This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on July 28, 2025 in Machine Learning Image by Author | Ideogram # Introduction From your email spam filter to music recommendations, machine learning algorithms power everything. Perfect for beginners and busy devs who want a quick, clear overview.
By Jayita Gulati on July 16, 2025 in Machine Learning Image by Editor In data science and machine learning, raw data is rarely suitable for direct consumption by algorithms. Feature engineering can impact model performance, sometimes even more than the choice of algorithm itself. AutoML frameworks : Tools like Google AutoML and H2O.ai
If you are dealing with deep neural networks, you will surely stumble across a very known and widely used algorithm called Back Propagation Algorithm. This blog will give you a complete overview of the Back propagation algorithm from scratch. Table of Contents What is the Back Propagation Algorithm in Neural Networks ?
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. Interact with the data scientists team and assist them in providing suitable datasets for analysis. That needs to be done because raw data is painful to read and work with.
Feature Development Bottlenecks Adding new features or testing algorithmic variations required days-long backfill jobs. Feature joins across multiple datasets were costly and slow due to Spark-based workflows. Reward signal updates needed repeated full-dataset recomputations, inflating infrastructure costs.
But you do need to understand the mathematical concepts behind the algorithms and analyses youll use daily. Why it matters: Every dataset tells a story, but statistics helps you figure out which parts of that story are real. Calculate summary statistics and run relevant statistical tests on real-world datasets.
We’ll also paste the project description and attach the dataset. As you can see, ChatGPT summarizes the dataset by highlighting key columns, missing values, and then creates a correlation heatmap to explore relationships. Step 2: Data Cleaning Both datasets contain missing values. Use this dataset to predict [target variable].
This blog serves as a comprehensive guide on the AdaBoost algorithm, a powerful technique in machine learning. This wasn't just another algorithm; it was a game-changer. Before the AdaBoost machine learning model , most algorithms tried their best but often fell short in accuracy. Freund and Schapire had a different idea.
However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly. Incremental training : Foundation models are trained on extensive datasets, including every members history of plays and actions, making frequent retraining impractical.
Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets. Address challenges like noisy data, incomplete records, and mislabeled inputs to ensure high-quality datasets. Identify and mitigate biases within datasets, ensuring fair and ethical AI outcomes.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. Data Normalization Data normalization is the process of adjusting related datasets recorded with different scales to a common scale, without distorting differences in the ranges of values.
Suppose you’re among those fascinated by the endless possibilities of deep learning technology and curious about the popular deep learning algorithms behind the scenes of popular deep learning applications. Table of Contents Why Deep Learning Algorithms over Traditional Machine Learning Algorithms? What is Deep Learning?
Data engineering tools are specialized applications that make building data pipelines and designing algorithms easier and more efficient. Spark uses Resilient Distributed Dataset (RDD), which allows it to keep data in memory transparently and read/write it to disc only when necessary.
You can configure your model deployment to handle those frequent algorithm-to-algorithm calls, and this ensures that the correct algorithms are running smoothly and computation time is minimal. Machine learning algorithms make big data processing faster and make real-time model predictions extremely valuable to enterprises.
Clustering algorithms are a fundamental technique in machine learning used to identify patterns and group data points based on similarity. This blog will explore various clustering algorithms and their applications, including K-Means, Hierarchical clustering, DBSCAN, and more. What are Clustering Algorithms in Machine Learning?
Customer Churn Prediction with SageMaker Studio XGBoost Algorithm 2. Linear Regression with Amazon SageMaker XGBoost Algorithm 8. The Orchestrator uploads model artifacts, training data, and algorithm zip files into the S3 assets bucket. Using SageMaker Processing and Fargate to Execute a Dask job 3.
Project Solution Approach: To build the House Price Prediction project using AWS and ML, you can start by collecting a dataset of relevant features that affect the price of a house, such as location, square footage, number of bedrooms and bathrooms, etc. Theoretical knowledge is not enough to crack any Big Data interview.
Powered by MLflow 3, Agent Bricks automatically creates evaluation datasets and custom judges tailored to your task. Automatic evaluation : Agent Bricks will then automatically create evaluation benchmarks specific to your task, which may involve synthetically generating new data or building custom LLM judges.
How it helps : When youre tweaking hyperparameters and testing different algorithms, keeping track of what worked becomes impossible without proper tooling. DVC: Data Version Control What it solves : Managing large datasets and complex data transformations. How it helps : Git breaks when you try to version control large datasets.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. This article will focus on explaining the contributions of generative AI in the future of telecommunications services.
The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment. For instance, suppose a new dataset from an IoT device is meant to be ingested daily into the Bronze layer. How do you ensure data quality in every layer?
Brilliant algorithms, cutting-edge models, massive computing power, all undermined by one overlooked factor. Data scientists expect clean, consistent datasets but inherit years of technical debt scattered across disconnected software. They need consistent formats, complete datasets, and ongoing quality checks.
This bias can be introduced at various stages of the AI development process, from data collection to algorithm design, and it can have far-reaching consequences. For example, a biased AI algorithm used in hiring might favor certain demographics over others, perpetuating inequalities in employment opportunities.
