

The Good and the Bad of Apache Spark Big Data Processing
AltexSoft
JULY 18, 2023
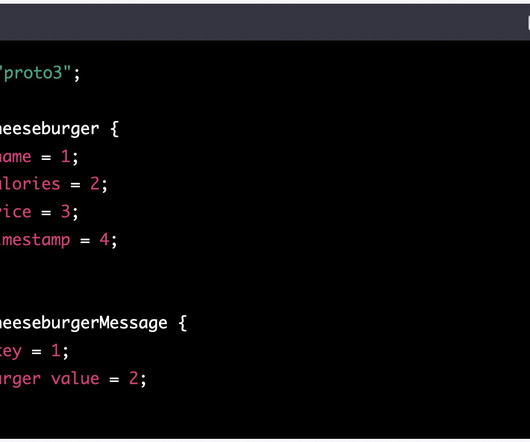
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Spark Streaming enhances the core engine of Apache Spark by providing near-real-time processing capabilities, which are essential for developing streaming analytics applications.











Let's personalize your content