This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
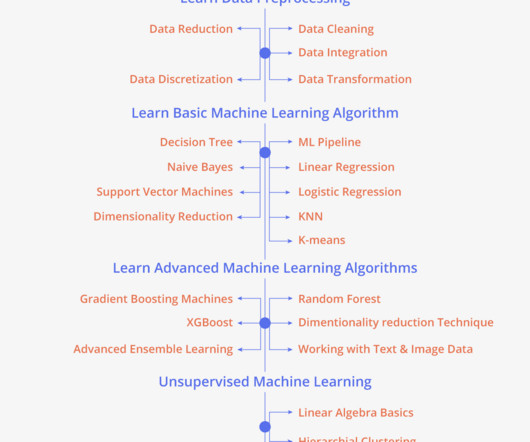
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Machine learning uses algorithms that comb through data sets and continuously improve the machine learning model.
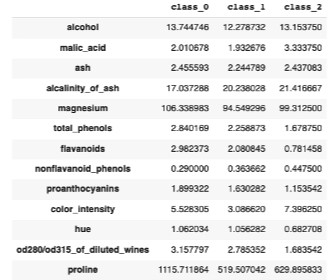
Types of Machine Learning: Machine Learning can broadly be classified into three types: Supervised Learning: If the available dataset has predefined features and labels, on which the machine learning models are trained, then the type of learning is known as Supervised Machine Learning. A sample of the dataset is shown below.
Everyday the global healthcare system generates tons of medical data that — at least, theoretically — could be used for machine learning purposes. In this post, we’ll briefly discuss challenges you face when working with medical data and make an overview of publucly available healthcare datasets, along with practical tasks they help solve.
This article describes how data and machine learning help control the length of stay — for the benefit of patients and medical organizations. The length of stay (LOS) in a hospital , or the number of days from a patient’s admission to release, serves as a strong indicator of both medical and financial efficiency. Factors impacting LOS.
Open-source models are often pre-trained on big datasets, allowing developers to fine-tune them for specific tasks or industries. Pre-trained Models : These models are pre-trained on large-scale datasets, saving developers significant time and resources while also enabling the use of transfer learning.
Pattern recognition is used in a wide variety of applications, including Image processing, Speech recognition, Biometrics, Medical diagnosis, and Fraud detection. And is used in a wide variety of applications, including image processing, speech recognition, and medical diagnosis.
They are algorithms that assist users in finding information that is pertinent to them. Applications Technology Giants Advertising Firms Handwritten Digit Recognition Artificial neural networks are used to build a system that correctly decodes handwritten numbers. They help banks save money by cutting labor expenses.
Detecting cancerous cells in microscopic photography of cells (Whole Slide Images, aka WSIs) is usually done with segmentation algorithms, which NNs are very good at. To allow innovation in medical imaging with AI, we need efficient and affordable ways to store and process these WSIs at scale. _slides_specs. items ( ) : with fsspec.
These models are trained on vast datasets which allow them to identify intricate patterns and relationships that human eyes might overlook. From a technical standpoint, generative AI models depend on various architectures and algorithms to achieve their remarkable creative capabilities.
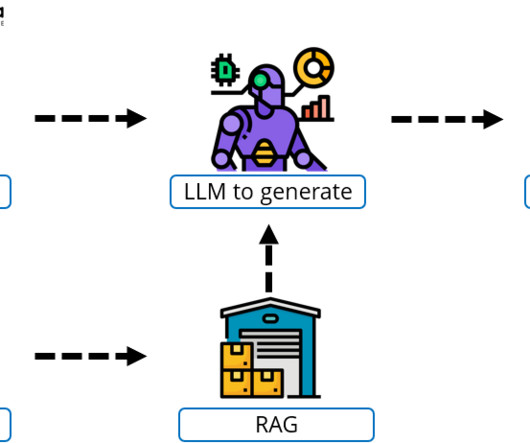
Because they are trained on huge datasets and have billions of factors. RAG retrieves medical guidelines or research papers and generates patient-specific advice or summaries for healthcare providers. Healthcare RAG system needs extensive medicaldatasets and context-aware retrieval for accuracy.
Data imputation is the method of filling in missing or unavailable information in a dataset with other numbers. Impacts on the Final Model Missing data may lead to bias in the dataset, which could affect the final model’s analysis. What Is Data Imputation? This process is important for keeping data analysis accurate.
Today, we will delve into the intricacies the problem of missing data , discover the different types of missing data we may find in the wild, and explore how we can identify and mark missing values in real-world datasets. Image by Author. Let’s consider an example. Image by Author. Image by Author.
