This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud. In this blog post, we will take a closer look at Azure Databricks, its key features, […] The post Azure Databricks: A Comprehensive Guide appeared first on Analytics Vidhya.
This will also accelerate deployment of new data products for AI, gen AI, and analyticsapplications. The post Octopai Acquisition Enhances Metadata Management to Trust Data Across Entire Data Estate appeared first on Cloudera Blog.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! For more details, read my blog post on ALT and why it beats the Lambda architecture for real-time analytics. Rockset provides a real-time analytics database in the cloud built around the ALT architecture.
We believe Eventador will accelerate innovation in our Cloudera DataFlow streaming platform and deliver more business value to our customers in their real-time analyticsapplications. The post Cloudera acquires Eventador to accelerate Stream Processing in Public & Hybrid Clouds appeared first on Cloudera Blog.
This blog post is intended to provide guidance to Ozone administrators and application developers on the optimal usage of the bucket layouts for different applications. Most traditional analyticsapplications like Hive, Spark, Impala, YARN etc.
The ability to manage how the data flows and transforms during the first mile of the data pipeline and control the data distribution can accelerate the performance of all analyticapplications. The post Why Modernizing the First Mile of the Data Pipeline Can Accelerate all Analytics appeared first on Cloudera Blog.
Materializing data into views (materialized views) has become an excellent mechanism to interface with an entire ecosystem of existing tooling – from dashboarding programs, notebooks for ML or AI, or analyticsapplications. The post Using SQL to democratize streaming data appeared first on Cloudera Blog.
Modern data platforms deliver an elastic, flexible, and cost-effective environment for analyticapplications by leveraging a hybrid, multi-cloud architecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. The post Demystifying Modern Data Platforms appeared first on Cloudera Blog.
The blog crossed the 2000 members mark (❤️) and I won the best data science newsletter award. Introducing ADBC: Database Access for Apache Arrow — When I see "minimal-overhead alternative to JDBC/ODBC for analyticalapplications" I'm instantly in. I think this is even relevant to data world.
It is designed to simplify deployment, configuration, and serviceability of Solr-based analyticsapplications. DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructured data (i.e.
This unified data environment eliminates the need for maintaining separate data silos and facilitates seamless access to data for AI and analyticsapplications. The post Unify your data: AI and Analytics in an Open Lakehouse appeared first on Cloudera Blog. Learn more about the Cloudera Open Data Lakehouse here.
You end up having data flowing in the right format for your cloud analytics solution. The main value from this is that you can now run operational workloads, high value or high operational value producing analyticsapplications in your analytics solution.
You end up having data flowing in the right format for your cloud analytics solution. The main value from this is that you can now run operational workloads, high value or high operational value producing analyticsapplications in your analytics solution.
In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3). Please refer to our earlier Cloudera blog for more details about Ozone’s performance benefits and atomicity guarantees. The same data can be read as an object, or a file.
In this blog, we’ll explore how to harness the power of Kafka to streamline event streaming within a microservices architecture and unlock its full potential for building scalable and responsive systems. Conclusion In this blog, we demonstrated how we can introduce Kafka as a message broker into a microservices architecture.
Overview This blog post describes support for materialized views for the Iceberg table format. Apache Iceberg is a high-performance open table format for petabyte-scale analytic datasets. In a future blog, we will evaluate the incremental versus full rebuild performance. These tables are created as Iceberg tables.
For analyticapplications to properly leverage a hybrid, multi-cloud ecosystem to support modern data architectures, data observability has become even more important. The post You Can’t Hit What You Can’t See appeared first on Cloudera Blog. Source: IDC .
In the meantime, if you want to learn more, please check out this video, which shows how to build an end-to-end Event Analyticsapplication in CDP, using Apache Kafka, Apache Druid, Apache Hive, and Cloudera DataViz. The post An Overview of Real Time Data Warehousing on Cloudera appeared first on Cloudera Blog.
This blog aims to answer two questions as illustrated in the diagram below: How have stream processing requirements and use cases evolved as more organizations shift to “streaming first” architectures and attempt to build streaming analytics pipelines? The post Turning Streams Into Data Products appeared first on Cloudera Blog.
It enables cloud-native applications to store and process mass amounts of data in a hybrid multi-cloud environment and on premises. These could be traditional analyticsapplications like Spark, Impala, or Hive, or custom applications that access a cloud object store natively. Conclusion.
