This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datastorage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Now you dont have to choose. This is why Snowflake is fully embracing this open table format.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. To start, can you share your definition of what constitutes a "Data Lakehouse"?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Adopting an Open Table Format architecture is becoming indispensable for modern data systems.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise DataCloud. The public cloud (CDP-PC) editions default to using cloudstorage (S3 for AWS, ADLS-gen2 for Azure).
It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience. In contrast to conventional warehouses, it keeps computation and storage apart, allowing for cost-effectiveness and dynamic scaling.
Apache Iceberg’s ecosystem of diverse adopters, contributors and commercial support continues to grow, establishing itself as the industry standard table format for an open data lakehouse architecture. Are you using Snowflake on AWS and already using Glue Data Catalog for your datalake?
Datalakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? . Athena on AWS. .
By separating the compute, the metadata, and datastorage, CDW dynamically adapts to changing workloads and resource requirements, speeding up deployment while effectively managing costs – while preserving a shared access and governance model. Architecture overview. Separate storage. Separate compute.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. What are the mechanisms that you use for categorizing data assets?
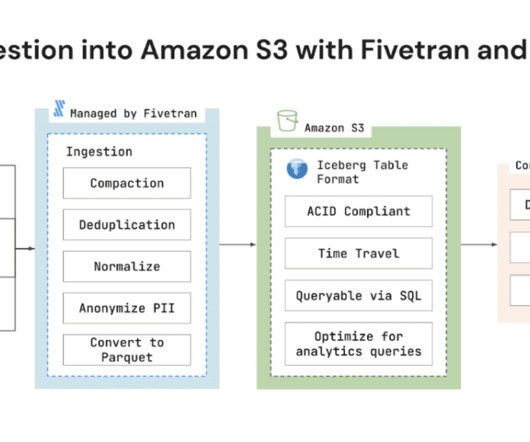
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format.
An open-source implementation of a DataLake with DuckDB and AWS Lambdas A duck in the cloud. Photo by László Glatz on Unsplash In this post we will show how to build a simple end-to-end application in the cloud on a serverless infrastructure. The idea is to start from a DataLake where our data are stored.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
With the addition of Google Cloud, we deliver on our vision of providing a hybrid and multi-cloudarchitecture to support our customer’s analytics needs regardless of deployment platform. . You could then use an existing pipeline to run analytics on the prepared data in BigQuery. .
Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly.
Modern data platforms deliver an elastic, flexible, and cost-effective environment for analytic applications by leveraging a hybrid, multi-cloudarchitecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. Luke: What is a modern data platform?
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public CloudDataLake. CDP DataLake cluster versions – CM 7.4.0, Architecture. Pre-Check: DataLake Cluster. Understanding Ranger Policies in DataLake Cluster.
Summary Object storage is quickly becoming the unifying layer for data intensive applications and analytics. Modern, cloud oriented data warehouses and datalakes both rely on the durability and ease of use that it provides. How do you approach project governance and sustainability?
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
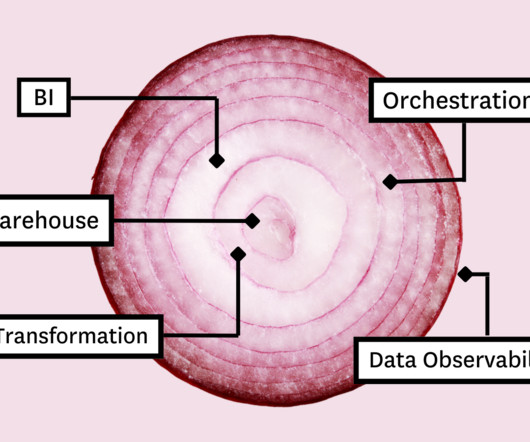
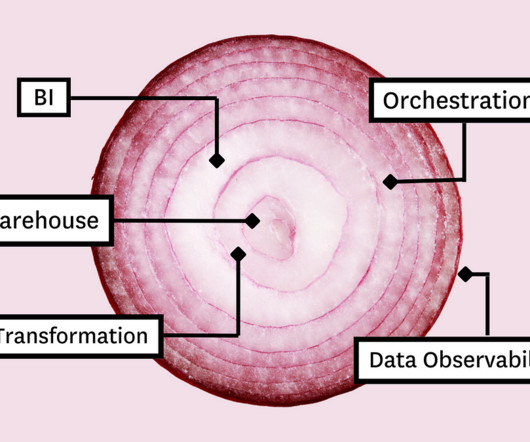
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
Even the best of us sometimes demonize the parts of our organization whose primary goals are in the privacy and security area and conflict with our wishes to splash around in the datalake. In reality, data scientists are not always the heroes and IT and security teams are not the villains. You’re using the data, of course!
