This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
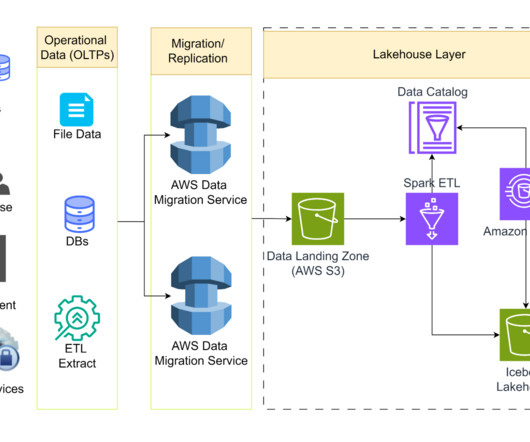
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer?
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
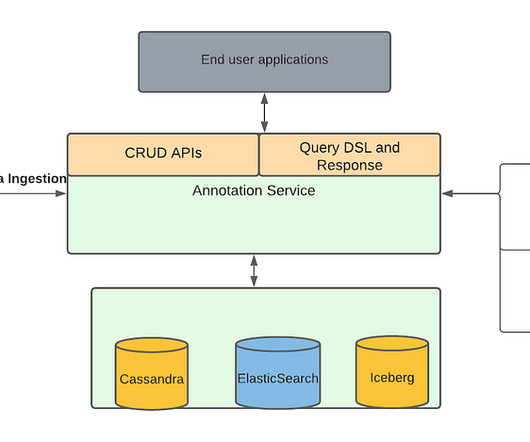
Marken Architecture Marken’s architecture diagram is as follows. Marken Architecture Our goal was to help teams at Netflix to create data pipelines without thinking about how that data is available to the readers or the client teams. We refer the reader to our previous blog article for details.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
In a recent session with the Delta Lake project I was able to share the work led Kuntal Basu and a number of other people to dramatically improve the efficiency and reliability of our online dataingestion pipeline. as they take you behind the scenes of Scribds dataingestion setup.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
A dataingestionarchitecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow.
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
For more than a decade, Cloudera has been an ardent supporter and committee member of Apache NiFi, long recognizing its power and versatility for dataingestion, transformation, and delivery. Accelerating GenAI with Powerful New Capabilities Cloudera DataFlow 2.9
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. This solution is both scalable and reliable, as we have been able to effortlessly ingest upwards of 1GB/s throughput.” How does Snowpipe Streaming work?
Given the complexity of ingesting OT systems data in near real time, Snowflake is establishing a standardized reference architecture. Working with our partners, this standardized reference architecture provides edge connectivity hardware supporting edge analytics, in addition to being a gateway device.
In this episode SVP of engineering Shireesh Thota describes the impact on your overall system architecture that Singlestore can have and the benefits of using a cloud-native database engine for your next application. That’s where our friends at Ascend.io What are the core sets of workloads that SingleStore is aimed at addressing?
Welcome to the third blog post in our series highlighting Snowflake’s dataingestion capabilities, covering the latest on Snowpipe Streaming (currently in public preview) and how streaming ingestion can accelerate data engineering on Snowflake.
This article describes a large-scale data warehousing use case to provide reference for data engineers who are looking for log analytic solutions. It introduces the log processing architecture and real-case practice in dataingestion, storage, and queries.
While the Iceberg itself simplifies some aspects of data management, the surrounding ecosystem introduces new challenges: Small File Problem (Revisited): Like Hadoop, Iceberg can suffer from small file problems. Dataingestion tools often create numerous small files, which can degrade performance during query execution.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
In scenarios involving analytics on massive data streams, we’re often asked the maximum throughput and lowest data latency Rockset can achieve and how it stacks up to other databases. For this benchmark, we evaluated Rockset and Elasticsearch ingestion performance on throughput and data latency. How did we do it?:
Real-time data access is critical in e-commerce, ensuring accurate pricing and availability. At Zalando, our event-driven architecture for Price and Stock updates became a bottleneck, introducing delays and scaling challenges. This architecture made Offer processing slow, expensive, and fragile. Whats Next?
