This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructureddata processing—a field that powers modern artificial intelligence (AI) systems. Adding to this complexity is the sheer volume of data generated daily.
Here we mostly focus on structured vs unstructureddata. In terms of representation, data can be broadly classified into two types: structured and unstructured. Structured data can be defined as data that can be stored in relational databases, and unstructureddata as everything else.
Datasets are the repository of information that is required to solve a particular type of problem. Also called data storage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. The considerable amount of unstructureddata required Random Trees to create AI models that ensure privacy and data handling.
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. link] QuantumBlack: Solving data quality for gen AI applications Unstructureddata processing is a top priority for enterprises that want to harness the power of GenAI.
When asked what trends are driving data and AI , I explained two broad themes: The first is seeing more models and algorithms getting productionized and rolled out in interactive ways to the end user. Figure 1: Visual Question Answering Challenge data types and results.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
paintings, songs, code) Historical data relevant to the prediction task (e.g., paintings, songs, code) Historical data relevant to the prediction task (e.g., Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data.
Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data. Comprehending and understanding how to leverage unstructureddata has remained challenging and costly, requiring technical depth and domain expertise.
Aiming at understanding sound data, it applies a range of technologies, including state-of-the-art deep learning algorithms. Another application of musical audio analysis is genre classification: Say, Spotify runs its proprietary algorithm to group tracks into categories (their database holds more than 5,000 genres ).
A large hospital group partnered with Intel, the world’s leading chipmaker, and Cloudera, a Big Data platform built on Apache Hadoop , to create AI mechanisms predicting a discharge date at the time of admission. The built-in algorithm learns from every case, enhancing its results over time. Inpatient data anonymization.
Regardless of industry, data is considered a valuable resource that helps companies outperform their rivals, and healthcare is not an exception. In this post, we’ll briefly discuss challenges you face when working with medical data and make an overview of publucly available healthcare datasets, along with practical tasks they help solve.
AI Health Engine Language: Python Data set: CSV file Source code: Patient-Selection-for-Diabetes-Drug-Testing Artificial intelligence (AI) in healthcare is called the "AI Health Engine." The privacy and security of patient data and ensuring that AI algorithms are accurate, dependable, and impartial must be overcome.
A dataset is frequently represented as a matrix. Statistics Statistics are at the heart of complex machine learning algorithms in data science, identifying and converting data patterns into actionable evidence. Machine Learning Machine learning, a branch of data science, is used to model and derive conclusions from it.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. In this article, we will look at some of the top Data Science job roles that are in demand in 2024.
Big data vs machine learning is indispensable, and it is crucial to effectively discern their dissimilarities to harness their potential. Big Data vs Machine Learning Big data and machine learning serve distinct purposes in the realm of data analysis.
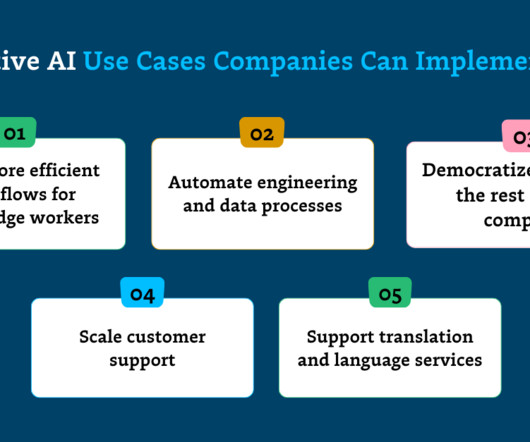
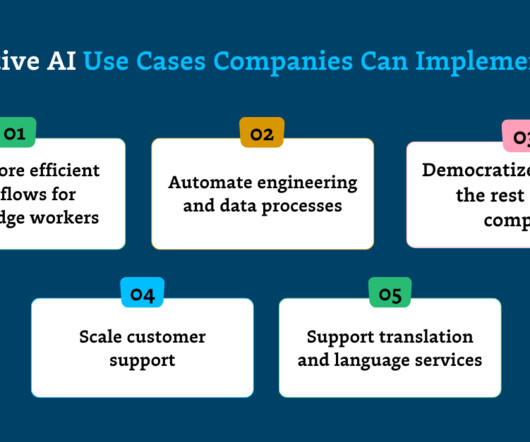
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful Big Data tool, Apache Hadoop alone is far from being almighty.
This will form a strong foundation for your Data Science career and help you gain the essential skills for processing and analyzing data, and make you capable of stepping into the Data Science industry. Let us look at some of the areas in Mathematics that are the prerequisites to becoming a Data Scientist.
If we look at history, the data that was generated earlier was primarily structured and small in its outlook. A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured.
Improve dataset quality. Ensure you can trust your data by using only diverse, high-quality training data that represents different demographics and viewpoints. Make sure to audit data regularly. Have plans to address issues like harmful content generation, data abuse, and algorithmic bias.
Parameters Machine Learning (ML) Deep Learning (DL) Feature Engineering ML algorithms rely on explicit feature extraction and engineering, where human experts define relevant features for the model. DL models automatically learn features from raw data, eliminating the need for explicit feature engineering. What is Machine Learning?
Since there are numerous ways to approach this task, it encourages originality in one's approach to data analysis. Moreover, this project concept should highlight the fact that there are many interesting datasets already available on services like GCP and AWS. Source: Use Stack Overflow Data for Analytic Purposes 4.
