This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. To start, can you share your definition of what constitutes a "Data Lakehouse"?
In this episode Tobias Macey shares his thoughts on the challenges that he is facing as he prepares to build the next set of architectural layers for his data platform to enable a larger audience to start accessing the data being managed by his team. Datalakes are notoriously complex. With Materialize, you can!
Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. Datalakes are notoriously complex. Materialize]([link] You shouldn't have to throw away the database to build with fast-changing data.
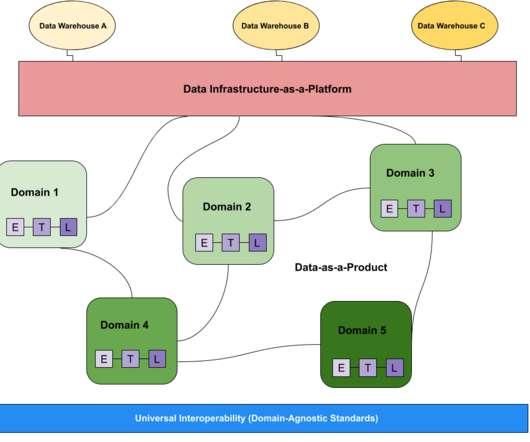
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ? We are Data Teams versus we have to patch the server with the latest version and do the tests.
Summary Data lakehouse architectures have been gaining significant adoption. To accelerate adoption in the enterprise Microsoft has created the Fabric platform, based on their OneLake architecture. Datalakes in various forms have been gaining significant popularity as a unified interface to an organization's analytics.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Data integration and Democratization fabric. Introduction to the Data Mesh Architecture and its Required Capabilities.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's dataarchitecture?
Datalakes are notoriously complex. How much of the complexity is due to the nature of streaming data vs. the architectural realities of Flink? How has the lack of visibility into the flow of data in Flink impacted the ways that teams think about where/when/how to apply it? Datalakes are notoriously complex.
In an effort to better understand where datagovernance is heading, we spoke with top executives from IT, healthcare, and finance to hear their thoughts on the biggest trends, key challenges, and what insights they would recommend. Get the Trendbook What is the Impact of DataGovernance on GenAI?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. And Starburst does all of this on an open architecture with first-class support for Apache Iceberg, Delta Lake and Hudi, so you always maintain ownership of your data.
Summary Databases and analytics architectures have gone through several generational shifts. A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. How has that changed the architectural approach to CDPs?
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
And if data security tops IT concerns, datagovernance should be their second priority. Not only is it critical to protect data, but datagovernance is also the foundation for data-driven businesses and maximizing value from data analytics. But it’s still not easy. But it’s still not easy.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Summary Data lakehouse architectures are gaining popularity due to the flexibility and cost effectiveness that they offer. The link that bridges the gap between datalake and warehouse capabilities is the catalog. Datalakes are notoriously complex. Can you describe the architecture of Nessie?
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
In this episode Andrew Jefferson explains the complexities of building a robust system for data sharing, the techno-social considerations, and how the Bobsled platform that he is building aims to simplify the process.
In this episode Andrey Korchack, CTO of fintech startup Monite, discusses the complexities of designing and implementing a data platform in that sector. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Previously, there were three types of data structures in telco: .
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. Datalakes are notoriously complex. Materialize]([link] You shouldn't have to throw away the database to build with fast-changing data.
Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. Datalakes are notoriously complex. Materialize]([link] You shouldn't have to throw away the database to build with fast-changing data.
If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Datalakes are notoriously complex. With Materialize, you can! Sponsored By: Starburst : 

















































Let's personalize your content