This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Unstructureddata takes many forms in an organization. From a data engineering perspective that often means things like JSON files, audio or video recordings, images, etc. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Adopting an Open Table Format architecture is becoming indispensable for modern data systems.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructureddata (i.e. data best served through Apache Solr). What does DDE entail? Prerequisites.
Modern data platforms deliver an elastic, flexible, and cost-effective environment for analytic applications by leveraging a hybrid, multi-cloudarchitecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. Luke: What is a modern data platform?
The certification process is designed to validate Cloudera products on a variety of Cloud, Storage & Compute Platforms. Validation includes: Overall architecture. Relevance-based text search over unstructureddata (text, pdf,jpg, …). Observance of the CDP interface classification system.
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. However, this won’t simply be where you store your data—it’s also the power to activate it.
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. As data is expanding exponentially, organizations struggle to harness digital information's power for different business use cases. What is a Big Data Pipeline?
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structured data and files/unstructureddata to the CDP cloud of their choice easily. CDP Data Lake cluster versions – CM 7.4.0,
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. However, this won’t simply be where you store your data — it’s also the power to activate it.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. The data lakes store data from a wide variety of sources, including IoT devices, real-time social media streams, user data, and web application transactions.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. AWS is one of the most popular data lake vendors.
Financial services firms can leverage the near-infinite capacity of the cloud while leveraging on-premises resources to meet demanding performance and compliance requirements. It integrates data from databases, cloud or RESTful APIs, and real-time, streaming feeds, as well as unstructureddata from document databases and other sources.
At the same time, 81% of IT leaders say their C-suite has mandated no additional spending or a reduction of cloud costs. Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. But, the options for datastorage are evolving quickly. Or maybe both.)
A complete end-to-end stream processing pipeline is shown here using an architectural diagram. The pipeline in this reference design collects data from two different sources, then conducts a join operation on related records from each stream, then enriches the output, and finally produces an average.
With data democratization, the availability of data and associated analysis tools extends far beyond the limited group of experts who have a data science background. Organizations are evaluating modern data management architectures that will support wider data democratization. Read Data democracy: Why now?
Tired of relentlessly searching for the most effective and powerful data warehousing solutions on the internet? This blog is your comprehensive guide to Google BigQuery, its architecture, and a beginner-friendly tutorial on how to use Google BigQuery for your data warehousing activities. Search no more! Did you know ?
Thankfully, cloud-based infrastructure is now an established solution which can help do this in a cost-effective way. As a simple solution, files can be stored on cloudstorage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure. But as it turns out, we can’t use it.
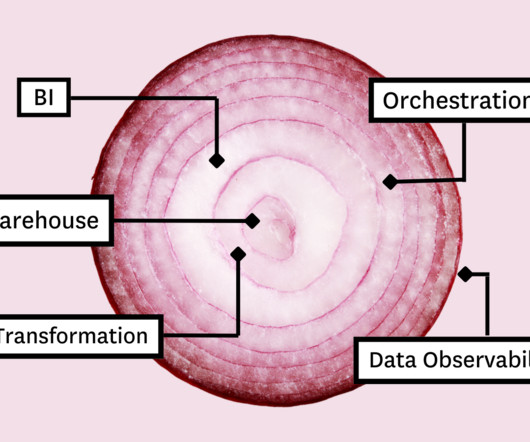
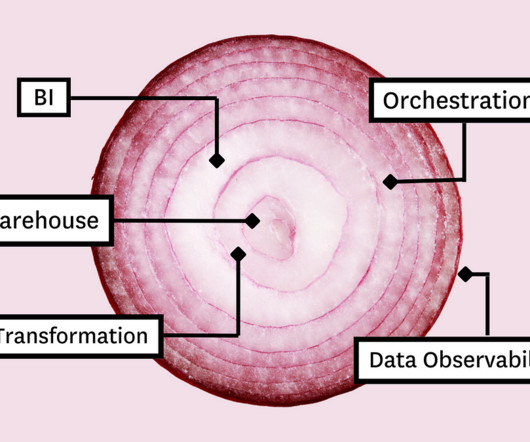
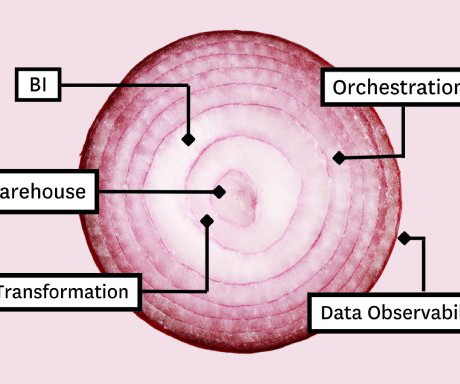
Those tools include: Table of Contents Cloudstorage and compute Data transformation Business Intelligence (BI) Data observability Data orchestration The most important part? Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up.
