This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
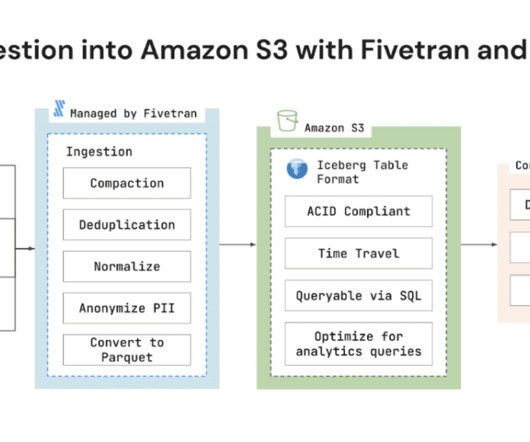
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format. Amazon S3 is an object storage service from AmazonWebServices (AWS) that offers industry-leading scalability, data availability, security, and performance.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. In addition to this, they make sure that the data is always readily accessible to consumers.
Datacleansing. Before getting thoroughly analyzed, data ? In a nutshell, the datacleansing process involves scrubbing for any errors, duplications, inconsistencies, redundancies, wrong formats, etc. and as such confirming the usefulness and relevance of data for analytics. whether small or big ?
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
To manage complicated analytics activities, organizations must take into account the scalability of their infrastructure, which includes hardware, cloud resources, and data processing capabilities. AWS (AmazonWebServices) offers a range of services and tools for managing and analyzing big data.
After residing in the raw zone, data undergoes various transformations. The datacleansing process involves removing or correcting inaccurate records, discrepancies, or inconsistencies in the data. Data enrichment adds value to the original data set by incorporating additional information or context.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and datacleansing and analysis.
Once the data is loaded into Snowflake, it can be further processed and transformed using SQL queries or other tools within the Snowflake environment. This includes tasks such as datacleansing, enrichment, and aggregation.
Introduction to AWS Instance Types AmazonWebServices (AWS) offers a diverse range of instance types, each tailored to specific computing needs and optimized for various workloads. Batch Processing- C-Series instances excel in scenarios that involve batch processing, where large amounts of data need to be processed in parallel.
This project is an opportunity for data enthusiasts to engage in the information produced and used by the New York City government. 18) GCP Project to Explore Cloud Functions The three popular cloud service providers in the market are AmazonWebServices, Microsoft Azure, and GCP.
Build Data Migration: Data from the existing data warehouse is extracted to align with the schema and structure of the new target platform. This often involves data conversion, datacleansing, and other data transformation activities to help ensure data integrity and quality during the migration.
This would include the automation of a standard machine learning workflow which would include the steps of Gathering the data Preparing the Data Training Evaluation Testing Deployment and Prediction This includes the automation of tasks such as Hyperparameter Optimization, Model Selection, and Feature Selection.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content