This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on July 28, 2025 in Machine Learning Image by Author | Ideogram # Introduction From your email spam filter to music recommendations, machine learning algorithms power everything. This process repeats until the centroids stop moving.
By Jayita Gulati on July 16, 2025 in Machine Learning Image by Editor In data science and machine learning, raw data is rarely suitable for direct consumption by algorithms. Transforming this data into meaningful, structured inputs that models can learn from is an essential step — this process is known as feature engineering.
If you are dealing with deep neural networks, you will surely stumble across a very known and widely used algorithm called Back Propagation Algorithm. This blog will give you a complete overview of the Back propagation algorithm from scratch. Table of Contents What is the Back Propagation Algorithm in Neural Networks ?
Whether tracking user behavior on a website, processing financial transactions, or monitoring smart devices, the need to make sense of this data is growing. But when it comes to handling this data, businesses must decide between two key processes - batch processing vs stream processing. What is Batch Processing?
Feature Development Bottlenecks Adding new features or testing algorithmic variations required days-long backfill jobs. The process lacked fine-tuning capabilities within the training loop. User code and data transformation are abstracted so they can be easily moved to any other data processing systems.
However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly. The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs).
PySpark is a handy tool for data scientists since it makes the process of converting prototype models into production-ready model workflows much more effortless. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Why use PySpark? JSC- Represents the JavaSparkContext instance.
This blog serves as a comprehensive guide on the AdaBoost algorithm, a powerful technique in machine learning. This wasn't just another algorithm; it was a game-changer. Before the AdaBoost machine learning model , most algorithms tried their best but often fell short in accuracy. Freund and Schapire had a different idea.
Data transformation is the process of converting raw data into a usable format to generate insights. Data cleaning is the process of identifying and correcting errors and inconsistencies in the data. Data Validation Data validation ensures that the data meets specific criteria before processing. What is Data Transformation?
Training large-scale models involves thousands of accelerators in a synchronous environment, where any component failure can interrupt or halt the process. Advances in RAS telemetry in hyperscale infrastructure have greatly improved this process. When triggered, devices are marked for mitigation or repair.
Reinvent Your Content Management Process One of the main causes of poor governance is unstructured data — information that doesn’t follow a predefined format, including documents, videos, and images. Focus first on high-volume, data-intensive processes where manual oversight is most challenging.
Understanding Generative AI Generative AI describes an integrated group of algorithms that are capable of generating content such as: text, images or even programming code, by providing such orders directly. This article will focus on explaining the contributions of generative AI in the future of telecommunications services.
Clustering algorithms are a fundamental technique in machine learning used to identify patterns and group data points based on similarity. This blog will explore various clustering algorithms and their applications, including K-Means, Hierarchical clustering, DBSCAN, and more. What are Clustering Algorithms in Machine Learning?
Apache Kafka and RabbitMQ are messaging systems used in distributed computing to handle big data streams– read, write, processing, etc. Since protocol methods (messages) sent are not guaranteed to reach the peer or be successfully processed by it, both publishers and consumers need a mechanism for delivery and processing confirmation.
Data engineering tools are specialized applications that make building data pipelines and designing algorithms easier and more efficient. Another reason to use data engineering tools is that they support the process of transforming data. It's one of the fastest platforms for data management and stream processing.
A machine learning pipeline helps automate machine learning workflows by processing and integrating data sets into a model, which can then be evaluated and delivered. Increased Adaptability and Scope Although you require different models for different purposes, you can use the same functions/processes to build those models.
From data exploration and processing to later stages like model training, model debugging, and, ultimately, model deployment, SageMaker utilizes all underlying resources like endpoints, notebook instances, the S3 bucket, and various built-in organization templates needed to complete your ML project. How much does SageMaker charge?
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. And who better to learn from than the tech giants who process more data before breakfast than most companies see in a year?
But you do need to understand the mathematical concepts behind the algorithms and analyses youll use daily. Part 2: Linear Algebra Every machine learning algorithm youll use relies on linear algebra. Understanding it transforms these algorithms from mysterious black boxes into tools you can use with confidence.
These systems store massive amounts of historical datadata that has been accumulated, processed, and secured over decades of operation. This bias can be introduced at various stages of the AI development process, from data collection to algorithm design, and it can have far-reaching consequences.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
So teams get stalled in either a long cost optimization process, or are forced to make trade-offs between cost and quality. Cost and quality: Even after teams solve the above issues and build a high-quality agent, they are often surprised to find that the agent is too expensive to scale into production. ignore all data before May 1990).
It has inspired original equipment manufacturers (OEMs) to innovate their systems, designs and development processes, using data to achieve unprecedented levels of automation. Enabling OEMs to scale data storage and processing capabilities, cloud computing also facilitates collaboration across teams globally.
How we are analyzing the metric segments takes inspiration from the algorithm in Linkedins ThirdEye. a new recommendation algorithm). For analytics tools like anomaly detection or root-cause analysis, the results are often mere suggestions for users who may not have a clear idea of the algorithms involved or how to tune them.