It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data. The relatively new storagearchitecture powering Databricks is called a data lakehouse. Databricks lakehouse platform architecture.
Automation Automation is an essential factor in data management, as it helps save both time and money while increasing efficiency and reducing errors. Meltano enables the automation of data delivery from various sources at the same time. Testing Data Quality Untested and undocumented data can result in unstable data and pipeline debt.
Organizations can harness the power of the cloud, easily scaling resources up or down to meet their evolving data processing demands. Supports Structured and UnstructuredData: One of Azure Synapse's standout features is its versatility in handling a wide array of data types.
NoSQL cloud databases offer non-relational, schema-less, and horizontally scalable databases. Examples include Amazon DynamoDB and Google Cloud Datastore. Cloud databases that are object-oriented, like Amazon S3 and Google CloudStorage.
An Azure Data Engineer is a highly qualified expert responsible for integrating, transforming, and merging data from various structured and unstructured sources into a structure used to construct analytics solutions. Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments.
An Azure Data Engineer is a highly qualified expert who is in charge of integrating, transforming, and merging data from various structured and unstructured sources into a structure that can be used to build analytics solutions.
Thus, as a learner, your goal should be to work on projects that help you explore structured and unstructureddata in different formats. Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis.
“Sometimes there’s so much data that old batch processing (late at night once a day or once a week) just doesn’t have time to move all data and hence the only way to do it is trickle feed data via CDC,” says Dmitriy Rudakov, Director of Solution Architecture at Striim.
Table of Contents Data Lake vs Data Warehouse - The Differences Data Lake vs Data Warehouse - The Introduction What is a Data warehouse? Data Warehouse Architecture What is a Data lake? Data is generally not loaded into a data warehouse unless a use case has been defined for the data.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
What is Cloud Computing? Cloud Computing is the grouping of networks, hardware, services, and storage that delivers/sells computing over the internet. Building datastorage and computing architecture locally were getting more expensive during the advent of Big Data technologies. What is cloud-native?
Data-first companies have embraced data platforms as an effective way to aggregate, operationalize, and democratize data at scale across the organization. Regardless of which side you take, you quite literally cannot build a modern data platform without investing in cloudstorage and compute.
Many business owners and professionals are interested in harnessing the power locked in Big Data using Hadoop often pursue Big Data and Hadoop Training. What is Big Data? Big data is often denoted as three V’s: Volume, Variety and Velocity. Pros: Handles huge data volume very fast without any single point of failure.
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for raw data; a tool for large-scale data integration ; and. a suitable technology to implement data lake architecture.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Big Data Analytics Projects for Students on Chicago Crime Data Analysis with Source Code 11.
These trends mark a decisive move towards hybrid and energy-efficient computing architectures, bridging the gap between performance, cost, and privacy in AI applications. Inspired by the human brain, Neuromorphic chips promise unparalleled energy efficiency and the ability to process unstructureddata locally on devices.
Following that, we will examine the Microsoft Fabric Data Engineer Associate Microsoft Fabric Data Engineer Associate About the Certification This professional credential verifies your proficiency in implementing data engineering solutions using Microsoft’s unified analytics platform.
In extract-transform-load (ETL), data is obtained from multiple sources, transformed, and stored in a single data warehouse, with access to data analysts , data scientists , and business analysts for data visualization and statistical analysis model building, forecasting, etc.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content