning and model training stages of the data science lifecycle. So, we have workspaces, projects and sessions in that order.
This issue, and similar issues I’ve watched loved ones manage in the past, piqued my interest in healthcare data as a whole, particularly whole-person data. Healthcare data can and should serve as a holistic, actionable tool that empowers caregivers to make informed decisions in real time. Not for lack of caring!
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. RDD uses a key to partition data into smaller chunks.
.” In this article, you will find out what data labeling is, how it works, which data labeling types exist, and what best practices to follow to make this process smooth as glass. What is data labeling? The process of labeling objects in a picture via the LabelImg graphical image annotation tool.
Big Data holds the promise of changing how businesses and people solve real world problems and Crowdsourcing plays a vital role in managing big data. Let’s understand how crowdsourcing big data can revolutionize business processes. When we think of big data, we think of enterprise crowdsourcing.
A Data Engineer's primary responsibility is the construction and upkeep of a data warehouse. In this role, they would help the Analytics team become ready to leverage both structured and unstructured data in their model creation processes. They construct pipelines to collect and transform data from many sources.
Monitoring has given us a distinct advantage in our efforts to proactively detect and remove weak cryptographic algorithms and has assisted with our general change safety and reliability efforts. More generally, improved understanding helps us to make emergency algorithm migrations when a vulnerability of a primitive is discovered.
You might think that datacollection in astronomy consists of a lone astronomer pointing a telescope at a single object in a static sky. While that may be true in some cases (I collected the data for my Ph.D. thesis this way), the field of astronomy is rapidly changing into a data-intensive science with real-time needs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content