The team was able to achieve this by leveraging cloud as well as open source tools in a modular set up, taking advantage of relatively cheap cloudstorage, a versatile programming language in Python and Spark’s powerful processing engine.
The team was able to achieve this by leveraging cloud as well as open source tools in a modular set up, taking advantage of relatively cheap cloudstorage, a versatile programming language in Python and Spark’s powerful processing engine.
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data. The relatively new storagearchitecture powering Databricks is called a data lakehouse. Databricks lakehouse platform architecture.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including datalakes, databases, streaming platforms, and cloudstorage. This flexibility allows organizations to ingest data from virtually anywhere.
Unstructured data , on the other hand, is unpredictable and has no fixed schema, making it more challenging to analyze. Without a fixed schema, the data can vary in structure and organization. There are several widely used unstructured datastorage solutions such as datalakes (e.g., Build dataarchitecture.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts. Let’s take a closer look.
ADF leverages compute services like Azure HDInsight, Spark, Azure DataLake Analytics, or Machine Learning to process and analyze the data according to defined requirements. Publish: Transformed data is then published either back to on-premises sources like SQL Server or kept in cloudstorage.
Become more agile with business intelligence and data analytics. Clouds (source: Pexels ). Organizations find they have much more agility with analytics in the cloud and can operate at a lower cost point than has been possible with legacy on-premises solutions. Architecture patterns for the cloud.
Online Book Store System using Google Cloud Platform 15 Sample GCP Real Time Projects for Practice in 2023 With the need to learn Cloud Platform as part of any analytical job role, it is essential to understand the basics and then gain some hands-on experience leveraging the cloud platforms.
With this release , Rockset users have the capability to continuously aggregate and transform data at the time of ingest, using SQL, from any data source (data streams, databases and datalakes). This is a first in the industry and frees users from managing slow, expensive ETL pipelines for their streaming data.
Data-in-motion is predominantly about streaming data so enterprises typically have two different ways or binary ways of looking at data. This can extend to streaming analytics capabilities into any cloud environment.
A complete end-to-end stream processing pipeline is shown here using an architectural diagram. The pipeline in this reference design collects data from two different sources, then conducts a join operation on related records from each stream, then enriches the output, and finally produces an average.
Organizations that depend on data for their success and survival need robust, scalable dataarchitecture, typically employing a data warehouse for analytics needs. Snowflake is often their cloud-native data warehouse of choice. Snowflake provides a couple of ways to load data.
Tired of relentlessly searching for the most effective and powerful data warehousing solutions on the internet? This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. Search no more! Did you know ?
The growing complexity drove a proliferation of software and data innovations, which in turn demanded highly trained data engineers to build code-based data pipelines that ensured data quality, consistency, and stability. Because data pipelines were coded from scratch, they started breaking down under the complexity.
Serverless computing (often just called "serverless") is a model where a cloud provider, like AWS, abstracts away the concept of servers from the user. Serverless architecture entails the dynamic allocation of resources to carry out various execution tasks. What Is Serverless? Serverless is not limited to functions.
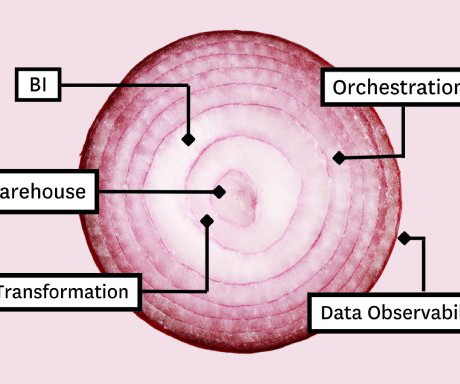
Those tools include: Table of Contents Cloudstorage and compute Data transformation Business Intelligence (BI) Data observability Data orchestration The most important part? Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up.
Along with using Postgres (or KSQL as shown above) for analytics, the data can be streamed using Kafka Connect into S3, from where it can serve multiple roles. In S3, it can be seen as the “cold storage”, or the datalake, against which as-yet-unknown applications and processes may be run.
It is a built-in Massively parallel processing (MPP) datalake house to handle all your infrastructure observability and security needs. It is a free standalone application that makes working with Azure Storagedata on Windows, macOS, and Linux effortlessly.
If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of best data engineering project examples below. With the trending advance of IoT in every facet of life, technology has enabled us to handle a large amount of data ingested with high velocity.
“Sometimes there’s so much data that old batch processing (late at night once a day or once a week) just doesn’t have time to move all data and hence the only way to do it is trickle feed data via CDC,” says Dmitriy Rudakov, Director of Solution Architecture at Striim.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content