This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud. A collaborative and interactive workspace allows users to perform bigdata processing and machine learning tasks easily.
Lambda systems try to accommodate the needs of both bigdata-focused data scientists as well as streaming-focused developers by separating data ingestion into two layers. One layer processes batches of historic data.
Firms use business analytics to improve decision-making. It has several key components: Descriptive Analytics: It is a part of Business AnalyticsApplications. It tries to find information in past data. Its goal is to process data and make unique suggestions. It often involves trend analysis.
If you're looking to break into the exciting field of bigdata or advance your bigdata career, being well-prepared for bigdata interview questions is essential. Get ready to expand your knowledge and take your bigdata career to the next level! Everything is about data these days.
It takes in approximately $36 million dollars from across 4300 US stores everyday.This article details into Walmart BigDataAnalytical culture to understand how bigdataanalytics is leveraged to improve Customer Emotional Intelligence Quotient and Employee Intelligence Quotient.
These seemingly unrelated terms unite within the sphere of bigdata, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale dataanalytics. Bigdata processing.
Table of Contents LinkedIn Hadoop and BigDataAnalytics The BigData Ecosystem at LinkedIn LinkedIn BigData Products 1) People You May Know 2) Skill Endorsements 3) Jobs You May Be Interested In 4) News Feed Updates Wondering how LinkedIn keeps up with your job preferences, your connection suggestions and stories you prefer to read?
It is difficult to stay up-to-date with the latest developments in IT industry especially in a fast growing area like bigdata where new bigdata companies, products and services pop up daily. With the explosion of BigData, Bigdataanalytics companies are rising above the rest to dominate the market.
Welcome to the world of data engineering, where the power of bigdata unfolds. If you're aspiring to be a data engineer and seeking to showcase your skills or gain hands-on experience, you've landed in the right spot. If data scientists and analysts are pilots, data engineers are aircraft manufacturers.
Manufacturing, where the data they generate can provide new business opportunities like predictive maintenance in addition to improving their operational efficiency. Retail, where bigdata is used across all stages of the retail process—from product development, pricing, demand forecasting, and for inventory optimization in the stores.
Correlations across data domains, even if they are not traditionally stored together (e.g. real-time customer event data alongside CRM data; network sensor data alongside marketing campaign management data). The extreme scale of “bigdata”, but with the feel and semantics of “small data”.
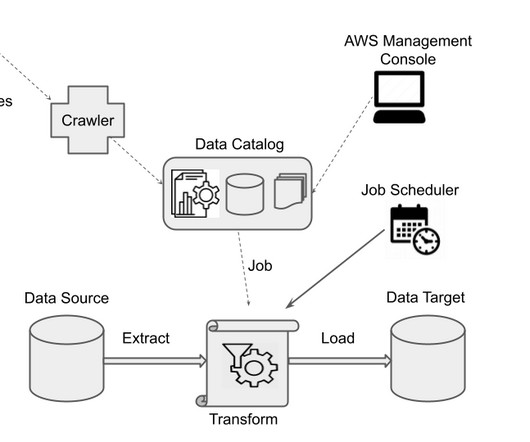
AWS Glue is a powerful data integration service that prepares your data for analytics, application development, and machine learning using an efficient extract, transform, and load (ETL) process. The AWS Glue service is rapidly gaining traction, with more than 6,248 businesses worldwide utilizing it as a bigdata tool.
Already familiar with the term bigdata, right? Despite the fact that we would all discuss BigData, it takes a very long time before you confront it in your career. Apache Spark is a BigData tool that aims to handle large datasets in a parallel and distributed manner. Begin with a small sample of the data.
It is just the technical hadoop job interview that separates you from your bigdata career. Cognizant’s BIGFrame solution uses Hadoop to simplify migration of data and analyticsapplications to provide mainframe like performance at an economical cost of ownership over data warehouses.
Whether you work in BI, Data Science or ML all that matters is the final application and how fast you can see it working end-to-end. Imagine, as a practical example, that we need to build a new customer-facing analyticsapplication for our product team. The infrastructure often gets in the way though.
Apache Kafka is an open-source, distributed streaming platform for messaging, storing, processing, and integrating large data volumes in real time. It offers high throughput, low latency, and scalability that meets the requirements of BigData. Cloudera , focusing on BigDataanalytics. Kafka vs ETL.
Instead, they have separate data stores and inconsistent (if any) frameworks for data governance, management, and security. This leads to extra cost, effort, and risk to stitch together a sub-optimal platform for multi-disciplinary, cloud-based analyticsapplications. Soon we’ll have Altus Data Science, too!
HCL employs a simple and intuitive assessment to identify the bigdata maturity of the customer and suggest appropriate course of action to leverage maximum potential of bigdata. As of 18 th August, 2016, Glassdoor listed 9 hadoop job openings in US alone.
One of the most important decisions for Bigdata learners or beginners is choosing the best programming language for bigdata manipulation and analysis. Java does not support Read-Evaluate-Print-Loop (REPL), which is a major deal-breaker when choosing a programming language for bigdata processing.
As the market moves toward cloud-based bigdata and analytics, three qualities emerge as vital for success. End-user focused tools accelerate daily tasks like job submission, performance tuning, and workload analytics. Make sure any cloud-based analytics service meets these criteria. We’re here to help.
