This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Bronze layers can also be the raw database tables. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. This week I discovered SQLMesh , a all-in-one data pipelines tool. Rare footage of a foundation model ( credits ) Fast News ⚡️ Twitter's recommendation algorithm — It was an Elon tweet. I hope he will fill the gaps.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. This week I discovered SQLMesh , a all-in-one data pipelines tool. Rare footage of a foundation model ( credits ) Fast News ⚡️ Twitter's recommendation algorithm — It was an Elon tweet. I hope he will fill the gaps.
Structured data can be defined as data that can be stored in relational databases, and unstructured data as everything else. Deep Learning, a subset of AI algorithms, typically requires large amounts of human annotated data to be useful. In other words, structured data has a pre-defined data model , whereas unstructured data doesn’t.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Modeling using multiple algorithms. Data Engineers are skilled professionals who lay the foundation of databases and architecture.
Storage and compute is cheaper than ever, and with the advent of distributed databases that scale out linearly, the scarcer resource is engineering time. The use of natural, human readable keys and dimension attributes in fact tables is becoming more common, reducing the need for costly joins that can be heavy on distributed databases.
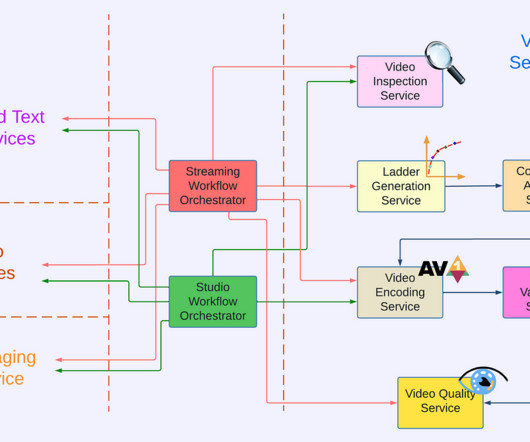
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use. You’ll have a few different data stores: The database that backs your main app. Ride database.
SQL – A database may be used to build data warehousing, combine it with other technologies, and analyze the data for commercial reasons with the help of strong SQL abilities. Data Engineers must be proficient in Python to create complicated, scalable algorithms. Skills Required To Be A Data Engineer.
Data engineers who previously worked only with relational database management systems and SQL queries need training to take advantage of Hadoop. Apache HBase , a noSQL database on top of HDFS, is designed to store huge tables, with millions of columns and billions of rows. Complex programming environment. Data storage options.
Retrieval augmented generation (RAG) is an architecture framework introduced by Meta in 2020 that connects your large language model (LLM) to a curated, dynamic database. Data retrieval: Based on the query, the RAG system searches the database to find relevant data. A RAG flow in Databricks can be visualized like this.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. Pipeline-Centric Engineer: These data engineers prefer to serve in distributed systems and more challenging projects of data science with a midsize data analytics team.
In large organizations, data engineers concentrate on analytical databases, operate data warehouses that span multiple databases, and are responsible for developing table schemas. Data engineering builds data pipelines for core professionals like data scientists, consumers, and data-centric applications.
We have heard news of machine learning systems outperforming seasoned physicians on diagnosis accuracy, chatbots that present recommendations depending on your symptoms , or algorithms that can identify body parts from transversal image slices , just to name a few. What makes a good Data Pipeline?
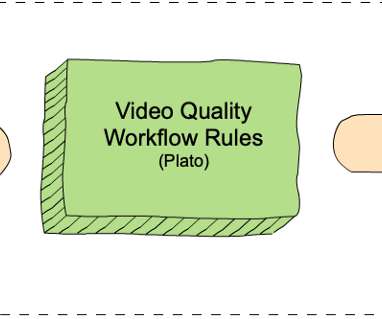
Moorthy and Zhi Li Introduction Measuring video quality at scale is an essential component of the Netflix streaming pipeline. This tight coupling means that it is not possible to achieve the following without re-encoding: A) rollout of new video quality algorithms B) maintaining the data quality of our catalog (e.g. by Christos G.
Its RecoverX distributed database backup product of latest version v2.0 RecoverX is described as app-centric and can back up applications data whilst being capable of recovering it at various granularity levels to enhance storage efficiency. now provides hadoop support.
The data from which these insights are extracted can come from various sources, including databases, business transactions, sensors, and more. Automating data analytics techniques and processes has led to the development of mechanical methods and algorithms used over raw data. What i s Data Science ?
The job of a Machine Learning Engineer is to maintain the software architecture, run data pipelines to ensure seamless flow in the production environment. An essential skill for both the job roles is familiarity with various machine learning and deep learning algorithms.
These backend tools cover a wide range of features, such as deployment utilities, frameworks, libraries, and databases. Better Data Management: Database management solutions offered by backend tools enable developers to quickly store, retrieve, and alter data. Software algorithms. Features: Specific programming problems.
Becoming an Azure Data Engineer in this data-centric landscape is a promising career choice. The main duties of an Azure Data Engineer are planning, developing, deploying, and managing the data pipelines. Master data integration techniques, ETL processes, and data pipeline orchestration using tools like Azure Data Factory.
Looking for a position to test my skills in implementing data-centric solutions for complicated business challenges. Example 6: A well-qualified Cloud Engineer is looking for a position responsible for developing and maintaining automated CI/CD and deploying pipelines to support platform automation.
It offers practical experience with streaming data, efficient data pipelines, and real-time analytics solutions. Appreciated Customer Experience: The industry focuses on customer-centric approaches to enhance the overall customer experience. It provides real-time data pipelines and integration with various data sources.
Combining efficient incident handling, establishing resilience by design, and strict adherence to SLOs are pivotal in ensuring our services remain resilient, reliable, stable, and user-centric. Now we use simulation-driven automated testing as a stage of our CI/CD pipeline, totaling over 900 pull requests since the release!
With its native support for in-memory distributed processing and fault tolerance, Spark empowers users to build complex, multi-stage data pipelines with relative ease and efficiency. The MLlib library in Spark provides various machine learning algorithms, making Spark a powerful tool for predictive analytics. Machine learning.
Dive into the fascinating world of user interfaces, business logic, and database stacks as you engage in hands-on learning through Cloud Labs. With Django, you will have the necessary infrastructure to create dynamic websites with database integration, content administration, file uploads, user authentication, and much more.
Dive into the fascinating world of user interfaces, business logic, and database stacks as you engage in hands-on learning through Cloud Labs. With Django, you will have the necessary infrastructure to create dynamic websites with database integration, content administration, file uploads, user authentication, and much more.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content