This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud. A collaborative and interactive workspace allows users to perform big dataprocessing and machine learning tasks easily.
Maintaining two dataprocessing paths creates extra work for developers who must write and maintain two versions of code, as well as greater risk of data errors. Developers and data scientists also have little control over the streaming and batch data pipelines.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Spark Streaming enhances the core engine of Apache Spark by providing near-real-time processing capabilities, which are essential for developing streaming analyticsapplications.
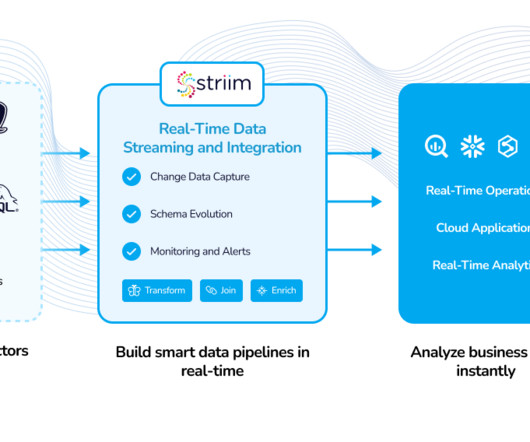
Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight dataprocessing. Read on, or watch the 9-minute video: Lets focus on how to use streaming data integration in cloud initiatives, and the five common scenarios that we see.
Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight dataprocessing. Read on, or watch the 9-minute video: Lets focus on how to use streaming data integration in cloud initiatives, and the five common scenarios that we see.
By leveraging the flexibility of a data lake and the structured querying capabilities of a data warehouse, an open data lakehouse accommodates raw and processeddata of various types, formats, and velocities.
Typically, organizations that leverage narrow-scope, single public cloud solutions for dataprocessing face incremental costs as they scale to address more complex use cases or an increased number of users. benchmarking study conducted by independent 3rd party ).
DDE is a new template flavor within CDP Data Hub in Cloudera’s public cloud deployment option (CDP PC). It is designed to simplify deployment, configuration, and serviceability of Solr-based analyticsapplications. data best served through Apache Solr). data best served through Apache Solr). What does DDE entail?
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. In addition to understanding the attributes of an RTDW, it is useful to look at the types of applications that can be built within the RTDW category.
Showing how Kappa unifies batch and streaming pipelines The development of Kappa architecture has revolutionized dataprocessing by allowing users to quickly and cost-effectively reduce data integration costs. Finally, kappa architectures are not suitable for all types of dataprocessing tasks.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Finnhub API with Kafka for Real-Time Financial Market Data Pipeline 3.
Commit Logs and Stream Processing: Kafka’s log-based storage and replayability make it ideal for stream processing use cases. Apache Kafka in Microservices Apache Kafka is an excellent choice for decoupled microservices architecture.
For fast analytic queries against another size of data, it uses in-memory caching and optimised query execution. It is a parallel processing framework for grouped computers to operate large-scale dataanalyticsapplications.
The tradeoff of these first-generation SQL-based big data systems was that they boosted dataprocessing throughput at the expense of higher query latency. Hive implemented an SQL layer on Hadoop’s native MapReduce programming paradigm. As a result, the use cases remained firmly in batch mode.
For example, processeddata can be stored in Amazon S3 for archival and batch processing, loaded into Amazon Redshift for data warehousing and complex queries, or indexed in Amazon Elasticsearch Service for full-text search and analytics. This supplies data to the applications waiting to use it.
Apache ORC (Optimized Row Columnar) : In 2013, ORC was developed for the Hadoop ecosystem to improve the efficiency of data storage and retrieval. This development was crucial for enabling both batch and streaming data workflows in dynamic environments, ensuring consistency and durability in big dataprocessing.
So whenever you hear that Process Mining can prepare RPA definitions you can expect that Task Mining is the real deal. An object-centric data model is a big deal because it offers the opportunity for a holistic approach and as a database a single source of truth for Process Mining but also for other types of analyticalapplications.
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative data storage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the dataprocessing components up the stream to address these real-time needs. .
This platform provides a range of IoT tools and technologies to help developers build and manage IoT systems, including device management, dataprocessing, and analytics. Dataprocessing of large volumes of data including real-time dataprocessing, storage, and analysis.
It has expanded to various industries and applications, including IoT sensor data, financial data, web analytics, gaming behavioral data, and many more use cases. It supports various dataprocessing models such as stream and batch processing (both covered in part 2 of this series), and complex event processing.
popular SQL and NoSQL database management systems including Oracle, SQL Server, Postgres, MySQL, MongoDB, Cassandra, and more; cloud storage services — Amazon S3, Azure Blob, and Google Cloud Storage; message brokers such as ActiveMQ, IBM MQ, and RabbitMQ; Big Dataprocessing systems like Hadoop ; and. Kafka vs ETL.
Publish: Transformed data is then published either back to on-premises sources like SQL Server or kept in cloud storage. This makes the data ready for consumption by BI tools, analyticsapplications, or other systems. Manage Workflow: ADF manages these processes through time-sliced, scheduled pipelines.
Java does not support Read-Evaluate-Print-Loop (REPL), which is a major deal-breaker when choosing a programming language for big dataprocessing. Python is one of the de-facto languages of Data Science. It’s popular for research, plotting, and data analysis. Support for ‘data science’ related work.
The next solution for self-service data analysis from Qlik is called Qlik Sense. It provides analytics features for different types of accounts, such as associated research and navigation, clever visualization, data preprocessing, and much more, making it one of the top BI tools. Zoho Analytics.
Popular instances where GCP is used widely are machine learning analytics, application modernization, security, and business collaboration. It is a serverless data integration service that makes data preparation easier, cheaper and faster.
This specific tool is frequently used for dataprocessing, visualization, and polling. The R language should be respected, though, since it has several procedures built into it that are used to analyze statistical data. Additionally, anyone’s PC may quickly simply download the R language.
The company targets to deliver values to its customers through the free SaaS based analyticsapplications so that it can build credibility with the clients to encourage them to buy more. The products and services of Cloudera are changing the economics of big data analysis , BI, dataprocessing and warehousing through Hadooponomics.
A data mesh is technology-agnostic and underpins four main principles described in-depth in this blog post by Zhamak Dehghani. The four data mesh principles aim to solve major difficulties that have plagued data and analyticsapplications for a long time.
Cassandra specializes in handling high-volume, high-velocity, and high-reliability data, making it perfect for real-time dataprocessing and fault tolerance applications. Apache Cassandra): Instead of the usual row-wise technique employed by relational databases, columnar databases store data in columns.
That way every server, stores a fragment of the entire data set and all such fragments are replicated on more than one server to achieve fault tolerance. Hadoop MapReduce MapReduce is a distributed dataprocessing framework. Apache Hadoop provides solution to the problem caused by large volume of complex data.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
This entails managing data access, restricting data movement inside the warehouse, and SQL query optimization strategies. SQL enables engineers to perform data transformations within data warehouses, significantly accelerating dataprocessing. are applied directly to the data in memory.
Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analyticaldataprocessing and storage capabilities within a cloud-based infrastructure. Enter Snowflake The Snowflake Data Cloud is one of the most popular and powerful CDW providers.
Translate the machine learning models defined by data scientists from environments like Python and R notebooks to analyticapplications. 3) Machine Learning Engineer vs Data Scientist You might hear the terms data scientist and machine learning engineer used interchangeably but these are two different job roles.
A big data project is a data analysis project that uses machine learning algorithms and different dataanalytics techniques on a large dataset for several purposes, including predictive modeling and other advanced analyticsapplications.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content