By learning from historical data, machine learning algorithms autonomously detect deviations, enabling timely risk mitigation. Machine learning offers scalability and efficiency, processing large datasets quickly. A dataset's anomalies may provide valuable information about inconsistencies, mistakes, fraud, or unusual events.
Aiming at understanding sound data, it applies a range of technologies, including state-of-the-art deep learning algorithms. Another application of musical audio analysis is genre classification: Say, Spotify runs its proprietary algorithm to group tracks into categories (their database holds more than 5,000 genres ).
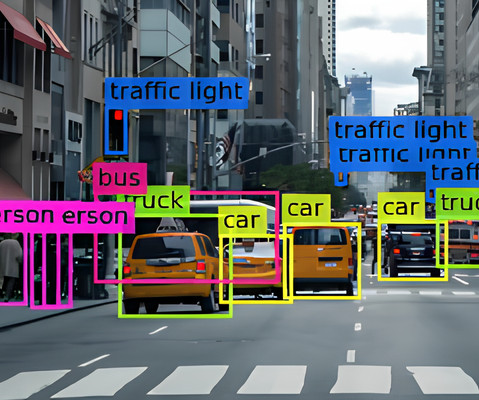
With the advancement in artificial intelligence and machine learning and the improvement in deep learning and neural networks, Computer vision algorithms can process massive volumes of visual data. With no future adieu, let's look at some of the most commonly used computer vision algorithms and applications.
CycleGAN, unlike traditional GANs, does not require paired datasets, in which each image in one domain corresponds to an image in another. Problem With Image-to-Image Translation Traditional picture-to-image translation algorithms, such as Pix2Pix, need paired datasets, in which each input image corresponds to a target image.
Its deep learning natural language processing algorithm is best in class for alleviating clinical documentation burnout, which is one of the main problems of healthcare technology. It can be manually transformed into structured data by hospital staff, but it’s never a priority in the medical setting. Medical transcription.
Data science is the application of scientific methods, processes, algorithms, and systems to analyze and interpret data in various forms. They can work with various tools to analyze large datasets, including social media posts, medical records, transactional data, and more. What Is Data Science?
The main agenda is to remove the redundant and dependent features by changing the dataset onto a lower-dimensional space. variables) in a particular dataset while retaining most of the data. Logistic Regression is a simple and powerful linear classification algorithm. In simple terms, they reduce the dimensions (i.e.
CHG Healthcare , a healthcare staffing company with over 45 years of industry expertise, uses AI/ML to power its workforce staffing solutions across 700,000 medical practitioners representing 130 medical specialties. We demonstrate how, using a PyTorch-based recommendation algorithm, you can train and deploy a model to do exactly that.
It involves analyzing vast amounts of health-related data, including health records, medical images, and genetic information, using machine learning algorithms, natural language processing, computer vision, and other AI technologies to enhance the health of patients, lower costs, and boost the effectiveness of the delivery of healthcare.
For instance, sales of a company, medical records of a patient, stock market records, tweets, Netflix’s list of programs, audio files on Spotify, log files of a self-driven car, your food bill from Zomato, and your screen time on Instagram. There is a much broader spectrum of things out there which can be classified as data.
Image classification , a subfield of computer vision helps in processing and classifying objects based on trained algorithms. Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. instead of handwritten digits.
It has completely changed our approach to medical diagnosis, treatment, and remote patient care. From medical image analysis to drug discovery and personalized treatment, Generative AI is revolutionizing global health initiatives and telemedicine. This is applied to the healthcare sector as well.
FSL uses this idea to help with situations where it is hard, costly, or almost impossible to collect data, like: Finding rare diseases when there isn’t much medical image data available. Training the Similarity Function A big-named dataset like ImageNet is used to teach the model how to understand similarities in a supervised way.
It improves accessibility, encourages innovation for greater value, lowers disparities in research and treatment, and harnesses large-scale medical data analysis to create new data. Revolutionizing Clinical Trials through AI Generative AI is transforming medical research. This reduces the amount of time and money needed.
Digitizing medical reports and other records is one of the critical tasks for medical institutions to optimize their document flow. But some healthcare organizations like FDA implement various document classification techniques to process tons of medical archives daily. Stating categories and collecting training dataset.
