This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditionally, web sockets were the go-to option when it came to real-time applications, but think of a situation whereby there’s server downtime. It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
Deep Dive into Time Series and Event Analytics Specialized RTDW , featuring Apache Druid, Apache Hive, Apache Kafka, and Cloudera DataViz. In addition, we have a webinar and blog explaining how you can use Apache Kudu and Apache Impala to create a time series application within CDP. Micro-batch stream processing engine.
The blog crossed the 2000 members mark (❤️) and I won the best data science newsletter award. Introducing ADBC: Database Access for Apache Arrow — When I see "minimal-overhead alternative to JDBC/ODBC for analyticalapplications" I'm instantly in. I think this is even relevant to data world.
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analyticapplications are able to turn the latest data into instant business insights. Cost-Effective.
Intro In recent years, Kafka has become synonymous with “streaming,” and with features like Kafka Streams, KSQL, joins, and integrations into sinks like Elasticsearch and Druid, there are more ways than ever to build a real-time analyticsapplication around streaming data in Kafka.
Introduction Let’s get this out of the way at the beginning: understanding effective streaming data architectures is hard, and understanding how to make use of streaming data for analytics is really hard. Kafka or Kinesis ? A few noteworthy points: Self-managed Kafka can be deployed on-premises or in the cloud.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! To deliver real-time analytics, companies need a modern technology infrastructure that includes these three things: A real-time data source such as web clickstreams, IoT events produced by sensors, etc.
The AWS training will prepare you to become a master of the cloud, storing, processing, and developing applications for the cloud data. This blog will explore the AWS Amazon Kinesis and how this managed platform can revamp data analytics. What is the difference between Amazon Kinesis and Kafka? How Amazon Kinesis Works?
To find out, we decided to test the streaming ingestion performance of Rockset’s next generation cloud architecture and compare it to open-source search engine Elasticsearch , a popular sink for Apache Kafka. In this blog, we’ll walk through the benchmark framework, configuration and results. Why measure streaming data ingestion?
The Demands of Real-Time Analytics Real-time analyticsapplications have specific demands (i.e., and your solution will only be able to provide valuable real-time analytics if you are able to meet them. Indexing Efficiency Indexing data is another crucial requirement for real-time analyticsapplications.
It continuously ingests raw data from multiple sources--data lakes, data streams, databases--into its storage layer and allows fast SQL access from both visualisation tools and analyticapplications. Kafka connectors are available within Rockset to consume streams from Kafka in real time.
However, Elasticsearch has several limitations that make it less suitable when it comes to running more complex analytical queries. Rockset, on the other hand, provides full-featured SQL and an API endpoint interface that allows developers to quickly join across data sources like DynamoDB and Kafka.
It covers popular technologies such as Apache Kafka, Apache Storm, and Apache Hadoop, giving users practical advice on developing and executing effective data pipelines. With helpful illustrations and thorough explanations, it assists readers in comprehending how to use Spark for big data processing and analyticsapplications.
This blog lists over 20 big data projects you can work on to showcase your big data skills and gain hands-on experience in big data tools and technologies. The Apache Hadoop open source big data project ecosystem with tools such as Pig, Impala, Hive, Spark, Kafka Oozie, and HDFS can be used for storage and processing.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! Explosion in Streaming Data Before Kafka, Spark and Flink, streaming came in two flavors: Business Event Processing (BEP) and Complex Event Processing (CEP). Many (Kafka, Spark and Flink) were open source.
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
We believe Eventador will accelerate innovation in our Cloudera DataFlow streaming platform and deliver more business value to our customers in their real-time analyticsapplications. The post Cloudera acquires Eventador to accelerate Stream Processing in Public & Hybrid Clouds appeared first on Cloudera Blog.
But as data streaming technologies like Apache Kafka and Apache Flink have evolved, only until recently have SQL interfaces become deeply integrated. The post Using SQL to democratize streaming data appeared first on Cloudera Blog. For good reason – it’s easy to use, mature, powerful, and completely ubiquitous.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







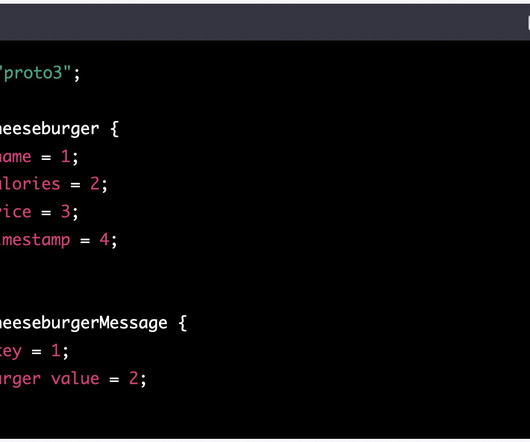


















Let's personalize your content