This field uses several scientific procedures to understand structured, semi-structured, and unstructureddata. It entails using various technologies, including data mining, data transformation, and data cleansing, to examine and analyze that data.
View A broader view of data Narrower view of dataDataData is gleaned from diverse sources. Data is gleaned from structured and specific sources Volume Massive volumes of data Smaller volumes of data Analysis Entails techniques like data aggregation, fusion, etc.,
Suppose you’re among those fascinated by the endless possibilities of deep learning technology and curious about the popular deep learning algorithms behind the scenes of popular deep learning applications. Table of Contents Why Deep Learning Algorithms over Traditional Machine Learning Algorithms? What is Deep Learning?
We *know* what we’re putting in (raw, often unstructureddata) and we *know* what we’re getting out, but we don’t know how it got there. Fine tuning is the process of training an existing LLM on a smaller, task-specific and labeled dataset, adjusting model parameters and embeddings based on this new data.
For example, when processing a large dataset, you can add more EC2 worker nodes to speed up the task. Amazon S3 : Highly scalable, durable object storage designed for storing backups, data lakes, logs, and static content. Data is accessed over the network and is persistent, making it ideal for unstructureddata storage.
Comparison Between Full Stack Developer vs Data Scientist Let’s compare Full stack vs data science to understand which is better, data science or full stack developer. Specifications Full stack developer Data scientist Term It is the creation of websites for the intranet, which is a public platform.
In the present-day world, almost all industries are generating humongous amounts of data, which are highly crucial for the future decisions that an organization has to make. This massive amount of data is referred to as “big data,” which comprises large amounts of data, including structured and unstructureddata that has to be processed.
A Data Engineer's primary responsibility is the construction and upkeep of a data warehouse. In this role, they would help the Analytics team become ready to leverage both structured and unstructureddata in their model creation processes. They construct pipelines to collect and transform data from many sources.
Matlab: Matlab is a closed-source, high-performing, numerical, computational, simulation-making, multi-paradigm data science tool for processing mathematical and data-driven tasks. Through this tool, researchers and data scientists can perform matrix operations, analyze algorithmic performance, and render data statistical modeling.
In data science, algorithms are usually designed to detect and follow trends found in the given data. The modeling follows from the data distribution learned by the statistical or neural model. In real life, the features of data points in any given domain occur within some limits.
A well-designed data pipeline ensures that data is not only transferred from source to destination but also properly cleaned, enriched, and transformed to meet the specific needs of AI algorithms. Why are data pipelines important? Where does Striim Come into Play When Building Data Pipelines?
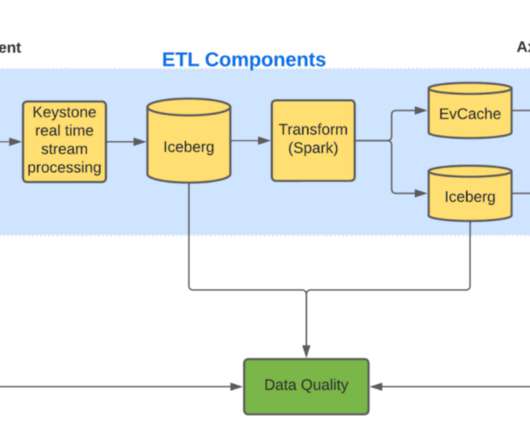
To achieve this, we rely on Machine Learning (ML) algorithms. ML algorithms can be only as good as the data that we provide to it. This post will focus on the large volume of high-quality data stored in Axion?—?our The Iceberg table created by Keystone contains large blobs of unstructureddata.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
This article looks into AI’s different uses in financial fraud detection, with a focus on techniques involving anomaly detection, machine learning algorithms, and real-time data analysis that help safeguard the credibility of financial systems. It includes identifying unusual behaviors or patterns within datasets.
Machine Learning Projects are the key to understanding the real-world implementation of machine learning algorithms in the industry. Datasets like Google Local, Amazon product reviews, MovieLens, Goodreads, NES, Librarything are preferable for creating recommendation engines using machine learning models. Let the FOMO kick in!
This blog post will delve into the challenges, approaches, and algorithms involved in hotel price prediction. Hotel price prediction is the process of using machine learning algorithms to forecast the rates of hotel rooms based on various factors such as date, location, room type, demand, and historical prices. Data relevance.
On the surface, ML algorithms take the data, develop their own understanding of it, and generate valuable business insights and predictions — all without human intervention. It boosts the performance of ML specialists relieving them of repetitive tasks and enables even non-experts to experiment with smart algorithms.
The machine learning career path is perfect for you if you are curious about data, automation, and algorithms, as your days will be crammed with analyzing, implementing, and automating large amounts of knowledge. This includes knowledge of data structures (such as stack, queue, tree, etc.),
We’ll particularly explore data collection approaches and tools for analytics and machine learning projects. What is data collection? It’s the first and essential stage of data-related activities and projects, including business intelligence , machine learning , and big data analytics.
The goal of kappa architecture is to reduce the cost of data integration by providing an efficient and real-time way of managing large datasets. Additionally, it allows for efficient processing of both real-time and historical data which eliminates the need for multiple versions of the same dataset or manually managed systems.
Top 20 Python Projects for Data Science Without much ado, it’s time for you to get your hands dirty with Python Projects for Data Science and explore various ways of approaching a business problem for data-driven insights. 1) Music Recommendation System on KKBox Dataset Music in today’s time is all around us.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content