This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example: Text Data: Natural Language Processing (NLP) techniques are required to handle the subtleties of human language, such as slang, abbreviations, or incomplete sentences. Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets.
Particularly, we’ll explain how to obtain audio data, prepare it for analysis, and choose the right ML model to achieve the highest prediction accuracy. But first, let’s go over the basics: What is the audio analysis, and what makes audio data so challenging to deal with. Labeling of audio data in Audacity.
But today’s programs, armed with machine learning and deep learning algorithms, go beyond picking the right line in reply, and help with many text and speech processing problems. For example, tokenization (splitting text data into words) and part-of-speech tagging (labeling nouns, verbs, etc.) Preparing an NLP dataset.
A large hospital group partnered with Intel, the world’s leading chipmaker, and Cloudera, a Big Data platform built on Apache Hadoop , to create AI mechanisms predicting a discharge date at the time of admission. The built-in algorithm learns from every case, enhancing its results over time. Datapreparation for LOS prediction.
Tableau Prep is a fast and efficient datapreparation and integration solution (Extract, Transform, Load process) for preparingdata for analysis in other Tableau applications, such as Tableau Desktop. simultaneously making raw data efficient to form insights. Connecting to Data Begin by selecting your dataset.
Data engineers are programmers that create software solutions with big data. They’re integral specialists in data science projects and cooperate with data scientists by backing up their algorithms with solid data pipelines. Juxtaposing data scientist vs engineer tasks. Datapreparation and cleaning.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured data collection that is stored and accessed electronically.
GitHub Copilot Features AI-Powered Coding Assistant : Trained on a massive dataset of publicly available code, including GitHub repositories, it can generate functions, classes, and entire code blocks. Boosts Productivity : Helps write new code, refactor existing code, and auto-generates boilerplate, test cases, and even complex algorithms.
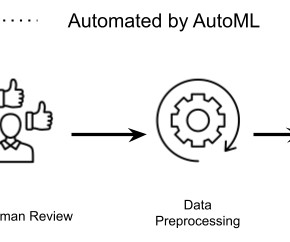
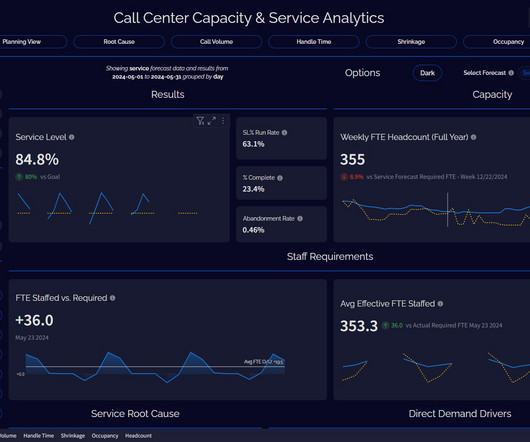
AutoML for content abuse detection at LinkedIn Figure 1: Demonstrating high-level steps of the AutoML framework While building content moderation classifiers to detect policy-violating content, we observed that the most significant performance improvements often didn't arise from radically different algorithms or groundbreaking innovations.
Image classification , a subfield of computer vision helps in processing and classifying objects based on trained algorithms. Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. instead of handwritten digits.
On the other hand, data science is a technique that collects data from various resources for datapreparation and modeling for extensive analysis. Cloud Computing provides storage, scalable compute, and network bandwidth to handle substantial data applications.
In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about datapreparation. Why PrepareData for Machine Learning Models? We need to format it to be suitable for machine learning algorithms.
This blog post will delve into the challenges, approaches, and algorithms involved in hotel price prediction. Hotel price prediction is the process of using machine learning algorithms to forecast the rates of hotel rooms based on various factors such as date, location, room type, demand, and historical prices. Data relevance.
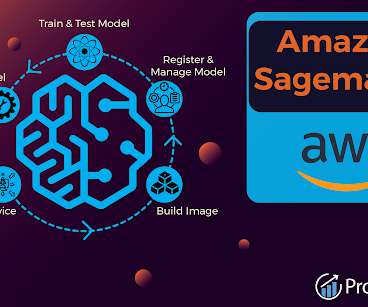
They were able to use SageMaker's pre-built algorithms and libraries to quickly and easily train their ML models and then deploy them to the edge (i.e., SageMaker also supports building customized algorithms and frameworks and allows for flexible distributed training options.
When many businesses start their journey into ML and AI, it’s common to place a lot of energy and focus on the coding and data science algorithms themselves. In August 2020 we released CDP Data Engineering (DE) — our answer to enabling fast, optimized, and automated data engineering for analytic workloads.
Training neural networks and implementing them into your classifier can be a cumbersome task since they require knowledge of deep learning and quite large datasets. Stating categories and collecting training dataset. Before a model can classify any documents, it has to be trained on historical data tagged with category labels.
Propensity models rely on machine learning algorithms. Machines get trained to anticipate what actions customers are likely to take next by finding patterns in past customer behavior data and use them when exposed to new data inputs. Collecting relevant data. Preparingdata for modeling. Deploying a model.
On the surface, ML algorithms take the data, develop their own understanding of it, and generate valuable business insights and predictions — all without human intervention. It boosts the performance of ML specialists relieving them of repetitive tasks and enables even non-experts to experiment with smart algorithms.