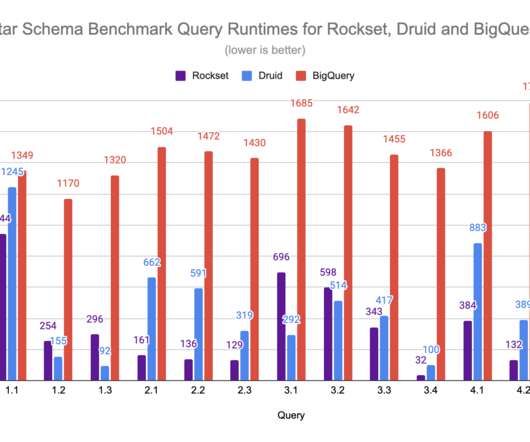
times faster than Druid in the latest performance blog post. Real-time analytics is all about deriving insights and taking actions as soon as data is produced. When broken down into its core requirements, real-time analytics means two things: access to fresh data and fast responses to queries. Learn how Rockset is 1.67
For fast analytic queries against another size of data, it uses in-memory caching and optimised query execution. It is a parallel processing framework for grouped computers to operate large-scale data analyticsapplications. The post 5 Apache Spark Best Practices appeared first on Data Science Blog (English only).
The post Addressing the Three Scalability Challenges in Modern Data Platforms appeared first on Cloudera Blog. benchmarking study conducted by independent 3rd party ).
An object-centric data model is a big deal because it offers the opportunity for a holistic approach and as a database a single source of truth for Process Mining but also for other types of analyticalapplications. The post Object-centric Process Mining on Data Mesh Architectures appeared first on Data Science Blog (English only).
In this blog, we delve into each of these features and how they are giving users more cost controls for their search and AI applications. Users may be building user-facing search and analyticsapplications on data that is updated after minutes or hours.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! If you want to see all of the key requirements of real-time analytics databases, watch my recent talk at the Hive on Designing the Next Generation of Data Systems for Real-Time Analytics , available below.
The Demands of Real-Time Analytics Real-time analyticsapplications have specific demands (i.e., and your solution will only be able to provide valuable real-time analytics if you are able to meet them. Indexing Efficiency Indexing data is another crucial requirement for real-time analyticsapplications.
This leads to extra cost, effort, and risk to stitch together a sub-optimal platform for multi-disciplinary, cloud-based analyticsapplications. The post Altus SDX: Shared services for cloud-based analytics appeared first on Cloudera Blog. Further, much of the value of cloud is for elastic workloads.
The way we’d normally design analyticalapplications is to build something outside of our data environment, manage the infrastructure and compute, connect to Snowflake for the data, take the data back to the compute platform, and give an interface to our users. Click here for all the details.
That’s why JetBlue innovates with real-time analytics and AI, using over 15 machine learning applications in production today for dynamic pricing, customer personalization, alerting applications, chatbots and more.
Cloud PaaS takes this a step further and allows users to focus directly on building data pipelines, training machine learning models, developing analyticsapplications — all the value creation efforts, vs the infrastructure operations. The post The Future of Cloud-based Analytics (Part 3) appeared first on Cloudera Blog.
Now we are releasing the reference architecture for you build your own self-managed SDX foundation for all your cloud-based data and analyticsapplications. Cloud data that can efficiently drive all your machine learning and analytics initiatives. It’s time for a new approach to analytics in the cloud. It’s time for SDX.
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analyticapplications are able to turn the latest data into instant business insights.
Introduction Let’s get this out of the way at the beginning: understanding effective streaming data architectures is hard, and understanding how to make use of streaming data for analytics is really hard. There’s enough content here for its own blog post, but we’ll cover the high-level differences briefly. Kafka or Kinesis ?
Apache HBase® is one of many analyticsapplications that benefit from the capabilities of Intel Optane DC persistent memory. HBase is a distributed, scalable NoSQL database that enterprises use to power applications that need random, real time read/write access to semi-structured data.
When building applications on change data capture (CDC) data using Elasticsearch, you’ll want to architect the system to handle frequent updates or modifications to the existing documents in an index. In this blog, we’ll walk through the different options available for updates including full updates, partial updates and scripted updates.
In this blog, we’ll walk through the benchmark framework, configuration and results. We’ll also delve under the hood of the two databases to better understand why their performance differs when it comes to search and analytics on high-velocity data streams. Rockset achieved up to 4x higher throughput and 2.5x
Using a team of just three administrators (rather than the 15 they needed before) and thanks to SDX providing single consistent context, they can now deploy their Cloudera analyticsapplications to no fewer than three public clouds in less than an hour. With that in place, what will be your first project?
It continuously ingests raw data from multiple sources--data lakes, data streams, databases--into its storage layer and allows fast SQL access from both visualisation tools and analyticapplications.
Hadoop fits heavy, not time-critical analyticsapplications that generate insights for long-term planning and strategic decisions. If you are interested in web development, take a look at our blog post on. Hadoop works with batches while Kafka deals with streams, but all the same, the similarities are obvious. Kafka vs ETL.
The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. This blog will explore the AWS Amazon Kinesis and how this managed platform can revamp data analytics. Table of Content What is Amazon Kinesis? How Amazon Kinesis Works?
And while employing it is a fairly new technology, it already has a wide range of applications. This blog will look at the best contemporary applications of Artificial Intelligence in business. . Applications of AI in Business Operations . Artificial Intelligence in Business .
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content