This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Machine learning uses algorithms that comb through data sets and continuously improve the machine learning model.
Demand Forecasting – Companies must move beyond basic demand forecasting using only historical transaction data to leveraging real-time datasets and external consumer demand signals. The pandemic has been a call to action for both the manufacturing and retail industries and that is the bottom line with COVID. Brent Biddulph: .
The Role of GenAI in the Food and Beverage Service Industry GenAI leverages machine learning algorithms to analyze vast datasets, generate insights, and automate tasks that were previously labor-intensive. GenAIs ability to analyze vast datasets ensures quick identification of irregularities.
Manufacturing has always been at the cutting edge of technology since it drives economic growth and societal changes. It can revolutionize manufacturing processes, product development and supply chain management. This article examines how GenAI transforms manufacturing by discussing its application, benefits, challenges and prospects.
These models are trained on vast datasets which allow them to identify intricate patterns and relationships that human eyes might overlook. From a technical standpoint, generative AI models depend on various architectures and algorithms to achieve their remarkable creative capabilities. stock market trends).
By developing algorithms that can recognize patterns automatically, repetitive, or time-consuming tasks can be performed efficiently and consistently without manual intervention. Data analysis and Interpretation: It helps in analyzing large and complex datasets by extracting meaningful patterns and structures.
Aiming at understanding sound data, it applies a range of technologies, including state-of-the-art deep learning algorithms. Audio analysis has already gained broad adoption in various industries, from entertainment to healthcare to manufacturing. The Fast Fourer Transform (FFT) is the algorithm computing the Fourier transform.
Machine learning is a field that encompasses probability, statistics, computer science and algorithms that are used to create intelligent applications. Since machine learning is all about the study and use of algorithms, it is important that you have a base in mathematics. It works on a large dataset.
Machine learning algorithms produce these suggestions. Data-driven optimisation algorithms coordinate the complex dance of logistics, delivery schedules, and cost economies. This procedure is tricky and requires extensive data reading and filtering through a machine learning algorithm. Thinking about Amazon and Netflix?
For instance, a manufacturer that places sensors on equipment to capture data should have a plan for that data. After all, AI and it’s practice of machine learning (ML), use algorithms to accomplish tasks. Those algorithms require high quality data to deliver meaningful results. Will the data have other uses?
Data scientists can now supercharge their training efforts and efficiently train models over datasets of 100s of GB or more! We demonstrate how, using a PyTorch-based recommendation algorithm, you can train and deploy a model to do exactly that. See this quickstart to learn more.
Specific Skills and Knowledge: Some skills that may be useful in this field include: Statistics, both theoretical and applied Analysis and model construction using massive datasets and databases Computing statistics Statistics-based learning C. In contrast to unsupervised learning, supervised learning makes use of labeled datasets.
By 2027, 30 percent of manufacturers will use generative AI to enhance their product development effectiveness. Generative AI refers to unsupervised and semi-supervised machine learning algorithms that enable computers to use existing content like text, audio and video files, images, and even code to create new possible content.
If data scientists and analysts are pilots, data engineers are aircraft manufacturers. Moreover, this project concept should highlight the fact that there are many interesting datasets already available on services like GCP and AWS. Large datasets containing photos and captions that are correlated must be managed.
And it turns out that image and video cameras, although making a relatively small portion of all manufactured sensors, are reported to produce the most data among sensors. Deep Learning, a subset of AI algorithms, typically requires large amounts of human annotated data to be useful. Data annotation. Data scrutiny.
Similarly, in Machine learning, selecting the correct number of features for fitting a predictive model to a given dataset is essential. Feature Selection Algorithms How to do Feature Selection? But, what are the benefits of using feature selection algorithms? Why use Feature Selection Techniques? Let us find out.
Data processing can be done using statistical techniques, algorithms, scientific approaches, various technologies, etc. Manufacturing Process Optimization The distinction between the physical and digital worlds has become more ambiguous due to data science applications in industrial industries. Analyzing medical images is one of them.
For example, quantum computers could be used to crack highly secure encryption algorithms. However, with advancements in technology and huge datasets to analyze, the field is making big strides in how it can be used. Manufacturers need to guard against hackers who may try to steal information or cause physical damage.
Recognizing the difference between big data and machine learning is crucial since big data involves managing and processing extensive datasets, while machine learning revolves around creating algorithms and models to extract valuable information and make data-driven predictions.
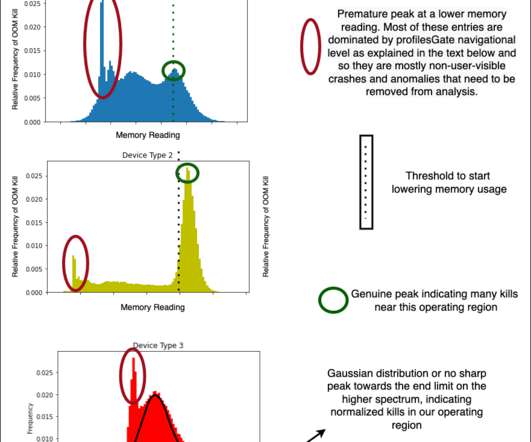
This is done by first elaborating on the dataset curation stage?—?specially We also explore graphical analysis of the labeled dataset and suggest some feature engineering and accuracy measures for future exploration. The dataset will thus be very biased/skewed. device capabilities/characteristics and runtime memory data.
A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. Business Intelligence tools, therefore cannot process this vast spectrum of data alone, hence we need advanced algorithms and analytical tools to gather insights from these data. Data Modeling using multiple algorithms. What is Data Science?
