This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. Before building your own data architecture from scratch though, why not steal – er, learn from – what industry leaders have already figured out?
Data mesh and data fabric are two modern data architectures that serve to enable better data flow, faster decision-making, and more agile operations. Both architectures share the goal of making data more actionable and accessible for users within an organization.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold.
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Here’s a closer look.
Traditional Business Intelligence (BI) aren’t built for modern data platforms and don’t work on modern architectures. Holding onto old BI technology while everything else moves forward is holding back organizations.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. Adopting an Open Table Format architecture is becoming indispensable for modern data systems. In this blog, we will discuss: What is the Open Table format (OTF)?
Would you like help maintaining high-quality data across every layer of your Medallion Architecture? What to Expect: Winning Strategies for Each Medallion Layer: Discover how to tackle the unique data quality challenges of Bronze, Silver, and Gold layers in Medallion Architecture.
In this episode Tobias Macey shares his thoughts on the challenges that he is facing as he prepares to build the next set of architectural layers for his data platform to enable a larger audience to start accessing the data being managed by his team. With Materialize, you can! Want to see Starburst in action? Want to see Starburst in action?
During the InferESG project we made a pivotal decision to create an alternative architecture, one that sits parallel to the agentic framework used for the conversational part of the system. We found that these two architectures can work harmoniously together, each addressing different aspects of the ESG analysis challenge.
Read more about how to simplify the deployment and scalability of your embedded analytics, along with important considerations for your: Environment Architecture: An embedded analytics architecture is very similar to a typical web architecture. Deployment: Benefits and drawbacks of hosting on premises or in the cloud.
But complexity stands in the way: incompatible platforms, brittle pipelines, fragmented architectures, and the growing pressure of data privacy and compliance risks make it challenging for teams to deliver trusted, real-time data to models and applications. Define the must-have characteristics of a data streaming architecture.
In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s. Data marts soon evolved as a core part of a DW architecture to eliminate this noise. financial reporting, customer analytics, supply chain management).
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
At Yelp, we encountered challenges that prompted us to enhance the training time of our ad-revenue generating models, which use a Wide and Deep Neural Network architecture for predicting ad click-through rates (pCTR). These models handle large tabular datasets with small parameter spaces, requiring innovative data solutions.
Every data-driven project calls for a review of your data architecture—and that includes embedded analytics. Before you add new dashboards and reports to your application, you need to evaluate your data architecture with analytics in mind. 9 questions to ask yourself when planning your ideal architecture.
Data flow architecture 3. Define SLAs so stakeholders know what to expect 3.1.4. Define checks to ensure the output dataset is usable 3.2. Identify what tool to use to process data 3.3.
We delve into the architecture of Kuzu, an embedded graph database designed for high performance, exploring its unique storage format, query planning techniques like Sideway Information Passing (SIP), and the rationale behind its schema-based approach.
We originally built M3 to support Uber’s scale on a microservices/container (cloud native) architecture. It was that very architecture that created the scale, reliability, performance and cost-efficiency challenges. None of the existing vendors had built and optimized for a cloud-native architecture.
And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. What are the technical/architectural/UX challenges that have hindered the progression of lakehouses? Want to see Starburst in action? Want to see Starburst in action?
ETL and ELT pipelines form the foundation of any data product, and Airflow is the open-source data orchestrator specifically designed for moving and transforming data in ETL and ELT pipelines.
Modern data stacks provide the necessary flexibility and efficiency for analytics and AI. Learn how the Databricks Data Intelligence Platform makes use of them.
The debate around table formats and Lakehouse architectures continues, but the focus is on unifying data ecosystems to enable AI-driven insights. The shift towards intelligent data platforms will continue, with enterprises seeking to seamlessly integrate structured and unstructured data, ensuring quality, governance, and trustworthiness.
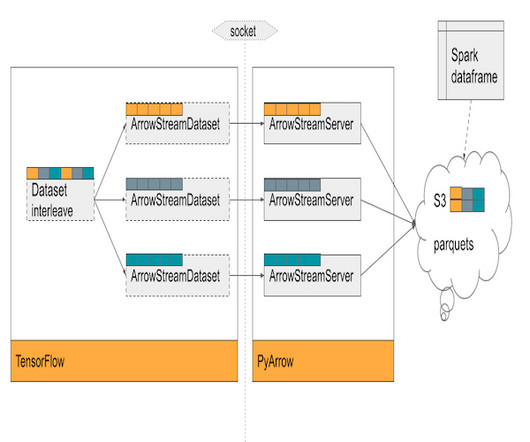
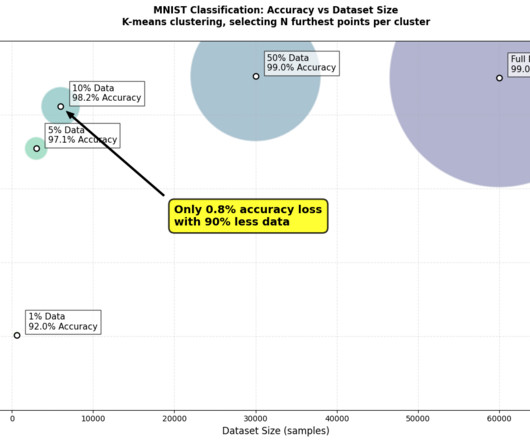
Methodology I used LeNet-5 as my model architecture. Experiment with how model architecture impacts the performance of data pruning strategies. Then using one of the strategies below I pruned the training dataset of MNIST and trained a model. Testing was done against the full testset. Full code and results available here onGitHub.