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
s architecture, key capabilities (discoverability, access control, resource management, monitoring), client interfaces (UI, APIs, CLIs), benefits (agility, ownership, performance, security), and future considerations like self-serve onboarding, infrastructure as code, and an AI assistant. and then to Nuage 3.0,
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Let’s walk through how to transform your scrappy data setup into a robust pipeline that’s ready to grow with your business. At the front end, you’ve got your dataingestion layer —the workhorse that pulls in data from everywhere it lives. Once you’ve got the data flowing in, you need somewhere to put it.
Read Time: 5 Minute, 16 Second As we know Snowflake has introduced latest badge “Data Cloud Deployment Framework” which helps to understand knowledge in designing, deploying, and managing the Snowflake landscape. Respective Cloud would consume/Store the data in bucket or containers. Snowpipe to automate the ingestion process.
Data cloud integration: This comprehensive solution begins with the Snowflake Data Cloud as a persistent data layer, which makes data more accessible for organizations to get started with the platform. Dataingestion: Hakkoda leads the entire dataingestion process.
Every data-centric organization uses a data lake, warehouse, or both dataarchitectures to meet its data needs. Data Lakes bring flexibility and accessibility, whereas warehouses bring structure and performance to the dataarchitecture.
DataOps Architecture: 5 Key Components and How to Get Started Ryan Yackel August 30, 2023 What Is DataOps Architecture? DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. As a result, they can be slow, inefficient, and prone to errors.
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity.
The company quickly realized maintaining 10 years’ worth of production data while enabling real-time dataingestion led to an unscalable situation that would have necessitated a data lake. Data scientists also benefited from a scalable environment to build machine learning models without fear of system crashes.
Snowflake provides a strong data foundation anchored on unified data, optimal TCO and universal governance. The Snowflake platform eliminates silos to enable any architectural pattern, while supporting all data types and workloads. Getting dataingested now only takes a few clicks, and the data is encrypted.
The Ascend Data Automation Cloud provides a unified platform for dataingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Systems must be capable of handling high-velocity data without bottlenecks. Addressing these challenges demands an end-to-end approach that integrates dataingestion, streaming analytics, AI governance, and security in a cohesive pipeline. As you can see, theres a lot to consider in adopting real-time AI.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. Ingestion layer 2.
The flow of data often involves complex ETL tooling as well as self-managing integrations to ensure that high volume writes, including updates and deletes, do not rack up CPU or impact performance of the end application. That’s because Elasticsearch can only write data to one index.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. Ingestion layer 2.
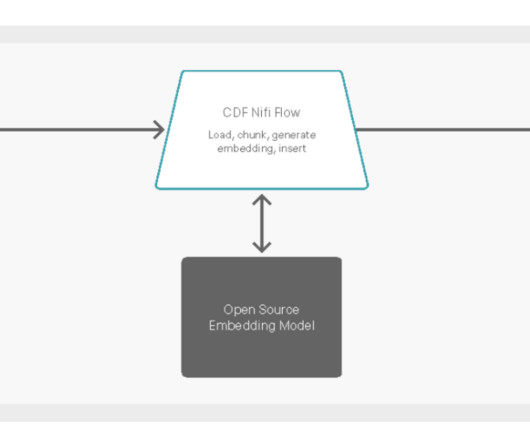
And so we are thrilled to introduce our latest applied ML prototype (AMP) — a large language model (LLM) chatbot customized with website data using Meta’s Llama2 LLM and Pinecone’s vector database. High-level overview of real-time dataingest with Cloudera DataFlow to Pinecone vector database.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Benjamin Kennedy, Cloud Solutions Architect at Striim, emphasizes the outcome-driven nature of data pipelines.
And while operations in the cyber-domain are more likely to make the evening news, there are a vast array of critical use cases that support the military’s need for a dataarchitecture that collects, processes, and delivers any type of data, anywhere. . Universal Data Distribution Solves DoD Data Transport Challenges.
This dramatic increase in vendors hasn’t led to the expected data revolution. Rather, it has created needlessly complex dataarchitectures that are inflexible, resist change, and stifle innovation. It’s a final, frustrating hurdle in the race to become truly data-driven.
As companies become more data-driven, the scope and complexity of data pipelines inevitably expand. Without a well-planned architecture, these pipelines can quickly become unmanageable, often reaching a point where efficiency and transparency take a backseat, leading to operational chaos. What Is Data Pipeline Architecture?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content