This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
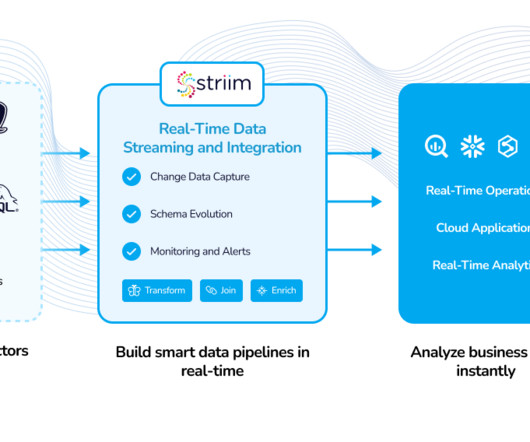
On top of that, I had to make that data available to our custom-built application via a secure RESTful endpoint with a less than one second response time. I was amazed that I could do all of that without having to initially move and transform the data. One SQL statement got it done.
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analyticapplications are able to turn the latest data into instant business insights. > Minutes.
This means new dataschemas, new sources and new types of queries pop up every few days. Analysts predict that by 2025 more than 30% of data will be real-time in nature, and by 2022, more than half of major new business systems will incorporate continuous intelligence that uses real-time context data to improve decisions.
A data mesh is technology-agnostic and underpins four main principles described in-depth in this blog post by Zhamak Dehghani. The four data mesh principles aim to solve major difficulties that have plagued data and analyticsapplications for a long time.
Real-time data streams typically power analytical or dataapplications whereas batch systems were built to power static dashboards. Data Observability: With the real-time data stack, companies ingest higher volumes of data and act on them almost instantly.
It also performs better when dealing with large amounts of data since it can quickly scale up and down according to your needs. Finally, NoSQL databases are frequently used in real-time analyticsapplications, such as streaming data from IoT sensors. It also discusses several kinds of data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content