This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. Today, we’re excited to open source this tool so that other Avro and Tensorflow users can use this dataset in their machine learning pipelines to get a large performance boost to their training workloads.
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Machine learning uses algorithms that comb through data sets and continuously improve the machine learning model.
And this technology of Natural Language Processing is available to all businesses. Available methods for text processing and which one to choose. What is Natural Language Processing? Natural language processing or NLP is a branch of Artificial Intelligence that gives machines the ability to understand natural human speech.
Types of Machine Learning: Machine Learning can broadly be classified into three types: Supervised Learning: If the available dataset has predefined features and labels, on which the machine learning models are trained, then the type of learning is known as Supervised Machine Learning. A sample of the dataset is shown below.
The historical dataset is over 20M records at the time of writing! Code and raw data repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns.
” In this article, we are going to discuss time complexity of algorithms and how they are significant to us. Nobody would want to use a system which takes a lot of time to process large input size. The Time complexity of an algorithm is the actual time needed to execute the particular codes.
There is no end to what can be achieved with the right ML algorithm. Machine Learning is comprised of different types of algorithms, each of which performs a unique task. U sers deploy these algorithms based on the problem statement and complexity of the problem they deal with.
Milvus and OpenSearch), machine learning libraries, data processing libraries, and AI workflows. Previously, in 2016, Meta had incorporated high performing vector search algorithms made for NVIDIA GPUs: GpuIndexFlat ; GpuIndexIVFFlat ; GpuIndexIVFPQ. officially includes these algorithms from the NVIDIA cuVS library. Faiss 1.10.0
Whether you are working on a personal project, learning the concepts, or working with datasets for your company, the primary focus is a data acquisition and data understanding. In this article, we will look at 31 different places to find free datasets for data science projects. What is a Data Science Dataset?
Balancing complexity and performance: An in-depth look at K-fold target encoding Photo by Mika Baumeister on Unsplash Introduction Data science practitioners encounter numerous challenges when handling diverse data types across various projects, each demanding unique processing methods.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
Stream processing engines like KSQL furthermore give you the ability to manipulate all of this fluently. We will cover how you can use them to enrich and visualize your data, add value to it with powerful graph algorithms, and then send the result right back to Kafka. Step 2: Using graph algorithms to recommend potential friends.
These systems store massive amounts of historical datadata that has been accumulated, processed, and secured over decades of operation. This bias can be introduced at various stages of the AI development process, from data collection to algorithm design, and it can have far-reaching consequences.
However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly. The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs).
The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold. The Medallion architecture is a framework that allows data engineers to build organized and analysis-ready datasets in a lakehouse environment.
Generative AI (GenAI), an area of artificial intelligence, is enhancing the automation of quality control processes, thereby increasing the safety and efficiency of the industry. Regulatory Updates: AI algorithms perform and analyze the news and changes related to regulations free of charge, making compliance simple for businesses.
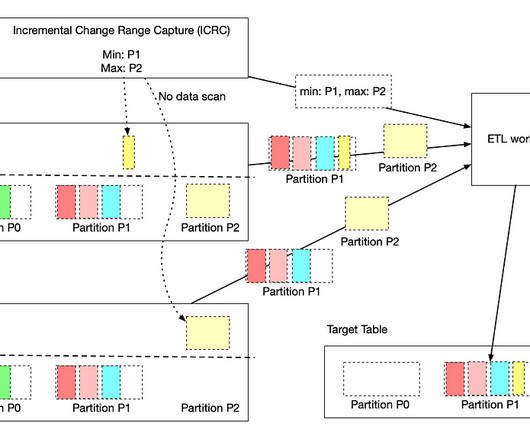
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Data transformation is the process of converting raw data into a usable format to generate insights. Data cleaning is the process of identifying and correcting errors and inconsistencies in the data. Filling in missing values could involve leveraging other company data sources or even third-party datasets.
As data volumes surge and the need for fast, data-driven decisions intensifies, traditional data processing methods no longer suffice. This growing demand for real-time analytics, scalable infrastructures, and optimized algorithms is driven by the need to handle large volumes of high-velocity data without compromising performance or accuracy.
The impact is proved by the comparison of the ML algorithm on starting and cleaning the dataset. The article shows effective coding procedures for fixing noisy labels in text data that improve the performance of any NLP model.
With its capabilities of efficiently training deep learning models (with GPU-ready features), it has become a machine learning engineer and data scientist’s best friend when it comes to train complex neural network algorithms. In this blog post, we are finally going to bring out the big guns and train our first computer vision algorithm.
At the core of such applications lies the science of machine learning, image processing, computer vision, and deep learning. As an example, consider the Facial Image Recognition System, it leverages the OpenCV Python library for implementing image processing techniques. What is OpenCV Python?
