This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
Designing a declarative data stack: from theory to practice — Related to the previous article Simon wrote a great article about the things to have in mind when we build a proprietary DSL for a declarative data stack. Meaning: a YAML configuration system for ingestion and transformations, and now, visualisation with BI-as-code.
The company wants to combine its sales, inventory, and customer data in order to facilitate real-time reporting and predictive analytics. Azure, Power BI, and Microsoft 365 are already widely used by ShopSmart, which is in line with Fabric’s integrated ecosystem. Next, we will see what Snowflake is What is Snowflake?
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
By making the software be the owner of the data that it generates, we have to go through the trouble of extracting the information to then be used elsewhere. The team at Cinchy are working to bring about a new paradigm of software architecture that puts the data as the central element. No more scripts, just SQL.
Summary The ecosystem for data tools has been going through rapid and constant evolution over the past several years. These technological shifts have brought about corresponding changes in data and platform architectures for managing data and analytical workflows. Tired of deploying bad data?
[link] Adam Bellemare & Thomas Betts: The End of the Bronze Age: Rethinking the Medallion Architecture I’m always a bit uncomfortable with medallion architecture since it is a glorified term for the traditional ETL process. link] All rights reserved ProtoGrowth Inc, India.
The datawarehouse is the foundation of the modern data stack, so it caught our attention when we saw Convoy head of data Chad Sanderson declare, “ the datawarehouse is broken ” on LinkedIn. Treating data like an API. Immutable datawarehouses have challenges too.
Summary Cloud datawarehouses and the introduction of the ELT paradigm has led to the creation of multiple options for flexible data integration, with a roughly equal distribution of commercial and open source options. Materialize]([link] You shouldn't have to throw away the database to build with fast-changing data.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
They often don’t realize that infrastructure for BI must be scalable and shared with external partners who need to collaborate on projects. . How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP).
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
The Future of Data — Everyone wants a piece of the pie; no one wants to bake. Data Modeling, architecture Pattern, tools and the future — part 3 of Simon's guide. Here are first impressions , how it includes with Power BI and a few remarks. Writing design docs for data pipelines.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a legacy datawarehouse to Snowflake and some of the benefits they saw.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. What are the main use cases and platform architectures that you are focused on?
Monte Carlo monitors and alerts for data issues across your datawarehouses, data lakes, dbt models, Airflow jobs, and business intelligence tools, reducing time to detection and resolution from weeks to just minutes. Start trusting your data with Monte Carlo today! Start trusting your data with Monte Carlo today!
The idea is to create a unified layer that stores all the data needed to take decisions. Lyft, powering millions of real-time decisions with LyftLearn Serving — Architecture of the decentralized system Lyft use to deploy and serve ml models. The article is a good summary of the required blocks composing a modern data stack.
Summary Google pioneered an impressive number of the architectural underpinnings of the broader big data ecosystem. In this episode Lak Lakshmanan enumerates the variety of services that are available for building your various data processing and analytical systems. No more scripts, just SQL.
The terms “ DataWarehouse ” and “ Data Lake ” may have confused you, and you have some questions. On the other hand, a datawarehouse contains historical data that has been cleaned and arranged. . What is DataWarehouse? . DataWarehouse in DBMS: .
Summary The data mesh is a thesis that was presented to address the technical and organizational challenges that businesses face in managing their analytical workflows at scale. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
So, you’re planning a cloud datawarehouse migration. But be warned, a warehouse migration isn’t for the faint of heart. As you probably already know if you’re reading this, a datawarehouse migration is the process of moving data from one warehouse to another. A worthy quest to be sure.
Summary One of the most complex aspects of managing data for analytical workloads is moving it from a transactional database into the datawarehouse. What if you didn’t have to do that at all? If you think that sounds awesome (and it is) then join the free webinar with Metis Machine on October 11th at 2 PM ET (11 AM PT).
The talk starts with a great introduction of Snowflake architecture. In a nutshell the speakers share tips about warehouses sizing and design, performance optimisation with pruning, clustering and query design. Retro on data science by DJ Patil — DJ Patil has been US Chief Data Scientist. He does a great retro.
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. What is Real Time Data Warehousing?
Moreover, you can make significant business decisions by exploring the data you already have. The process of gathering, storing, mining, and analyzing data comes under business intelligence. Under BI, all the data a company generates gets stored and used to make significant business growth decisions and multiply the revenue.
In this episode he shares the goals of the Unstruk DataWarehouse, how it is architected to extract asset metadata and build a searchable knowledge graph from the information, and the myriad ways that the system can be used. Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
In order to make it easier for developers to build customer profiles in a way that respects their privacy Serge Huber helped to create the Apache Unomi framework as an open source customer data platform. Start trusting your data with Monte Carlo today! The data you’re looking for is already in your datawarehouse and BI tools.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
Summary When your data lives in multiple locations, belonging to at least as many applications, it is exceedingly difficult to ask complex questions of it. The default way to manage this situation is by crafting pipelines that will extract the data from source systems and load it into a data lake or datawarehouse.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs data lake vs data lakehouse: What’s the difference.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake.
Summary Data lakes have been gaining popularity alongside an increase in their sophistication and usability. Despite improvements in performance and dataarchitecture they still require significant knowledge and experience to deploy and manage. The data you’re looking for is already in your datawarehouse and BI tools.
Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads? Hightouch is the easiest way to sync data into the platforms that your business teams rely on. The data you’re looking for is already in your datawarehouse and BI tools.
How does it compare to open source platforms for BI? Given that you are connecting to the customer’s data store, how do you ensure sufficient security? data engineer vs sales management) What are the scaling factors for Looker, both in terms of volume of data for reporting from, and for user concurrency?
Ever wondered why Power BI developers are widely sought after by businesses all around the world? For any organization to grow, it requires business intelligence reports and data to offer insights to aid in decision-making. This data and reports are generated and developed by Power BI developers.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. RudderStack’s smart customer data pipeline is warehouse-first.
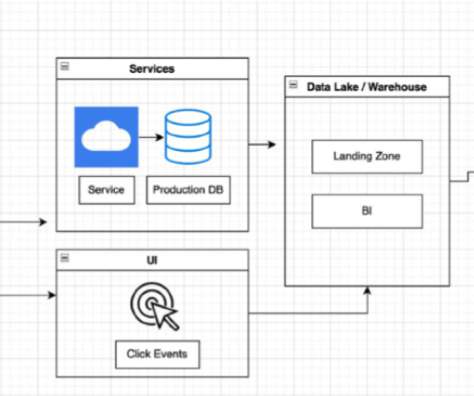
Plus, we will put together a design that minimizes costs compared to modern datawarehouses, such as Big Query or Snowflake. As data practitioners we want (and love) to build applications on top of our data as seamlessly as possible. The idea is to start from a Data Lake where our data are stored.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. What are the driving factors for building a real-time data platform?
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content