This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud. In this blog post, we will take a closer look at Azure Databricks, its key features, […] The post Azure Databricks: A Comprehensive Guide appeared first on Analytics Vidhya.
We are thrilled to announce that Cloudera has acquired Eventador , a provider of cloud-native services for enterprise-grade stream processing. We believe Eventador will accelerate innovation in our Cloudera DataFlow streaming platform and deliver more business value to our customers in their real-time analyticsapplications.
Combining Octopai capabilities with Cloudera’s AI powered hybrid data platform provides deeper data understanding, enhanced security, and robust data governance – essential for driving AI and analytics success. This will also accelerate deployment of new data products for AI, gen AI, and analyticsapplications.
Today were going to talk about five streaming cloud integration use cases. Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight data processing. Use Case #1 Online Migration/Cloud Adoption Lets start with the first one. This unlimited testing minimizes your risks.
Today were going to talk about five streaming cloud integration use cases. Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight data processing. Use Case #1 Online Migration/Cloud Adoption Lets start with the first one. This unlimited testing minimizes your risks.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! Finally, the database must be cloud native, so all scaling is automatic and hidden from developers and users. For more details, read my blog post on ALT and why it beats the Lambda architecture for real-time analytics.
Navigating this intricate maze of data can be challenging, and that’s why Apache Ozone has become a popular, cloud-native storage solution that spans any data use case with the performance needed for today’s data architectures. Most traditional analyticsapplications like Hive, Spark, Impala, YARN etc.
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analyticapplications are able to turn the latest data into instant business insights. Cost-Effective.
A global oil and gas company collects, transforms, and distributes over hundreds terabytes of desktop, server, and application log data to their SIEM per day. As the company evolves into a hybrid and multi-cloud strategy, they need to start collecting applications, servers, and network logs from the cloud.
Modern data platforms deliver an elastic, flexible, and cost-effective environment for analyticapplications by leveraging a hybrid, multi-cloud architecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. Ramsey International Modern Data Platform Architecture. What is a data mesh?
DDE is a new template flavor within CDP Data Hub in Cloudera’s public cloud deployment option (CDP PC). It is designed to simplify deployment, configuration, and serviceability of Solr-based analyticsapplications. For the examples presented in this blog, we assume you have a CDP account already. What does DDE entail?
The blog crossed the 2000 members mark (❤️) and I won the best data science newsletter award. Introducing ADBC: Database Access for Apache Arrow — When I see "minimal-overhead alternative to JDBC/ODBC for analyticalapplications" I'm instantly in. I think this is even relevant to data world.
People are gravitating to the analytics services of the large public cloud providers because the “house-brand” offerings seem to be the easiest choice. This leads to extra cost, effort, and risk to stitch together a sub-optimal platform for multi-disciplinary, cloud-based analyticsapplications.
Explosion of data availability from a variety of sources, including on-premises data stores used by enterprise data warehousing / data lake platforms, data on cloud object stores typically produced by heterogenous, cloud-only processing technologies, or data produced by SaaS applications that have now evolved into distinct platform ecosystems (e.g.,
As the market moves toward cloud-based big data and analytics, three qualities emerge as vital for success. Cloud IaaS facilitates resource self-service provisioning, eliminating the hassles of procurement and deployment on-premises. Make sure any cloud-based analytics service meets these criteria.
Overview This blog post describes support for materialized views for the Iceberg table format. Apache Iceberg is a high-performance open table format for petabyte-scale analytic datasets. Starting from the CDW Public Cloud DWX-1.6.1 In a future blog, we will evaluate the incremental versus full rebuild performance.
In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3). Please refer to our earlier Cloudera blog for more details about Ozone’s performance benefits and atomicity guarantees. The same data can be read as an object, or a file.
This blog aims to answer two questions as illustrated in the diagram below: How have stream processing requirements and use cases evolved as more organizations shift to “streaming first” architectures and attempt to build streaming analytics pipelines? Better yet, it works in any cloud environment. Not to worry.
In this blog, we’ll explore how to harness the power of Kafka to streamline event streaming within a microservices architecture and unlock its full potential for building scalable and responsive systems. Conclusion In this blog, we demonstrated how we can introduce Kafka as a message broker into a microservices architecture.
For analyticapplications to properly leverage a hybrid, multi-cloud ecosystem to support modern data architectures, data observability has become even more important. The post You Can’t Hit What You Can’t See appeared first on Cloudera Blog. Source: IDC .
It enables cloud-native applications to store and process mass amounts of data in a hybrid multi-cloud environment and on premises. These could be traditional analyticsapplications like Spark, Impala, or Hive, or custom applications that access a cloud object store natively. Conclusion.
Cloudera offers a platform, Cloudera Data Platform (CDP), for building end-to-end data applications in both the public and private cloud. In addition, we have a webinar and blog explaining how you can use Apache Kudu and Apache Impala to create a time series application within CDP. Building an RTDW with Cloudera.
In 2023, Rockset announced a new cloud architecture for search and analytics that separates compute-storage and compute-compute. It also unlocks ways to make it easier and cheaper to build applications on Rockset. Rockset’s cloud-native architecture contrasts with the tightly coupled architecture of Elasticsearch.
The database for Process Mining is also establishing itself as an important hub for Data Science and AI applications, as process traces are very granular and informative about what is really going on in the business processes. DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Click to enlarge!