Acquire first-hand experience in learning Python packages for data processing and analysis. BigData: Principles and best practices of scalable real-time data systems BigData: Principles and Best Practices of Scalable Realtime Data Systems is an excellent resource for anyone who wants to learn the fundamentals of working with bigdata.
With the right geocoding technology, accurate and standardized address data is entirely possible. This capability opens the door to a wide array of dataanalyticsapplications. The Rise of Cloud AnalyticsDataanalytics has advanced rapidly over the past decade.
And when systems such as Hadoop and Hive arrived, it married complex queries with bigdata for the first time. The tradeoff of these first-generation SQL-based bigdata systems was that they boosted data processing throughput at the expense of higher query latency.
It brings the reliability and simplicity of SQL tables to bigdata while enabling engines like Hive, Impala, Spark, Trino, Flink, and Presto to work with the same tables at the same time. It has been designed and developed as an open community standard to ensure compatibility across languages and implementations.
The rapid growth of data-driven organizations has led to various dataanalytic specializations. These specialized dataanalytics roles are discussed below: 1. BigData Analyst Bigdataanalytics studies large data sets to find useful business insights.
News on Hadoop-February 2017 Bigdata brings breast cancer research forwards by 'decades'. Researchers analysed data of more than 28000 different genes and millions of images of 300,000 breast cancer cells and found that any cell shape changes caused by physical pressures on the tumours are converted into gene activity.
Companies are adopting streaming data, they are dealing with greater volumes and amounts of data, and more of them are working with diverse third party vendors to receive data. In fact, you can describe bigdata from many different sources by these five characteristics: volume, value, variety, velocity and veracity.
Apache Hive : Initially developed at Facebook and released in 2010, Hive was designed to bring SQL capabilities to Apache Hadoop and allows SQL developers to perform queries on large data systems.
The trend towards powerful in-house cloud platforms for data and analysis ensures that large volumes of data can increasingly be stored and used flexibly. New bigdata architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications.
Hadoop is beginning to live up to its promise of being the backbone technology for BigData storage and analytics. Companies across the globe have started to migrate their data into Hadoop to join the stalwarts who already adopted Hadoop a while ago. All Data is not BigData and might not require a Hadoop solution.
In conclusion, kappa architectures have revolutionized the way businesses approach bigdata solutions – allowing them to take advantage of cutting edge technologies while reducing costs associated with manual processes like ETL systems. Finally, kappa architectures are not suitable for all types of data processing tasks.
Cloudera and Intel have a long history of innovation, driving bigdataanalytics and machine learning into the enterprise with unparalleled performance and security. Apache HBase® is one of many analyticsapplications that benefit from the capabilities of Intel Optane DC persistent memory.
According to the 8,786 data professionals participating in Stack Overflow's survey, SQL is the most commonly-used language in data science. Despite the buzz surrounding NoSQL , Hadoop , and other bigdata technologies, SQL remains the most dominant language for data operations among all tech companies.
Given its status as one of the complete all-in-one analytics and BI systems available currently, the platform requires some getting accustomed to. Some key features include business intelligence, enterprise planning, and analyticsapplication. You will also need an ETL tool to transport data between each tier.
Not Just Modern, But Real Time The modern data stack emerged a decade ago, a direct response to the shortcomings of bigdata. Companies that undertook bigdata projects ran head-long into the high cost, rigidity and complexity of managing complex on-premises data stacks.
Popular instances where GCP is used widely are machine learning analytics, application modernization, security, and business collaboration. On the other hand, GCP Dataflow is a fully managed data processing service for batch and streaming bigdata processing.
From cloud computing consultants to bigdata architects, companies across the world are looking to hire bigdata and cloud experts at an unparalleled rate. For example, it is possible to work on research projects on cloud computing or implement cloud computing for bigdata projects.
As data collection and usage have become more sophisticated, the sources of data have become a lot more varied and disparate, volumes have grown and velocity has increased. He then went on to work for Capgemini where he helped the UK government move into the world of BigData.
From Enormous Data back to BigData Say you are tasked with building an analyticsapplication that must process around 1 billion events (1,000,000,000) a day. How you transition from a batch mindset to a streaming mindset although can also be tricky, so let’s start small and build.
Amazon Web Service (AWS) offers the Amazon Kinesis service to process a vast amount of data, including, but not limited to, audio, video, website clickstreams, application logs, and IoT telemetry, every second in real-time. Compared to BigData tools, Amazon Kinesis is automated and fully managed.
Publish: Transformed data is then published either back to on-premises sources like SQL Server or kept in cloud storage. This makes the data ready for consumption by BI tools, analyticsapplications, or other systems. This dynamic duo takes data processing to new heights.
The next solution for self-service data analysis from Qlik is called Qlik Sense. It provides analytics features for different types of accounts, such as associated research and navigation, clever visualization, data preprocessing, and much more, making it one of the top BI tools.
It has expanded to various industries and applications, including IoT sensor data, financial data, web analytics, gaming behavioral data, and many more use cases. Strong schema support : Avro has a well-defined schema that allows for type safety and strong data validation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content