This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There is also a speed layer typically built around a stream-processingtechnology such as Amazon Kinesis or Spark. It provides instant views of the real-time data. Maintaining two dataprocessing paths creates extra work for developers who must write and maintain two versions of code, as well as greater risk of data errors.
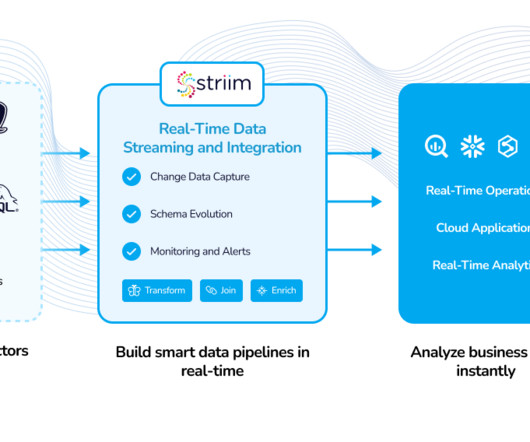
Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight dataprocessing. Read on, or watch the 9-minute video: Lets focus on how to use streaming data integration in cloud initiatives, and the five common scenarios that we see.
Streaming cloud integration moves data continuously in real time between heterogeneous databases, with in-flight dataprocessing. Read on, or watch the 9-minute video: Lets focus on how to use streaming data integration in cloud initiatives, and the five common scenarios that we see.
These seemingly unrelated terms unite within the sphere of big data, representing a processing engine that is both enduring and powerfully effective — Apache Spark. It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs.
Explosion of data availability from a variety of sources, including on-premises data stores used by enterprise data warehousing / data lake platforms, data on cloud object stores typically produced by heterogenous, cloud-only processingtechnologies, or data produced by SaaS applications that have now evolved into distinct platform ecosystems (e.g.,
Get ready to delve into fascinating data engineering project concepts and explore a world of exciting data engineering projects in this article. Before working on these initiatives, you should be conversant with topics and technologies. Data pipeline best practices should be shown in these initiatives.
Users today are asking ever more from their data warehouse. This is resulting in advancements of what is provided by the technology, and a resulting shift in the art of the possible. An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. General Purpose RTDW. What’s Next?
Showing how Kappa unifies batch and streaming pipelines The development of Kappa architecture has revolutionized dataprocessing by allowing users to quickly and cost-effectively reduce data integration costs.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. And COVID-19 made ‘zoom’ a synonym for a videoconference.
Commit Logs and Stream Processing: Kafka’s log-based storage and replayability make it ideal for stream processing use cases. Stay tuned to get all the updates about our upcoming blogs on the cloud and the latest technologies. How to orchestrate Queue-based Microservices with AWS Step Functions and Amazon SQS?
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative data storage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
The tradeoff of these first-generation SQL-based big data systems was that they boosted dataprocessing throughput at the expense of higher query latency. GraphQL’s main analytics shortcoming is its lack of expressive power to join two disparate datasets based on the value of specific fields in those two datasets.
Cloud Technology has risen in the latter half of the past decade. Amazon and Google are the big bulls in cloud technology, and the battle between AWS and GCP has been raging on for a while. The Google trends graph above shows how the two technologies have increased over the years, with AWS maintaining a significant margin over GCP.
The IoT is a network of physical objects embedded with technology, such as sensors and software. The purpose of IoT is to connect as well as exchange the data within other available devices over the internet. Dataprocessing of large volumes of data including real-time dataprocessing, storage, and analysis.
According to NASSCOM, the global big dataanalytics market is anticipated to reach $121 billion by 2016. Another research report by IDC predicts 27% compound annual growth rate for big data services and technologies by end of 2017 which equals 6 times the CAGR of the IT market as a whole.
R is available as an open language of programming for statistical computing and dataanalytics, and R often has a command-line API. The newest cutting-edge technology is the R programming language. This specific tool is frequently used for dataprocessing, visualization, and polling.
Any business user may quickly resolve difficulties using current and skilled Business Intelligence (BI) technologies, even without intensive IT participation. They Do Away with Manual Processes: The technology automatically refreshes your KPI dashboard with current data. Zoho Analytics.
It enables data to be accessed, transferred, and used in various ways such as creating dashboards or running analytics. The Data Mesh architecture is based on four core principles: scalability, resilience, elasticity, and autonomy. What are the four principles of a Data Mesh, and what problems do they solve?
It has expanded to various industries and applications, including IoT sensor data, financial data, web analytics, gaming behavioral data, and many more use cases. However, streaming data poses a unique challenge for analytics because it requires specialized technologies and approaches to achieve.
The Big data market was worth USD 162.6 Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big datatechnologies to improve its techniques and marketing campaigns. DataProcessing: This is the final step in deploying a big data model.
Hadoop is beginning to live up to its promise of being the backbone technology for Big Data storage and analytics. Companies across the globe have started to migrate their data into Hadoop to join the stalwarts who already adopted Hadoop a while ago. Hadoop MapReduce MapReduce is a distributed dataprocessing framework.
Cassandra specializes in handling high-volume, high-velocity, and high-reliability data, making it perfect for real-time dataprocessing and fault tolerance applications. Apache Cassandra): Instead of the usual row-wise technique employed by relational databases, columnar databases store data in columns.
Yet, those that do achieve this level of maturity from their data stack are able to unlock breakthrough successes while leaving competitors years behind in innovation. Perhaps the largest roadblock of this data-driven utopia is the continued reliance on a patchwork of legacy, on-premise technologies like Teradata, Netezza, Oracle, etc.,
According to the 8,786 data professionals participating in Stack Overflow's survey, SQL is the most commonly-used language in data science. Despite the buzz surrounding NoSQL , Hadoop , and other big datatechnologies, SQL remains the most dominant language for data operations among all tech companies.
Behind this technology are data science teams and machine learning engineers who have not only built smart data science projects but constantly maintain them to ensure these machine learning applications work flawlessly. With these Data Science Projects in Python , your career is bound to reach new heights.
Ace your big data interview by adding some unique and exciting Big Data projects to your portfolio. This blog lists over 20 big data projects you can work on to showcase your big data skills and gain hands-on experience in big data tools and technologies.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content