This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. The Medallion architecture is a design pattern that helps data teams organize data processing and storage into three distinct layers, often called Bronze, Silver, and Gold.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage.
Though basic and easy to use, traditional table storage formats struggle to keep up. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)?
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloudstorage (S3 for AWS, ADLS-gen2 for Azure).
And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data. What are the technical/architectural/UX challenges that have hindered the progression of lakehouses? Want to see Starburst in action? Want to see Starburst in action?
Apache Iceberg’s ecosystem of diverse adopters, contributors and commercial support continues to grow, establishing itself as the industry standard table format for an open data lakehouse architecture. Snowflake’s support for Iceberg Tables is now in public preview, helping customers build and integrate Snowflake into their lake architecture.
Whether you use Snowpipe Streaming as a standalone client or as part of your Kafka architecture, you can create scalable and reliable data pipelines with a fully managed underlying infrastructure with built-in observability.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time data ingestion and query serving. Every database built for real-time analytics has a fundamental limitation. Michael Carey.
Between continuous real-time collection of data, and its delivery to enterprise and cloud destinations, data has to move in a reliable and scalable way. There are architectural and technology decisions every step of the way – not just at design time, but also at run time.
Azure is among the top cloud service providers. Azure architecture includes all the ideas and elements needed to build a safe, dependable, and scalable cloud application. What Is Microsoft Azure CloudArchitecture? Users can view and access their files from anywhere with its cloudstorage capabilities.
CDP One is a new service from Cloudera that is the first data lakehouse SaaS offering with cloud compute, cloudstorage, machine learning (ML), streaming analytics, and enterprise grade security built-in. What if you could access all your data and execute all your analytics in one workflow, quickly with only a small IT team?
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
CDP Public Cloud is already available on Amazon Web Services and Microsoft Azure. With the addition of Google Cloud, we deliver on our vision of providing a hybrid and multi-cloudarchitecture to support our customer’s analytics needs regardless of deployment platform. .
Rockset introduces a new architecture that enables separate virtual instances to isolate streaming ingestion from queries and one application from another. Benefits of Compute-Compute Separation In this new architecture, virtual instances contain the compute and memory needed for streaming ingest and queries.
By separating the compute, the metadata, and data storage, CDW dynamically adapts to changing workloads and resource requirements, speeding up deployment while effectively managing costs – while preserving a shared access and governance model. Architecture overview. Separate storage. Get your data in place.
The architecture is designed to be resilient against new-age attacks against LLMs like prompt injection and prompt leaks. Architecture Let's start with the big picture and tackle how we adjusted our cloudarchitecture with additional internal and external interfaces to integrate LLM.
Modern data platforms deliver an elastic, flexible, and cost-effective environment for analytic applications by leveraging a hybrid, multi-cloudarchitecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. The high-level architecture shown below forms the backdrop for the exploration.
This blog will give you an in-depth knowledge of what is a data pipeline and also explore other aspects such as data pipeline architecture, data pipeline tools, use cases, and so much more. Features of a Data Pipeline Data Pipeline Architecture How to Build an End-to-End Data Pipeline from Scratch? What is a Big Data Pipeline?
Upcoming events include the O’Reilly AI conference, the Strata Data conference, the combined events of the Data Architecture Summit and Graphorum, and Data Council in Barcelona. What are the cases where it makes sense to use MinIO in place of a cloud-native object store such as S3 or Google CloudStorage?
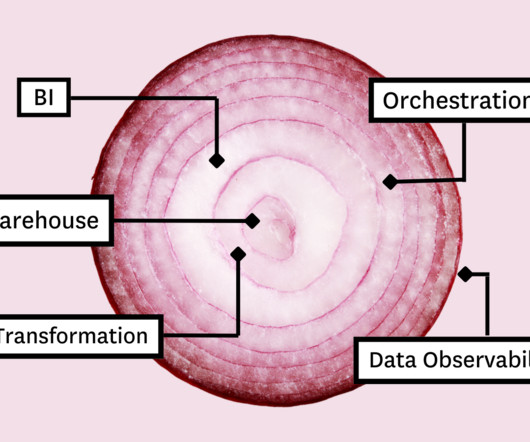
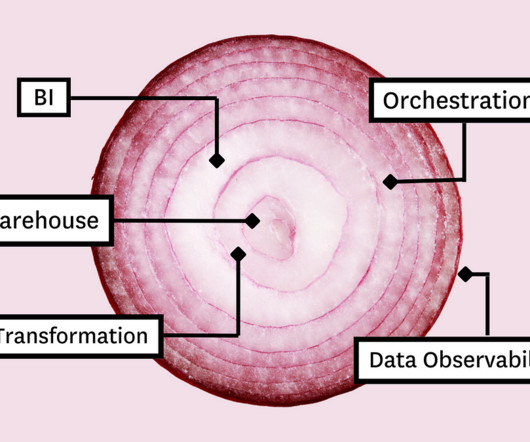
Those tools include: Cloudstorage and compute Data transformation Business intelligence Data observability And orchestration And we won’t mention ogres or bean dip again. Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up. Let’s dive into it.
