


Unify your data: AI and Analytics in an Open Lakehouse
Cloudera
MAY 30, 2024
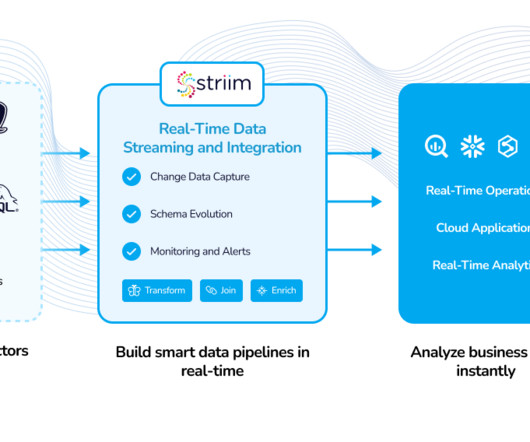
By leveraging the flexibility of a data lake and the structured querying capabilities of a data warehouse, an open data lakehouse accommodates raw and processed data of various types, formats, and velocities.

















Let's personalize your content