Businesses of all sizes use AWS Machine Learning for application development associated with various problems, such as fraud detection , image and automatic speech recognition , and natural language processing (NLP). SageMaker also provides a collection of built-in algorithms, simplifying the model development process.
How it helps : When youre tweaking hyperparameters and testing different algorithms, keeping track of what worked becomes impossible without proper tooling. What makes it useful : Pre-built monitoring metrics, interactive dashboards, and drift detection algorithms. MLflow acts like a lab notebook for your ML experiments.
It means biased hiring algorithms, flawed medical diagnoses, and financial models that miss critical risks. Machine learning algorithms find patterns in whatever data you provide. The problem isn’t the algorithm. Customer segmentation algorithms miss emerging demographics. The stakes have never been higher.
With AWS DevOps, data scientists and engineers can access a vast range of resources to help them build and deploy complex data processing pipelines, machine learning models, and more. You need to be able to process, analyze, and deliver insights in real-time to keep up with the competition. This is where AWS DevOps comes in.
The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold. By methodically processing data through Bronze, Silver, and Gold layers, this approach supports a variety of use cases. Bronze layers should be immutable.
Exponential Growth in AI-Driven Data Solutions This approach, known as data building, involves integrating AI-based processes into the services. As early as 2025, the integration of these processes will become increasingly significant. It lets you describe data more complexly and make predictions.
Brilliant algorithms, cutting-edge models, massive computing power, all undermined by one overlooked factor. Real-time AI applications need instantaneous data access, yet most pipelines were built for overnight batch processing. A pricing algorithm working with outdated information could destroy your margins overnight.
Google Cloud Dataproc Dataproc is a fully-managed and scalable Spark and Hadoop Service that supports batch processing, querying, streaming, and machine learning. Key Features: With Dataproc, you can easily use the open-source tools, algorithms, and programming languages you are already familiar with on cloud-scale datasets.
Leap second smearing a solution past its time Leap second smearing is a process of adjusting the speeds of clocks to accommodate the correction that has been a common method for handling leap seconds. microseconds. This approach has a number of advantages, including being completely stateless and reproducible.
Generative AI (GenAI), an area of artificial intelligence, is enhancing the automation of quality control processes, thereby increasing the safety and efficiency of the industry. Regulatory Updates: AI algorithms perform and analyze the news and changes related to regulations free of charge, making compliance simple for businesses.
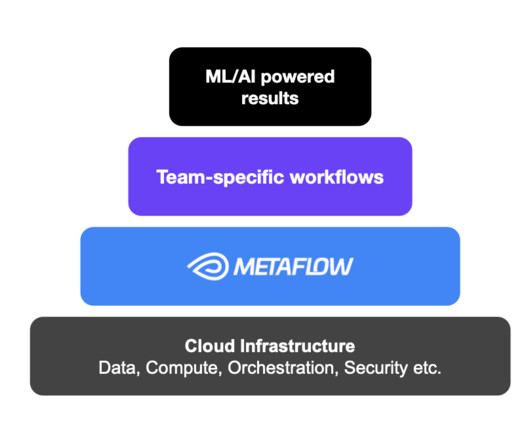
Frequently, practitioners want to experiment with variants of these flows, testing new data, new parameterizations, or new algorithms, while keeping the overall structure of the flow or flowsintact. You can see the actual command and args that were sub-processed in the Metaboost Execution section below.
The job of data engineers typically is to bring in raw data from different sources and process it for enterprise-grade applications. Work in teams to create algorithms for data storage, data collection, data accessibility, data quality checks, and, preferably, data analytics.
Luigi is a Python package or module that handles complex workflows, batch processes, and pipeline visualizations. Businesses use Luigi for functions such as long-running Hadoop processes, data exchange with databases, supporting machine learning algorithms, and many more. What is Luigi?
Nothing frustrates new contributors like a broken setup process. Her areas of interest and expertise include DevOps, data science, and natural language processing. Organize your Makefiles to group related functionality together. Make sure all your commands work from a fresh clone of your repository.
The challenge with AI readiness and why data products matter Success with AI relies on more than just ML model training, algorithms and compute power. Unfortunately, many organizations and business leaders struggle to make high-quality data easily accessible, meaning that even the most sophisticated AI strategies fall flat.
This architecture made Offer processing slow, expensive, and fragile. Frequent stock and price updates were processed alongside mostly static Product data, with over 90% of each payload unchangedwasting network, memory, and processing resources. In CHLB, each backend pod is assigned to multiple random positions on a hash ring.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
In the thought process of making a career transition from ETL developer to data engineer job roles? ETL is a process that involves data extraction, transformation, and loading from multiple sources to a data warehouse, data lake, or another centralized data repository. Python) to automate or modify some processes.
From the fundamentals to advanced concepts, it covers everything from a step-by-step process of creating PySpark UDFs, demonstrating their seamless integration with SQL , and practical examples to solidify your understanding. As data grows in size and complexity, so does the need for tailored data processing solutions.
We’ll use a real data project from Gett, a London black taxi app similar to Uber, used in their recruitment process, to show how it works in practice. In this article, we will explore five routine tasks that ChatGPT can handle if you use the right prompts, including cleaning and organizing the data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content