You should be able to keep the familiarity of SQL and the proven architecture of cloud warehouses, but swap the decades-old batch computation model for an efficient incremental engine to get complex queries that are always up-to-date. With Materialize, you can! Want to see Starburst in action? Want to see Starburst in action?
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
In this new webinar, Alex Salazar and Nate Barbettini will break down the emerging AI architecture that makes action possible, and how it differs from traditional integration approaches. But, turning a model into a reliable, secure workflow agent isn’t as simple as plugging in an API.
Metadata maturity is key to a strong foundation Metadata management maturity is growing in importance, especially with the rise of new data management architectures like data mesh (which takes a decentralized approach) and data fabric (which takes a unified approach).
High-level architecture The diagram above shows a high-level architecture of Cloudera AI Inference service in context: KServe and Knative handle model and application orchestration, respectively. We will dive deeper into the architecture in our next post, so please stay tuned. We also outlined many of its capabilities.
Architecture Difference The first difference is the Data Model. The fourth difference is the Lakehouse Architecture. Fluss embraces the Lakehouse Architecture. On the other hand, Fluss is a Kappa Architecture ; it stores one copy of data and presents it as a stream or a table, depending on the use case.
Leveraging Clouderas hybrid architecture, the organization optimized operational efficiency for diverse workloads, providing secure and compliant operations across jurisdictions while improving response times for public health initiatives. This transition streamlined data analytics workflows to accommodate significant growth in data volumes.
Faster and high-quality inference with a Mixture of Experts Architecture (MoE) Llama 4 are the first models from Meta to use a MoE architecture a single token activates only a fraction of the total parameters. Within Snowflake, Llama 4 Maverick and Llama 4 Scout can be integrated with gen AI applications.
Cortex AI makes available functions to process unstructured data, create vector embeddings and run vector search, deploy foundational LLMs, build retrieval-augmented generation (RAG) architectures or chat with structured data in one unified architecture. This unified stack allows our customers to spend their time on driving AI ROI.
As data volumes grow and AI automation expands, cost efficiency in processing with LLMs depends on both system architecture and model flexibility. This isn't incremental improvement it's a transformational efficiency gain that saves thousands of labor hours and dramatically accelerates response times.
Its multi-cluster shared data architecture is one of its primary features. Because of the architecture’s ability to abstract infrastructure complexity, users can focus solely on data workflows. This blog post explains the main distinctions between these two in terms of architecture, features, integration, and use cases.
At Zalando, our event-driven architecture for Price and Stock updates became a bottleneck, introducing delays and scaling challenges. You'll learn about the caching strategies, low-latency optimizations, and architectural decisions that enabled us to deliver this performance. If so, a simple request"Where do I get Product data?"could
However, with the introduction of the Transformer architecture—initially successful in Natural Language Processing (NLP)—the landscape has shifted. In this blog, we will explore the underlying architecture of transformer-based large vision models, offering insights into how they function. What Are Large Vision Models?
Traditional data architectures struggle to handle these workloads, and without a robust, scalable hybrid data platform, the risk of falling behind is real. As more data is processed, carriers increasingly need to adopt hybrid cloud architectures to balance different workload demands.
Thats where ThoughtSpots architecture comes in. Analytics architecture: ThoughtSpots AI-native architecture and advanced semantic model augment LLM reasoning, using search tokens to improve text-to-SQL accuracy and provide greater transparency.
To name a few: privacy and security considerations compliance demands interest in emerging data management architectures like data mesh and data fabric increased AI adoption The findings show that data governance is the most-cited data challenge inhibiting progress toward AI initiatives (62%). This is likely driven by various factors.
Technical Design LLM as Relevance Model Model Architecture We use a cross-encoder language model to predict a Pins relevance to a query, along with Pin text, as shown in Figure 1. Figure 1: The cross-encoder architecture in the relevance teacher model. The task is formulated as a multiclass classification problem.
Summary Data lakehouse architectures have been gaining significant adoption. To accelerate adoption in the enterprise Microsoft has created the Fabric platform, based on their OneLake architecture. To accelerate adoption in the enterprise Microsoft has created the Fabric platform, based on their OneLake architecture.
The future of data querying with Natural Language — What are all the architecture block needed to make natural language query working with data (esp. when you have a semantic layer). Hard data integration problems — As always Max describes the best way the reality.
They’re basically architectural blueprints for moving and processing your data. Lambda Architecture Pattern 4. Kappa Architecture Pattern 5. Lambda Architecture Pattern Here’s where things get interesting. That’s where data pipeline design patterns come in. Batch Processing Pattern 2.
And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. Can you start by describing the FDAP stack and how the components combine to provide a foundational architecture for database engines? Want to see Starburst in action?
Data and AI architecture matter “Before focusing on AI/ML use cases such as hyper personalization and fraud prevention, it is important that the data and data architecture are organized and structured in a way which meets the requirements and standards of the local regulators around the world.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content