A new capability called Ranger Authorization Service (RAZ) provides fine grained authorization on cloudstorage. We are excited to offer in Tech Preview this born-in-the-cloud table format that will help future proof data architectures at many of our public cloud customers. Modernizing pipelines.
There is no question that cloud computing is here to stay because its architecture is simple, stating its components and subcomponents in clear terms. It is ubiquitous today, offering many advantages in terms of flexibility, maintenance, sharing, and storage, among others. What Is Cloud Computing Architecture? .
Finally, cloud computing adds low cost and high resiliency to these services. The advantages provide the foundation for the modern data lakehouse architectural pattern. Cloudstorage is versioned as well, and should you inadvertently delete important data the SaaS CDP One ops team can quickly recover it for you.
Moreover, the data will need to leave the cloud env to go on our machine, which is not exactly secure and auditable. To make the cloud experience as smooth as possible we designed a data lake architecture where data are sitting in a simple cloudstorage (AWS S3) and a serverless infrastructure that embeds DuckDB works as a query engine.
In this environment, the emphasis shifts from minimizing storage space to optimizing query performance. In BigQuery, de-normalization emerges as a preferred strategy for several reasons: Query Performance : BigQuery’s distributed architecture excels at scanning large volumes of data in parallel.
YARN allows you to use various data processing engines for batch, interactive, and real-time stream processing of data stored in HDFS or cloudstorage like S3 and ADLS. You need to configure the backup repository in solr xml to point to your cloudstorage location (in this example your S3 bucket). Prerequisites.
Github: The architecture of today’s LLM applications LLM is slowly changing the application architecture landscape as it becomes integral to app development. Github writes an excellent blog to capture the current state of the LLM integration architecture. Visit rudderstack.com to learn more. Partitions, ever-present.
A new solution integrating cloud object storage, with Cloudera’s NiFi dataflows, a Kafka datahub, and a Hive virtual warehouse in the CDW service allows businesses to take the best advantage of this public cloud trend. The Cost-Effective Data Warehouse Architecture. This architecture has the following benefits .
A file and folder interface for Netflix Cloud Services Written by Vikram Krishnamurthy , Kishore Kasi , Abhishek Kapatkar , and Tejas Chopra In this post, we are introducing Netflix Drive, a Cloud drive for media assets and providing a high level overview of some of its features and interfaces.
We recently completed a project with IMAX, where we learned that they had developed a way to simplify and optimize the process of integrating Google CloudStorage (GCS) with Bazel. rules_gcs is a Bazel ruleset that facilitates the downloading of files from Google CloudStorage. What is rules_gcs ?
The certification process is designed to validate Cloudera products on a variety of Cloud, Storage & Compute Platforms. Validation includes: Overall architecture. Observance of the CDP interface classification system.
But to understand why Kafka is omnipresent we have to look at how it works — in other words, to get familiar with its concepts and architecture. Kafka architecture. Read our article on event-driven architecture and Pub/Sub to learn more about this powerful communication paradigm. Kafka cluster architecture. Scalability.
Maybe you need to scale up to a cloudstorage provider like Snowflake or AWS to keep up and make all this data accessible at the pace you need. You probably need to attend to data architecture to try and keep costs from skyrocketing, but what about data retention? This isn’t sustainable, though — not forever anyway.
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud Data Lake. Architecture. In order to copy or migrate data from CDH cluster to CDP Data Lake cluster, the on-prem CDH cluster should be able to access the CDP cloudstorage.
To provide accurate answers, developers can use a RAG-based architecture, where the LLM retrieves relevant internal knowledge from documents, wikis or FAQs before generating a response. Since a pre-trained LLM alone will lack deep expertise in your company’s products, the answers generated are likely to be incorrect and of no value.
Lot of cloud-based data warehouses are available in the market today, out of which let us focus on Snowflake. Built on new SQL database engine, it provides a unique architecture designed for the cloud. Snowflake architecture provides flexibility with big data. Here’s a detail on the architecture of Snowflake.
To get a better understanding of a data architect’s role, let’s clear up what data architecture is. Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level data architecture blueprint for Azure BI programs.
Those tools include: Cloudstorage and compute Data transformation Business intelligence Data observability And orchestration And we won’t mention ogres or bean dip again. Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up. Let’s dive into it.
The serving and monitoring infrastructure need to fit into your overall enterprise architecture and tool stack. Say you wanted to build one integration pipeline from MQTT to Kafka with KSQL for data preprocessing, and use Kafka Connect for data ingestion into HDFS, AWS S3 or Google CloudStorage, where you do the model training.
However, the hybrid cloud is not going away anytime soon. In fact, the hybrid cloud will likely become even more common as businesses move more of their workloads to the cloud. So what will be the future of cloudstorage and security? With guidance from industry experts, be ready for a future in the domain.
Data storage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloudstorage systems. In Snowflake, there are three different storage layers available, Database, Stage, and CloudStorage.
Implementing a Modern Data Architecture. With this expanded scope, the organization has introduced its CloudStorage Connector, which has become a fully integrated component for data access and processing of Hadoop and Spark workloads.
File systems can store small datasets, while computer clusters or cloudstorage keeps larger datasets. The designer must decide and understand the data storage, and inter-relation of data elements. Repository GitHub: It is a place to find detailed codes, architecture design.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content