Today, we will delve into the intricacies the problem of missing data , discover the different types of missing data we may find in the wild, and explore how we can identify and mark missing values in real-world datasets. Image by Author. Let’s consider an example. Image by Author. Image by Author.
By learning from historical data, machine learning algorithms autonomously detect deviations, enabling timely risk mitigation. Machine learning offers scalability and efficiency, processing large datasets quickly. By taking into account the statistical characteristics of the entire dataset, global outliers are frequently found.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. This article will focus on explaining the contributions of generative AI in the future of telecommunications services.
Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data. These models are trained on vast datasets which allow them to identify intricate patterns and relationships that human eyes might overlook.
The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months. This meant business teams were operating with less-than-ideal data, and once an incident was detected, the team had to spend painstaking hours reassembling and backfilling datasets.
The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months. This meant business teams were operating with less-than-ideal data, and once an incident was detected, the team had to spend painstaking hours reassembling and backfilling datasets.
VantageCloud Lake provides robust capabilities for data storage, parallel processing, and analytics, making it an ideal choice for building scalable and performant data solutions. This isolation eliminates the need for complex workload management rules, as workloads are processed independently within their respective clusters.
Artificial intelligence encompasses a broad spectrum of categories, including machine learning, natural language processing, computer vision, and automated insights. The key question is how to identify relevant columns without accessing the actual dataset. Data filtering algorithms Lets look at the algorithm at work.
Movie recommender systems are intelligent algorithms that suggest movies for users to watch based on their previous viewing behavior & preferences. The heart of this system lies in the algorithm used in movie recommendation system. The heart of this system lies in the algorithm used in movie recommendation system.
Let’s explore predictive analytics, the ground-breaking technology that enables companies to anticipate patterns, optimize processes, and reach well-informed conclusions. Revenue Growth: Marketing teams use predictive algorithms to find high-value leads, optimize campaigns, and boost ROI. Want to know more?
Our brains are constantly processing sounds to give us important information about our environment. Audio analysis is a process of transforming, exploring, and interpreting audio signals recorded by digital devices. Source: Audio Singal Processing for Machine Learning. What is audio analysis? Speech recognition.
Pattern recognition is used in a wide variety of applications, including Image processing, Speech recognition, Biometrics, Medical diagnosis, and Fraud detection. And is used in a wide variety of applications, including image processing, speech recognition, and medical diagnosis.
TPOT is a library for performing sophisticated search over whole ML pipelines, selecting preprocessing steps and algorithm hyperparameters to optimize for your use case. In the hands of an experienced practitioner, AutoML holds much promise for automating away some of the tedious parts of building machine learning systems.
Machine learning is a field that encompasses probability, statistics, computer science and algorithms that are used to create intelligent applications. Since machine learning is all about the study and use of algorithms, it is important that you have a base in mathematics. It works on a large dataset.
These challenges can make investigating anomalies a complex and time consuming process. AI offers an opportunity to streamline the process, reducing the time needed and helping responders make better decisions. The output across the LLM requests are aggregated and the process is repeated until we have only five candidates left.
To make sure they were measuring real world impacts, Koller and Bosley selected two publicly available datasets characterized by large volumes and imbalanced classifications, reflective of real-world scenarios where classification algorithms often need to detect rare events such as fraud, purchasing intent, or toxic behavior.
To make sure they were measuring real world impacts, Koller and Bosley selected two publicly available datasets characterized by large volumes and imbalanced classifications, reflective of real-world scenarios where classification algorithms often need to detect rare events such as fraud, purchasing intent, or toxic behavior.
Vision Language Models (VLMs) represent a substantial development in machine learning by merging computer vision with natural language processing (NLP) capabilities. Open-source models are often pre-trained on big datasets, allowing developers to fine-tune them for specific tasks or industries.
User Intent Prediction The intent prediction component processes the input feature sequence through a Transformer encoder and generates predictions for multiple intentsignals. Note that FM-Intent uses a much smaller dataset for training compared to the FM production model due to its complex hierarchical prediction architecture.
If you are thinking of a simple, easy-to-implement supervised machine learning algorithm that can be used to solve both classifications as well as regression problems, K-Nearest Neighbors (K-NN) is a perfect choice. K-Nearest Neighbors is one of the most basic supervised machine learning algorithms, yet very essential.
Understanding data structures and algorithms (DSA) in C++ is key for writing efficient and optimised code. Some basic DSA in C++ that every programmer should know include arrays, linked lists, stacks, queues, trees, graphs, sorting algorithms like quicksort and merge sort, and search algorithms like binary search.
To store and process even only a fraction of this amount of data, we need Big Data frameworks as traditional Databases would not be able to store so much data nor traditional processing systems would be able to process this data quickly. Spark is 10-100 times faster because of in-memory processing and its caching mechanism.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content