This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With Astro, you can build, run, and observe your data pipelines in one place, ensuring your mission critical data is delivered on time. meeting recordings and videos), which contrasts with traditional SQL-centric systems for structured data. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g.,
We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Data pipeline to OneLake and Microsoft Fabric. The need to copy data across layers, manage different schemas, and address data latency issues can complicate data pipelines. However, this architecture is not without its challenges.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. This week I discovered SQLMesh , a all-in-one data pipelines tool. Rare footage of a foundation model ( credits ) Fast News ⚡️ Twitter's recommendation algorithm — It was an Elon tweet. I hope he will fill the gaps.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. This week I discovered SQLMesh , a all-in-one data pipelines tool. Rare footage of a foundation model ( credits ) Fast News ⚡️ Twitter's recommendation algorithm — It was an Elon tweet. I hope he will fill the gaps.
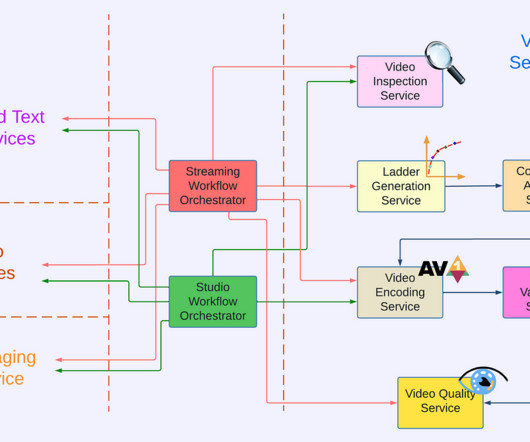
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
These teams work together to ensure algorithmic fairness, inclusive design, and representation are an integral part of our platform and product experience. Likewise in closeup recommendations, we added an additional diversification objective to the existing DPP Node as the final step in our blending pipeline prior to returning ranked results.
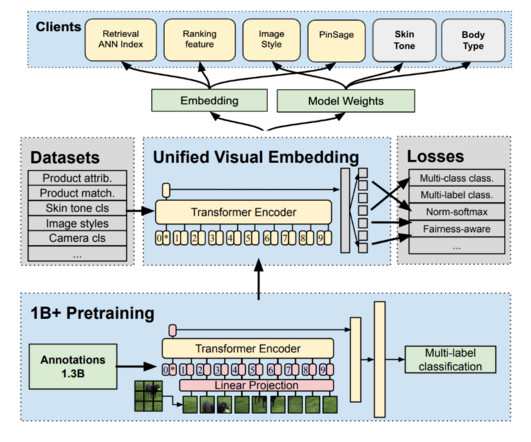
Deep Learning, a subset of AI algorithms, typically requires large amounts of human annotated data to be useful. Related to the neglect of data quality, it has been observed that much of the efforts in AI have been model-centric, that is, mostly devoted to developing and improving models , given fixed data sets. Data annotation.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, data pipelines, and the ETL (Extract, Transform, Load) process. Data Modeling using multiple algorithms. The data pipelines allow businesses to collect data from millions of users and process the results in real-time.
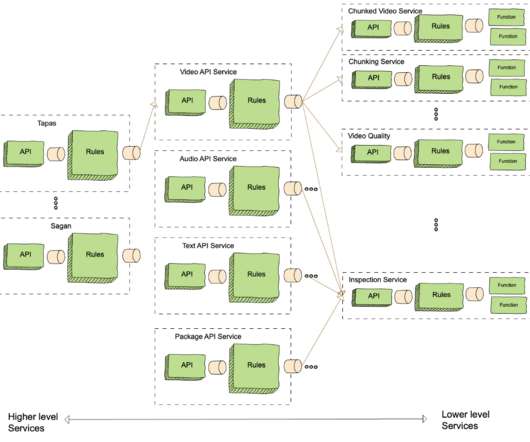
Its sweet spot is applications that involve resource-intensive algorithms coordinated via complex, hierarchical workflows that last anywhere from minutes to years. When Reloaded was designed, we were a small team of developers operating a constrained compute cluster, and focused on one use case: the video/audio processing pipeline.
Data is simply too centric to the company’s activity to have limitation around what roles can manage its flow. The modern data warehouse is a more public institution than it was historically, welcoming data scientists, analysts, and software engineers to partake in its construction and operation.
This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use. Roughly, the operations in a data pipeline consist of the following phases: Ingestion — this involves gathering in the needed data. A data scientist is only as good as the data they have access to.
Specifically, Lyft’s in-house distributed hyperparameter optimization pipeline is used for the majority of its business critical models. That said, in 2020, Lyft moved towards a more user centric approach — preselecting a user’s most frequently used mode. Screenshots are illustrative. May not capture the current experience.
The idea was to create a one-stop shop for users to collect data from different sources and then clean and organize it for use by machine learning algorithms. I frequently check Pipeline Runs and Sensor Ticks, but, often verify with Dagit.”
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data pipelines Data integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Data Engineers must be proficient in Python to create complicated, scalable algorithms. Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather. They are frequently found in midsize businesses. Responsibilities of a Data Engineer.
We have heard news of machine learning systems outperforming seasoned physicians on diagnosis accuracy, chatbots that present recommendations depending on your symptoms , or algorithms that can identify body parts from transversal image slices , just to name a few. What makes a good Data Pipeline?
In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. Pipeline-Centric Engineer: These data engineers prefer to serve in distributed systems and more challenging projects of data science with a midsize data analytics team.