AI has risen as the stepping stone of innovation, which enables manufacturers to enhance vehicle safety, efficiency, and user experience. Advanced AI algorithms combined with big data analytics have revolutionized the way researchers model complex scenarios and optimize vehicle performance.
To obtain a data science certification, candidates typically need to complete a series of courses or modules covering topics like programming, statistics, data manipulation, machine learning algorithms, and data analysis. All the data science algorithms and concepts find their implementation in either Python or R.
soft or hard skill), descriptions of the skill (“the study of computer algorithms…”), and more. Polyheirerchy represented as parent-child relationships In the child-parent example above (Figure 2) we see the skill “Supply Chain Automation” linked to “Supply Chain Engineering” as its parent, which is linked to “Engineering” and “Manufacturing.”
Projects help you create a strong foundation of various machine learning algorithms and strengthen your resume. Each project explores new machine learning algorithms, datasets, and business problems. In this ML project, you will learn to implement the random forest regressor and Xgboost algorithms to train the model.
Your project proposal should include a description of your data science project , as well as statistics about the size and complexity of your dataset. Alcrowd Alcrowd is a new algorithmic competition where participants compete to solve complex tasks. Once you've registered, you'll need to submit a project proposal.
In data science, algorithms are usually designed to detect and follow trends found in the given data. You can train machine learning models can to identify such out-of-distribution anomalies from a much more complex dataset. The modeling follows from the data distribution learned by the statistical or neural model.
Regulatory Data Where data supports regulatory compliance processes such as those that govern food or pharmaceutical manufacturing, data corruption will render the affected products unfit for use and require either additional testing to prove compliance or, more likely, their destruction.
Go for the best Big Data courses and work on ral-life projects with actual datasets. Risk Management: By using big data to analyze a variety of datasets, risks associated with credit scoring, investment portfolios, and market volatility may be assessed and managed, assisting in the development of efficient risk reduction techniques.
Getting Trained on Data: To perform any task, first, the generative AI models need to be trained on massive datasets of existing content. Recognising Patterns: The algorithm then recognises patterns and relationships between various data sets based on all the retrieved training data.
Machine learning models rely heavily on large and diverse datasets to train and improve their ability to understand and interpret visual information. Achieving this level of sophistication demands an extensive dataset that mirrors real-world scenarios.
Neural network based multi-objective evolutionary algorithm for dynamic workflow scheduling in cloud computing Cloud computing research topics are getting wider traction in the Cloud Computing field. The NN-MOEA algorithm utilizes neural networks to optimize multiple objectives, such as planning, cost, and resource utilization.
Walmart runs a backend algorithm that estimates this based on the distance between the customer and the fulfillment center, inventory levels, and shipping methods available. It uses Machine learning algorithms to find transactions with a higher probability of being fraudulent.
Furthermore, solving difficult problems in data science not only prepares you for the future but also teaches you the latest tools, techniques, algorithms and packages that have been introduced in the industry. Two Sigma Investments is a firm implementing data science tools over datasets for predicting financial trade since 2001.
Data validation involves checking data for errors, inconsistencies, and inaccuracies, often using predefined rules or algorithms. In industries such as healthcare, finance, and manufacturing, the importance of data accuracy and data integrity is even more pronounced. There are various ways to ensure data accuracy.
A machine learning framework is a tool that lets software developers, data scientists, and machine learning engineers build machine learning models without having to dig into the underlying working principle(math and stat) of the machine learning algorithms. It bundles a vast collection of data structures and ML algorithms.
Data quality analyst skills and tools Like data analysts, data quality analysts must be adept at separating meaningful trends and information from larger datasets. Healthcare, manufacturing, and insurance were all well represented within the job listings as well. Data quality, afterall, is contextual to the use case.
Most of today’s edge AI algorithms perform local inference directly on data that the device sees directly. Using data from a collection of sensors adjacent to the device, more sophisticated inference tools can get developed in the future. Improved edge AI arrangement could also be a significant change.
As we step into the latter half of the present decade, we can’t help but notice the way Big Data has entered all crucial technology-powered domains such as banking and financial services, telecom, manufacturing, information technology, operations, and logistics. Data Integration 3.Scalability Scalability 4.Link Link Prediction 5.Cloud
Feature Engineering — Talk about the approach you took to select the essential features and how you derived new ones by adding more meaning to the dataset flow. Since this is a classification problem, I will check the prediction using the Decision trees and Random forest as this algorithm tends to do better for classification problems.
This type of analysis is particularly relevant in industries such as manufacturing and logistics. Here are a few project ideas that are suitable for beginners: Analyzing a dataset to identify trends and patterns: One of the most common projects for beginners is to analyze a dataset to identify trends and patterns.
It supports various algorithms, such as supervised, unsupervised, and reinforcement learning, allowing users to create predictive models for tasks such as classification, regression, and clustering. Next, you develop your model using Azure Machine Learning, experimenting with different algorithms and techniques.
They are used in a wide range of businesses and areas, including banking, healthcare, e-commerce, and manufacturing. Columnar stores, such as Apache Cassandra and Apache HBase, organize data by columns rather than rows, allowing for faster read and write operations on huge datasets. Spatial Database (e.g.-
Detecting cancerous cells in microscopic photography of cells (Whole Slide Images, aka WSIs) is usually done with segmentation algorithms, which NNs are very good at. To store this data, hospitals are often equipped with on-premises infrastructure, more or less provided by the same manufacturer of the capture devices. _slides_specs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content