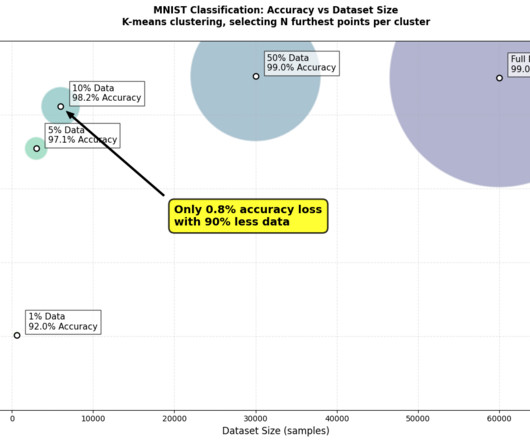
Best runs for furthest-from-centroid selection compared to full dataset. In my recent experiments with the MNIST dataset, thats exactly what happened. Data PruningResults The plot above shows the models accuracy compared to the training dataset size when using the most effective pruning method Itested. Image byauthor.
RAW Hollow is an innovative in-memory, co-located, compressed object database developed by Netflix, designed to handle small to medium datasets with support for strong read-after-write consistency. By holding an entire dataset in memory, you can eliminate an entire class of problems. seconds to ~0.4 Caching is complicated.
Testing & Evaluation: Collect user feedback and annotate runs to build high-quality test datasets. Test & Evaluate: Use LangSmith to collect interesting edge cases and create test datasets. Run automated evaluations to measure performance and prevent regressions. Visualize and debug the complex flow with LangGraph Studio.
In data science, algorithms are usually designed to detect and follow trends found in the given data. You can train machine learning models can to identify such out-of-distribution anomalies from a much more complex dataset. The modeling follows from the data distribution learned by the statistical or neural model.
This groundbreaking technique augments existing datasets and ensures the protection of sensitive information, making it a vital tool in industries ranging from healthcare and finance to autonomous vehicles and beyond. Synthetic data generation allows for the creation of large, diverse datasets that can fill these gaps.
Similarly, companies with vast reserves of datasets and planning to leverage them must figure out how they will retrieve that data from the reserves. Work in teams to create algorithms for data storage, data collection, data accessibility, data quality checks, and, preferably, data analytics. are prevalent in the industry.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Has a lot of useful built-in algorithms. Spark applies a function to each record in the dataset.
It offers fast SQL queries and interactive dataset analysis. With the BigQuery BI Engine, an in-memory analysis engine that enables sub-second query response time and high concurrency, you can interactively analyze massive, complex datasets. Google BigQuery BigQuery is a fully-managed, serverless cloud data warehouse by Google.
Data preparation for machine learning algorithms is usually the first step in any data science project. This blog covers all the steps to master data preparation with machine learning datasets. In building machine learning projects , the basics involve preparing datasets. Usually, you will come across files of different types.
For example, consider the Australian Wine Sales dataset containing information about the number of wines Australian winemakers sold every month for 1980-1995. Regression Models Regression models include popular algorithms like linear regression vs logistic regression , etc. to solve time series analysis problems.
The Role of GenAI in the Food and Beverage Service Industry GenAI leverages machine learning algorithms to analyze vast datasets, generate insights, and automate tasks that were previously labor-intensive. GenAIs ability to analyze vast datasets ensures quick identification of irregularities.
Resilient Distributed Datasets (RDDs) are a fundamental abstraction in PySpark, designed to handle distributed data processing tasks. In-Memory Computation: RDDs support in-memory data storage and caching, significantly enhancing performance for iterative algorithms and repeated computations.
It means biased hiring algorithms, flawed medical diagnoses, and financial models that miss critical risks. Machine learning algorithms find patterns in whatever data you provide. The problem isn’t the algorithm. Customer segmentation algorithms miss emerging demographics. The stakes have never been higher.
For that purpose, we need a specific set of utilities and algorithms to process text, reduce it to the bare essentials, and convert it to a machine-readable form. A stemming algorithm simply maps the variant of a word to its stem (the base form). Nevertheless, the nltk stemmer gives us at least three stemming algorithms to choose from.
Certify your datasets 6. To treat any data asset as a product means combining a useful dataset with product management, a domain semantic layer, business logic, and access to deliver a final product thats appropriate and reliable for a given business use-case. Data contracts can help keep a log of changes to a dataset as well.
The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months. This meant business teams were operating with less-than-ideal data, and once an incident was detected, the team had to spend painstaking hours reassembling and backfilling datasets.
The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months. This meant business teams were operating with less-than-ideal data, and once an incident was detected, the team had to spend painstaking hours reassembling and backfilling datasets.
Performance: Graph databases are optimized for traversing and querying relationships, delivering exceptional performance even with massive datasets. Graph algorithms play a crucial role in how graph databases operate, as they are designed to analyze the structure and properties of graphs. How to Choose a Graphical Database?
They consider data science to be a challenging domain to pursue because it has to do a lot with implementing complex algorithms. The first step in a machine learning project is to explore the dataset through statistical analysis. After careful analysis, one decides which algorithms should be used.
SageMaker also provides a collection of built-in algorithms, simplifying the model development process. Its automated machine learning (AutoML) capabilities assist in selecting the right algorithms and hyperparameters for a given problem. It offers scalable, secure, and reliable storage for datasets of any size.
It can be prevented in many ways, for instance, by choosing another algorithm, optimizing the hyperparameters, and changing the model architecture. Ultimately, the most important countermeasure against overfitting is adding more and better quality data to the training dataset. Why is Data Augmentation Important in Deep Learning?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content