This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud. A collaborative and interactive workspace allows users to perform big dataprocessing and machine learning tasks easily.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! Maintaining two dataprocessing paths creates extra work for developers who must write and maintain two versions of code, as well as greater risk of data errors.
By leveraging the flexibility of a data lake and the structured querying capabilities of a data warehouse, an open data lakehouse accommodates raw and processeddata of various types, formats, and velocities. Learn more about the Cloudera Open Data Lakehouse here.
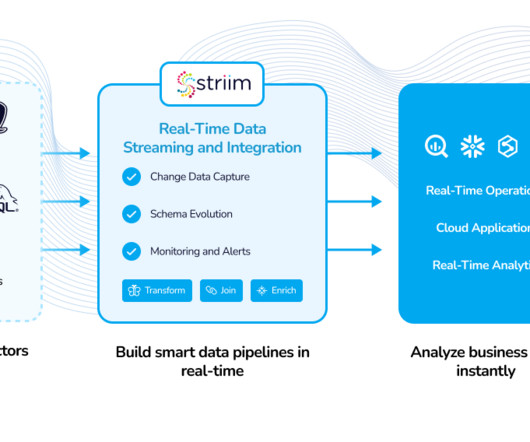
Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight dataprocessing. Read on, or watch the 9-minute video: Lets focus on how to use streaming data integration in cloud initiatives, and the five common scenarios that we see.
Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight dataprocessing. Read on, or watch the 9-minute video: Lets focus on how to use streaming data integration in cloud initiatives, and the five common scenarios that we see.
DDE is a new template flavor within CDP Data Hub in Cloudera’s public cloud deployment option (CDP PC). It is designed to simplify deployment, configuration, and serviceability of Solr-based analyticsapplications. data best served through Apache Solr). data best served through Apache Solr). What does DDE entail?
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. In addition to understanding the attributes of an RTDW, it is useful to look at the types of applications that can be built within the RTDW category.
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. Kafka can also be used to stream data from IoT devices or sensors. We will come up with more such use cases in our upcoming blogs.
Typically, organizations that leverage narrow-scope, single public cloud solutions for dataprocessing face incremental costs as they scale to address more complex use cases or an increased number of users. The post Addressing the Three Scalability Challenges in Modern Data Platforms appeared first on Cloudera Blog.
Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the dataprocessing components up the stream to address these real-time needs. . Conclusion. Not in the manufacturing space? Not to worry.
For fast analytic queries against another size of data, it uses in-memory caching and optimised query execution. It is a parallel processing framework for grouped computers to operate large-scale dataanalyticsapplications.
So whenever you hear that Process Mining can prepare RPA definitions you can expect that Task Mining is the real deal. An object-centric data model is a big deal because it offers the opportunity for a holistic approach and as a database a single source of truth for Process Mining but also for other types of analyticalapplications.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! The tradeoff of these first-generation SQL-based big data systems was that they boosted dataprocessing throughput at the expense of higher query latency.
The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. Amazon AWS Kinesis makes it possible to process and analyze data from multiple sources in real-time. What can I do with Kinesis Data Streams? How Amazon Kinesis Works?
Introduction Let’s get this out of the way at the beginning: understanding effective streaming data architectures is hard, and understanding how to make use of streaming data for analytics is really hard. Stream processing or an OLAP database? Kafka or Kinesis ? Open source or fully managed?
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative data storage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
popular SQL and NoSQL database management systems including Oracle, SQL Server, Postgres, MySQL, MongoDB, Cassandra, and more; cloud storage services — Amazon S3, Azure Blob, and Google Cloud Storage; message brokers such as ActiveMQ, IBM MQ, and RabbitMQ; Big Dataprocessing systems like Hadoop ; and. Kafka vs ETL.
What are the four principles of a Data Mesh, and what problems do they solve? A data mesh is technology-agnostic and underpins four main principles described in-depth in this blog post by Zhamak Dehghani. As a result, learning about them and the problems they were created to tackle is important.
Are you confused about choosing the best cloud platform for your next data engineering project ? AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. It is a serverless data integration service that makes data preparation easier, cheaper and faster. Let’s get started!
They enable organizations to use data as an asset, resulting in greater operational efficiency, improved decision-making, and an edge over competitors in today's data-driven corporate world. Database applications also help in data-driven decision-making by providing data analysis and reporting tools.
There are several big data and business analytics companies that offer a novel kind of big data innovation through unprecedented personalization and efficiency at scale. Which big dataanalytic companies are believed to have the biggest potential? “It’s not a “butt in seat” culture.
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! But the concern is - how do you become a big data professional?
of data engineer job postings on Indeed? If you are still wondering whether or why you need to master SQL for data engineering, read this blog to take a deep dive into the world of SQL for data engineering and how it can take your data engineering skills to the next level. But how does SQL play a vital role here?
Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analyticaldataprocessing and storage capabilities within a cloud-based infrastructure. Enter Snowflake The Snowflake Data Cloud is one of the most popular and powerful CDW providers.
Translate the machine learning models defined by data scientists from environments like Python and R notebooks to analyticapplications. 3) Machine Learning Engineer vs Data Scientist You might hear the terms data scientist and machine learning engineer used interchangeably but these are two different job roles.
Ace your big data interview by adding some unique and exciting Big Data projects to your portfolio. This blog lists over 20 big data projects you can work on to showcase your big data skills and gain hands-on experience in big data tools and technologies.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content