This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. It provides real multi-cloud flexibility in its operations on AWS , Azure, and Google Cloud. Its multi-cluster shared dataarchitecture is one of its primary features.
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
It also supports various sources, including cloudstorage, on-prem databases, and third-party platforms, making it highly versatile for hybrid ecosystems. However, it leans more toward transforming and presenting cleaned data rather than processing raw datasets.
BigQuery separates storage and compute with Google’s Jupiter network in-between to utilize 1 Petabit/sec of total bisection bandwidth. The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. CDP Data Lake cluster versions – CM 7.4.0,
A database is a structureddata collection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloudstorage keeps larger datasets. According to a database model, the organization of data is known as database design.
Lot of cloud-based data warehouses are available in the market today, out of which let us focus on Snowflake. Snowflake is an analytical data warehouse that is provided as Software-as-a-Service (SaaS). Built on new SQL database engine, it provides a unique architecture designed for the cloud.
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. Gen 2 Azure Data Lake Storage . Cloudstorage provided by Google . Data lakes can also be organized and queried using other technologies, such as .
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. AWS is one of the most popular data lake vendors.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including data lakes, databases, streaming platforms, and cloudstorage. This flexibility allows organizations to ingest data from virtually anywhere.
Table of Contents Data Lake vs Data Warehouse - The Differences Data Lake vs Data Warehouse - The Introduction What is a Data warehouse? Data Warehouse Architecture What is a Data lake? Data is generally not loaded into a data warehouse unless a use case has been defined for the data.
It combines the best elements of a data warehouse, a centralized repository for structureddata, and a data lake used to host large amounts of raw data. The relatively new storagearchitecture powering Databricks is called a data lakehouse. Databricks lakehouse platform architecture.
Tired of relentlessly searching for the most effective and powerful data warehousing solutions on the internet? This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. Search no more! Did you know ?
At the same time, 81% of IT leaders say their C-suite has mandated no additional spending or a reduction of cloud costs. Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. But, the options for datastorage are evolving quickly. Or maybe both.)
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
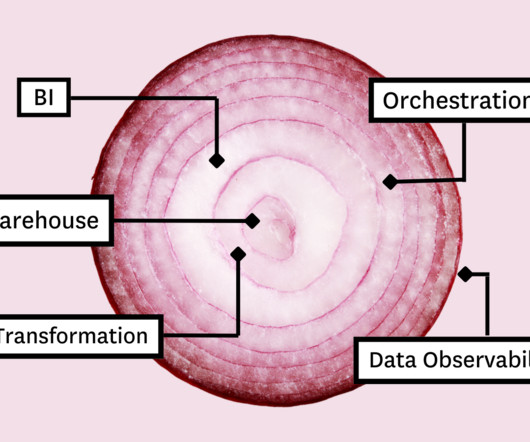
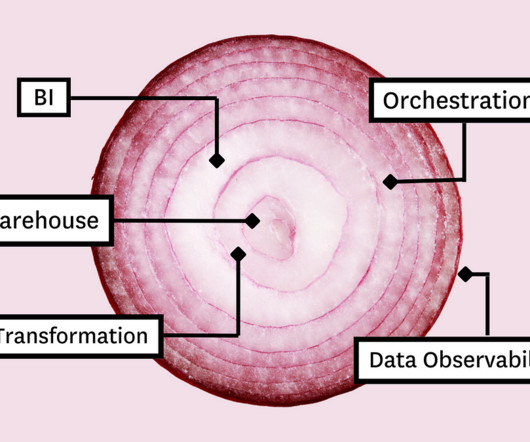
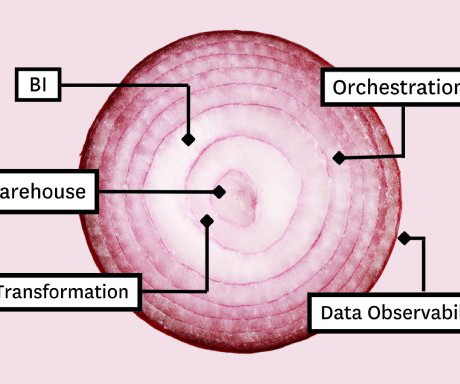
Those tools include: Table of Contents Cloudstorage and compute Data transformation Business Intelligence (BI) Data observability Data orchestration The most important part? Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up.
NoSQL Databases NoSQL databases are non-relational databases (that do not store data in rows or columns) more effective than conventional relational databases (databases that store information in a tabular format) in handling unstructured and semi-structureddata. Examples include Amazon DynamoDB and Google Cloud Datastore.
If you are a newbie in data engineering and are interested in exploring real-world data engineering projects, check out the list of best data engineering project examples below. With the trending advance of IoT in every facet of life, technology has enabled us to handle a large amount of data ingested with high velocity.
“Sometimes there’s so much data that old batch processing (late at night once a day or once a week) just doesn’t have time to move all data and hence the only way to do it is trickle feed data via CDC,” says Dmitriy Rudakov, Director of Solution Architecture at Striim.
It provides a flexible data model that can handle different types of data, including unstructured and semi-structureddata. Key features: Flexible data modeling High scalability Support for real-time analytics 4. Key features: Instant elasticity Support for semi-structureddata Built-in data security 5.
An Azure Data Engineer is a highly qualified expert who is in charge of integrating, transforming, and merging data from various structured and unstructured sources into a structure that can be used to build analytics solutions.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
With writing and querying of data, there is always an inherent tradeoff between high write rates and the visibility of data in queries, and this is precisely what RockBench measures. Semi-structureddata. Most of real-life decision-making data is in semi-structured form, e.g. JSON, XML or CSV.
It helps in storing the data in the CPU. DataStorage: The place where the information is stated somewhere safe without directly being processed. Storage solutions like solid-state drives and cloudstorage databases are included in this drive. This is the place where software applications are primarily run.
An Azure Data Engineer is a highly qualified expert responsible for integrating, transforming, and merging data from various structured and unstructured sources into a structure used to construct analytics solutions. Data infrastructure, data warehousing, data mining, data modeling, etc.,
They must load the raw data into a data warehouse for this analysis. There are numerous ways to import data into a data warehouse using SQL. For instance, data engineers can easily transfer the data onto a cloudstorage system and load the raw data into their data warehouse using the COPY INTO command.
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for raw data; a tool for large-scale data integration ; and. a suitable technology to implement data lake architecture.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Big Data Analytics Projects for Students on Chicago Crime Data Analysis with Source Code 11.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content