Hadoop uses Apache Mahout to run machine learning algorithms for clustering, classification, and other tasks on top of MapReduce. GraphX offers a set of operators and algorithms to run analytics on graph data. It also provides tools for statistics, creating ML pipelines, model evaluation, and more. Processing options.
It can involve prompt engineering, vector databases like Pinecone , embedding vectors and semantic layers, data modeling, data orchestration, and data pipelines – all tailored for RAG. This step involves complex algorithms to match the query with the most appropriate and contextually relevant information from the database.
For instance, AI algorithms can predict flight delays, optimize crew assignments, or personalize customer services based on current data. By deploying machine learning algorithms, airlines can sift through vast data volumes, identifying patterns and foreseeing potential issues like mechanical failures or delays.
Moorthy and Zhi Li Introduction Measuring video quality at scale is an essential component of the Netflix streaming pipeline. This tight coupling means that it is not possible to achieve the following without re-encoding: A) rollout of new video quality algorithms B) maintaining the data quality of our catalog (e.g. by Christos G.
Data engineering builds data pipelines for core professionals like data scientists, consumers, and data-centric applications. Data engineering is also about creating algorithms to access raw data, considering the company's or client's goals. A data engineer can be a generalist, pipeline-centric, or database-centric.
RecoverX is described as app-centric and can back up applications data whilst being capable of recovering it at various granularity levels to enhance storage efficiency. Cloudera is more inclined on becoming a product centric business with 23% of its revenue coming from services past year in comparison to 31% for Hortonworks.
Automating data analytics techniques and processes has led to the development of mechanical methods and algorithms used over raw data. The ML algorithms we use to process the data are also quite large; it's not just big data. These are some of the trends in data science examples: 1.
Twitter: Twitter's Recommendation Algorithm Twitter open-source its recommendation engine code. link] Tweet Search System (EarlyBird) Design [link] Google AI: Data-centric ML benchmarking - Announcing DataPerf’s 2023 challenges Data is the new code: it is the training data that determines the maximum possible quality of an ML solution.
The job of a Machine Learning Engineer is to maintain the software architecture, run data pipelines to ensure seamless flow in the production environment. An essential skill for both the job roles is familiarity with various machine learning and deep learning algorithms.
Becoming an Azure Data Engineer in this data-centric landscape is a promising career choice. The main duties of an Azure Data Engineer are planning, developing, deploying, and managing the data pipelines. Master data integration techniques, ETL processes, and data pipeline orchestration using tools like Azure Data Factory.
It provides a wide range of fully managed mobile-centric services, such as authentication, push messaging, analytics, file storage, and NoSQL databases. Software algorithms. Firebase Overview: A mobile platform called Firebase offers a full toolkit for developing, enhancing, and expanding apps, which helps save developers' time.
As data pipelines become increasingly complex, investing in a data quality solution is becoming an increasingly important priority for modern data teams. And as data pipelines become increasingly complex, reactive approaches to solving data quality issues are not enough. But should you build it—or buy it? They chose to buy instead.
It offers practical experience with streaming data, efficient data pipelines, and real-time analytics solutions. Appreciated Customer Experience: The industry focuses on customer-centric approaches to enhance the overall customer experience. It provides real-time data pipelines and integration with various data sources.
Through an intuitive drag-and-drop interface, users can create sophisticated data pipelines, perform complex transformations, and even implement AI models without writing a single line of code. It supports both traditional ML algorithms and deep learning frameworks, catering to a wide range of AI applications.
With its native support for in-memory distributed processing and fault tolerance, Spark empowers users to build complex, multi-stage data pipelines with relative ease and efficiency. The MLlib library in Spark provides various machine learning algorithms, making Spark a powerful tool for predictive analytics. Machine learning.
Combining efficient incident handling, establishing resilience by design, and strict adherence to SLOs are pivotal in ensuring our services remain resilient, reliable, stable, and user-centric. Now we use simulation-driven automated testing as a stage of our CI/CD pipeline, totaling over 900 pull requests since the release!
In his role at LendingTree, he works closely with the data engineering team, synthesizes findings from data to provide actionable recommendations, and works with tree-based algorithms. Ahmed also has experience working on self-driving cars, human-robot interaction, and AI algorithms for missile defense.
In my previous role as a junior DevOps engineer, I implemented a continuous integration and continuous delivery (CI/CD) pipeline that reduced deployment time by 50%, resulting in increased scalability and cost efficiency. I'm passionate about streamlining the software development lifecycle through automation and collaboration.
From time spent at Delta Airlines, Initiate Systems, and IBM, Priya has developed algorithms required to run a $200M+ Master Data Management business, led complete business transformations, and managed product functions across banking, insurance, retail, government, and healthcare.
Looking for a position to test my skills in implementing data-centric solutions for complicated business challenges. Example 6: A well-qualified Cloud Engineer is looking for a position responsible for developing and maintaining automated CI/CD and deploying pipelines to support platform automation.
The curriculum covers crucial topics including Object-Oriented Programming, Data Structures and Algorithms, GIT profiles, and introduces you to MongoDB, Express.js, React, and Node.js. You can gain practical experience in creating APIs and front-end applications with React, as well as setting up CI/CD pipelines. Duration 4+ Hours.
The curriculum covers crucial topics including Object-Oriented Programming, Data Structures and Algorithms, GIT profiles, and introduces you to MongoDB, Express.js, React, and Node.js. You can gain practical experience in creating APIs and front-end applications with React, as well as setting up CI/CD pipelines. Duration 4+ Hours.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content