Expanding the DTCC ecosystem with Snowflake Native Apps To explain how DTCC is leveraging Snowflake Native Apps, I first need to paint the broader picture of the DTCC Data Cloud on Snowflake. Snowflake Native Apps allow my team to manage the application layer in much the same way that we manage our Data Cloud layer.
That’s why JetBlue innovates with real-time analytics and AI, using over 15 machine learning applications in production today for dynamic pricing, customer personalization, alerting applications, chatbots and more. Rockset took that time down to days due to the ease of converting a SQL query into a REST API.”
Cloud promises many advantages as an environment for machine learning and analytics. Cloud makes it fast and easy to spin up resources for new applications. Cloud offers elasticity of those resources to efficiently support transient analytics workloads and data pipelines.
In scenarios involving analytics on massive data streams, we’re often asked the maximum throughput and lowest data latency Rockset can achieve and how it stacks up to other databases. In this blog, we’ll walk through the benchmark framework, configuration and results. Rockset achieved up to 4x higher throughput and 2.5x
A single cluster can span across multiple data centers and cloud facilities. cloud data warehouses — for example, Snowflake , Google BigQuery, and Amazon Redshift. Depending on the type of deployment (cloud or on-premise), cluster size, and the number of integrations, the deployment may take days to weeks to even months.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! The truth is that modern cloud native SQL databases support all of the key features necessary for real-time analytics , including: Mutable data for incredibly fast data ingestion and smooth handling of late-arriving events.
Cloudera customers who want more flexibility in how and where they run their applications can benefit from Intel Optane DC persistent memory as well. A key characteristic of an enterprise data cloud is its ability to run multiple workloads on shared data without encountering “noisy neighbor” problems.
Uniquely, Cloudera’s machine learning and analytics platform have a fundamental characteristic called the Shared Data Experience (SDX) that provides just that. When transient cloud infrastructures are used to complement existing on-premises investments, establishing and capturing this data context is essential for success.
Introduction Let’s get this out of the way at the beginning: understanding effective streaming data architectures is hard, and understanding how to make use of streaming data for analytics is really hard. A few noteworthy points: Self-managed Kafka can be deployed on-premises or in the cloud. Kafka or Kinesis ?
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! If you want to see all of the key requirements of real-time analytics databases, watch my recent talk at the Hive on Designing the Next Generation of Data Systems for Real-Time Analytics , available below.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! And when it comes to the cloud and developers, that means wasted money. Take the Hive analytics database that is part of the Hadoop stack. Fixing and rerunning the queries is a time-wasting hassle.
Are you confused about choosing the best cloud platform for your next data engineering project ? AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. So, are you ready to explore the differences between two cloud giants, AWS vs. google cloud? Let’s get started!
The Demands of Real-Time Analytics Real-time analyticsapplications have specific demands (i.e., and your solution will only be able to provide valuable real-time analytics if you are able to meet them. Indexing Efficiency Indexing data is another crucial requirement for real-time analyticsapplications.
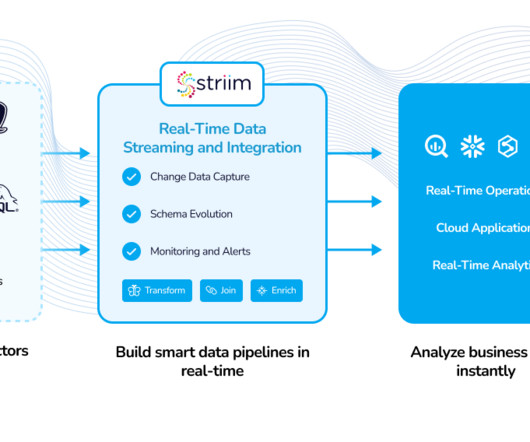
Data Mesh is revolutionizing event streaming architecture by enabling organizations to quickly and easily integrate real-time data, streaming analytics, and more. Striim is a cloud-native Data Mesh platform that offers features such as automated data mapping, real-time data integration, streaming analytics, and more.
The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. This blog will explore the AWS Amazon Kinesis and how this managed platform can revamp data analytics. As of 2024, about 73% of enterprises have deployed a hybrid cloud.
When building applications on change data capture (CDC) data using Elasticsearch, you’ll want to architect the system to handle frequent updates or modifications to the existing documents in an index. In this blog, we’ll walk through the different options available for updates including full updates, partial updates and scripted updates.
Practices centered on software engineering principles can create a barrier to entry for teams with skilled data wranglers looking to take their infrastructure to the next level with cloud-native tools like Matillion for the Snowflake Data Cloud. When Is ZDLC Better Than SDLC?
With helpful illustrations and thorough explanations, it assists readers in comprehending how to use Spark for big data processing and analyticsapplications. Continuously Learn and Stay Curious To broaden your knowledge and skills, read books, follow blogs, join online communities, and engage in data engineering initiatives.
It continuously ingests raw data from multiple sources--data lakes, data streams, databases--into its storage layer and allows fast SQL access from both visualisation tools and analyticapplications. And if you are planning on copying huge amounts of data to Rockset, this also isn’t a problem.
Database applications also help in data-driven decision-making by providing data analysis and reporting tools. In this blog, we will deep dive into database system applications in DBMS, and their components and look at a list of database applications. What are Database Applications? Spatial Database (e.g.-
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content