SageMaker, on the other hand, works well with other AWS services and provides a sound foundation to deal with large datasets and computations effectively. With possibilities like managed notebooks, integrated ML algorithms, and auto-tuning of your models.
Top 20 Python Projects for Data Science Without much ado, it’s time for you to get your hands dirty with Python Projects for Data Science and explore various ways of approaching a business problem for data-driven insights. 1) Music Recommendation System on KKBox Dataset Music in today’s time is all around us.
Top 5 Loan Prediction Datasets to Practice Loan Prediction Projects Univ.AI Top 5 Loan Prediction Datasets to Practice Loan Prediction Projects Univ.AI Top 5 Loan Prediction Datasets to Practice Loan Prediction Projects Univ.AI Which algorithm is best for Loan Prediction using Machine Learning?
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, data lakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
Machine Learning Software Engineers are at the forefront of this revolution, applying their expertise to develop intelligent systems and algorithms. DataPreparation: The Machine Learning Engineer Software engineers get, clean, and process data so that it can be used in machine learning models.
Machine learning employs sophisticated algorithms to anticipate future trends and accurately predict ADRs for hotels and vacation rentals. For example, at AltexSoft, our team developed two algorithms to support Rakuten Travel , Japan’s leading online booking platform that owns several hotels. Data shortage and poor quality.
Datasetpreparation and construction. The starting point of any machine learning task is data. A lot of data, to be exact. A lot of quality data, to be even more exact. To learn the basics, you can read our dedicated article on how data is prepared for machine learning or watch a short video.
A label or a tag is a descriptive element that tells a model what an individual data piece is so it can learn by example. In this case, the training dataset will consist of multiple songs with labels showing genres like pop, jazz, rock, etc. So, what challenges does data labeling involve? Data labeling challenges.
Overfitting occurs when an ML model yields accurate results for training examples but not for unseen data. It can be prevented in many ways, for instance, by choosing another algorithm, optimizing the hyperparameters, and changing the model architecture. Table of Contents What is Data Augmentation in Deep Learning?
Data analysis involves data cleaning. Results of data mining are not always easy to interpret. Data analysts interpret the results and convey the to the stakeholders. Data mining algorithms automatically develop equations. Data analysts have to develop their own equations based on the hypothesis.
In this article, we’ll share insights from the Advanced Analytics and Algorithms (AAA) team’s two-day hackathon, where one of the hackathon teams explored and benchmarked three different types of models for large-scale routing of customer feedback with text classification.
Data mining is analysing large volumes of data available in the company’s storage systems or outside to find patterns to help them improve their business. The process uses powerful computers and algorithms to execute statistical analysis of data. They fine-tune the algorithm at this stage to get the best results.
Supervised learning is training a machine learning model using the labeled dataset. Organic labels are often available in data, but a process may involve a human expert that adds tags to raw data to show a model the target attributes (answers). Supervised vs unsupervised vs semi-supervised machine learning in a nutshell.
AI in a nutshell Artificial Intelligence (AI) , at its core, is a branch of computer science that focuses on developing algorithms and computer systems capable of performing tasks that typically require human intelligence. Deep Learning is a subset of machine learning that focuses on building complex algorithms named deep neural networks.
It supports various algorithms, such as supervised, unsupervised, and reinforcement learning, allowing users to create predictive models for tasks such as classification, regression, and clustering. Now, let’s walk through a typical workflow: You start by collecting data from various sources and storing it in Azure.
In this blog post, we will look at some of the world's highest paying data science jobs, what they entail, and what skills and experience you need to land them. What is Data Science? Data science also blends expertise from various application domains, such as natural sciences, information technology, and medicine.
As with other traditional machine learning and deep learning paths, a lot of what the core algorithms can do depends upon the support they get from the surrounding infrastructure and the tooling that the ML platform provides. they were able to reframe the problem as a straight-forward black-box optimization problem.
You cannot expect your analysis to be accurate unless you are sure that the data on which you have performed the analysis is free from any kind of incorrectness. Data cleaning in data science plays a pivotal role in your analysis. It’s a fundamental aspect of the datapreparation stages of a machine learning cycle.
By examining these factors, organizations can make informed decisions on which approach best suits their data analysis and decision-making needs. Parameter Data Mining Business Intelligence (BI) Definition The process of uncovering patterns, relationships, and insights from extensive datasets.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
Data Preprocessing: Prepare and clean the data. This may include handling missing values, outliers, and transforming the data into a format suitable for AI algorithms. Model Selection: Choose the appropriate AI algorithm or framework that aligns with the project's objectives.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. Explain the datapreparation process.
Netflix has built content recommendation algorithms that are responsible for 80% of the content streamed on their platform, saving the company $1B annually ( Dataconomy ). As operational databases were not designed for analytics, data is replicated to Rockset and automatically indexed for fast search, aggregations and joins.
It’s a study of Computer Algorithms, which helps self-improvement through experiences. It builds a model based on Sample data and is designed to make predictions and decisions without being programmed for it. Artificial Intelligence is achieved through the techniques of Machine Learning and Deep Learning.
In addition to analytics and data science, RAPIDS focuses on everyday datapreparation tasks. This features a familiar DataFrame API that connects with various machine learning algorithms to accelerate end-to-end pipelines without incurring the usual serialization overhead. Trino Source: trino.io
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content