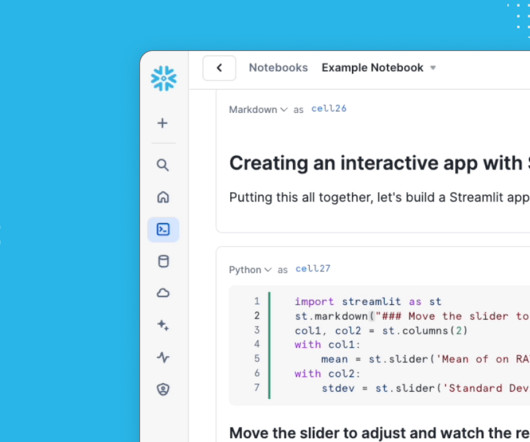
This would help you lead teams, build predictive models, identify trends, and provide recommendations to management based on findings from the data analysed using advanced statistics, machine learning algorithms, mathematical models, and techniques. Code example and the link to the dataset for this project can be found in this source code.
Data science is the application of scientific methods, processes, algorithms, and systems to analyze and interpret data in various forms. They can work with various tools to analyze large datasets, including social media posts, medical records, transactional data, and more. What Is Data Science?
AI requires good data and strong training algorithms, such as through machine learning, to make decisions about what data to send back to decision-makers. “Maybe you could have multiple destinations on Earth with the same dataset, doing different things.”
Suppose you’re among those fascinated by the endless possibilities of deep learning technology and curious about the popular deep learning algorithms behind the scenes of popular deep learning applications. Table of Contents Why Deep Learning Algorithms over Traditional Machine Learning Algorithms? What is Deep Learning?
Machine learning is a way in which artificial intelligence is used to train algorithms or computers. Machine learning algorithms can analyze potentially tera bytes of data, identify patterns from these data, and make predictions or decisions. But how is machine learning used in healthcare?
Emerging technology and the utilization of real-time data enable medical professionals to monitor a patient’s prognosis quickly and with minimal interruption. The best part is that it enables prompt intervention, allowing medical professionals to take a proactive rather than reactive approach to healthcare.
Data science in pharmaceutical industry is extensively used to improve its operations through applications such as predictive modeling, segmentation analysis, machine learning algorithms, visualization tools, etc., which help improve decision-making processes. This helps the companies keep a check on their production pipeline.
Fig: 1: Image Annotation Challenges of manual Annotation Complications in manually annotating visual data: It is Time-consuming and labor-intensive, especially for large datasets. Scalability limitations which make it impractical for large datasets. Initially, we used a custom dataset focused on potholes.
Machine Learning algorithms can help overcome these challenges by automatically detecting patterns in the data. . Together they can help machines learn how to recognize patterns in complex datasets and make valuable predictions. Doctors now have vast amounts of patient data thanks to modern medical technology. billion to $209.91
It is the combination of statistics, algorithms and technology to analyze data. Second, data scientists must be expert programmers and be able to wrangle large datasets, build complex algorithms, and run simulations. They work with vast amounts of data, including customer, financial, and medical records.
Data processing can be done using statistical techniques, algorithms, scientific approaches, various technologies, etc. Medical Image Analysis Data science applications in healthcare or Medical science have several uses. Analyzing medical images is one of them. As time passes, search engines like Google, Yahoo, Bing, etc.,
Specific Skills and Knowledge: Some skills that may be useful in this field include: Statistics, both theoretical and applied Analysis and model construction using massive datasets and databases Computing statistics Statistics-based learning C. In contrast to unsupervised learning, supervised learning makes use of labeled datasets.
AI-driven tools can analyze large datasets in real time to detect subtle or unexpected deviations in schemachanges in field names, column counts, data types, or structural hierarchieswithout requiring extensive manual oversight. How ItWorks Generative AI models (GPT, LLMs) generate realistic test datasets based on past transformation logic.
However, with improvements in computing power, access to large amounts of data and more complex algorithms, ML has grown into a powerful tool capable of handling sophisticated tasks like natural language processing and image recognition. For example, the model might successfully identify 95% of spam emails in this dataset.
Furthermore, solving difficult problems in data science not only prepares you for the future but also teaches you the latest tools, techniques, algorithms and packages that have been introduced in the industry. Two Sigma Investments is a firm implementing data science tools over datasets for predicting financial trade since 2001.
Various machine learning models — whether these are simpler algorithms like decision trees or state-of-the-art neural networks — need a certain metric or multiple metrics to evaluate their performance. Then you choose an algorithm and do the model training on historic data and make your first predictions. Important to understand.
Entails employing algorithms like classification, clustering, and the like for extracting relationships and patterns from data. Data Types Big Data Data Mining Big data refers to robust and complicated datasets that require a high level of expertise and tools for managing, processing, or analyzing. to glean useful insights from data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content