This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
A dataingestionarchitecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. DataStorage : Store validated data in a structured format, facilitating easy access for analysis.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
DataOps Architecture: 5 Key Components and How to Get Started Ryan Yackel August 30, 2023 What Is DataOps Architecture? DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. As a result, they can be slow, inefficient, and prone to errors.
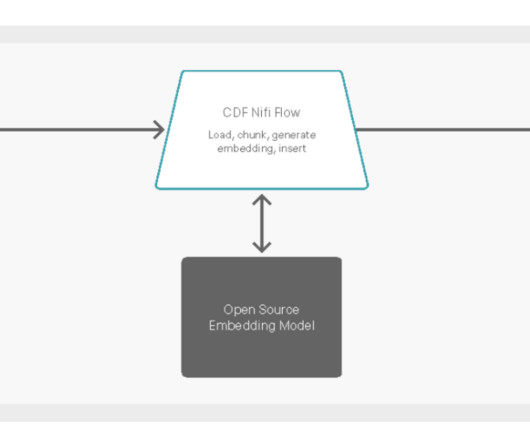
And so we are thrilled to introduce our latest applied ML prototype (AMP) — a large language model (LLM) chatbot customized with website data using Meta’s Llama2 LLM and Pinecone’s vector database. High-level overview of real-time dataingest with Cloudera DataFlow to Pinecone vector database.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Benjamin Kennedy, Cloud Solutions Architect at Striim, emphasizes the outcome-driven nature of data pipelines.
Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud datastorage capacity.
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
Druid at Lyft Apache Druid is an in-memory, columnar, distributed, open-source data store designed for sub-second queries on real-time and historical data. Druid enables low latency (real-time) dataingestion, flexible data exploration and fast data aggregation resulting in sub-second query latencies.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. Ingestion layer 2.
Future connected vehicles will rely upon a complete data lifecycle approach to implement enterprise-level advanced analytics and machine learning enabling these advanced use cases that will ultimately lead to fully autonomous drive.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? What is data pipeline architecture? Why is data pipeline architecture important?
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. Ingestion layer 2.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a data lake?
For example, the datastorage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. A conceptual architecture illustrating this is shown in Figure 3.
formats — This is a huge part of data engineering. Picking the right format for your datastorage. The main difference between both is the fact that your computation resides in your warehouse with SQL rather than outside with a programming language loading data in memory. workflows (Airflow, Prefect, Dagster, etc.)
Technical Overview The project architecture is depicted as follows: Google Calendar -> Fivetran -> Snowflake -> dbt -> Snowflake Dashboard , with GitHub Actions orchestrating the deployment. Storage — Snowflake Snowflake, a cloud-based data warehouse tailored for analytical needs, will serve as our datastorage solution.
As data volumes grow and analytical needs evolve, organizations can seamlessly scale their infrastructure horizontally to accommodate increased dataingestion, processing, and storage demands. Support for Modern Analytics Workloads : With support for both SQL-based querying and advanced analytics frameworks (e.g.,
Customers, especially those in regulated industries with strict data protection and compliance requirements, routinely ask a straightforward question of our technical strategy experts: what should I do if a catastrophe hits my business and threatens to take out my data platform? The CDP Disaster Recovery Reference Architecture.
They’re betting their business on it and that the data pipelines that run it will continue to work. Context is crucial (and often lacking) A major cause of data quality issues and pipeline failures are transformations within those pipelines. Most dataarchitecture today is opaque—you can’t tell what’s happening inside.
Comparison of Snowflake Copilot and Cortex Analyst Cortex Search: Deliver efficient and accurate enterprise-grade document search and chatbots Cortex Search is a fully managed search solution that offers a rich set of capabilities to index and query unstructured data and documents. Our state-of-the-art hybrid search enables better results.
Lot of cloud-based data warehouses are available in the market today, out of which let us focus on Snowflake. Snowflake is an analytical data warehouse that is provided as Software-as-a-Service (SaaS). Built on new SQL database engine, it provides a unique architecture designed for the cloud.
Can you achieve similar outcomes with your on-premises data platform? Application modernization initiatives have led to cloud native architectures gaining popularity on premises, making it a sensible choice to extend to your data platform. This is exactly where cloud native architectures excel, and why they are so popular.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
This is particularly valuable in today's data landscape, where information comes in various shapes and sizes. Effective DataStorage: Azure Synapse offers robust datastorage solutions that cater to the needs of modern data-driven organizations. Key Features of Databricks 1.
It is meant for you to assess if you have thought through processes such as continuous dataingestion, enterprise data integration and data governance. Data infrastructure readiness – IoT architectures can be insanely complex and sophisticated. Will you be needing local edge storage?
Let us now look into the differences between AI and Data Science: Data Science vs Artificial Intelligence [Comparison Table] SI Parameters Data Science Artificial Intelligence 1 Basics Involves processes such as dataingestion, analysis, visualization, and communication of insights derived.
While this “data tsunami” may pose a new set of challenges, it also opens up opportunities for a wide variety of high value business intelligence (BI) and other analytics use cases that most companies are eager to deploy. . Traditional data warehouse vendors may have maturity in datastorage, modeling, and high-performance analysis.
They work with various Azure services and tools to build scalable, efficient, and reliable data pipelines, datastorage solutions, and data processing systems. Azure Data Engineer vs Azure Devops: Project Involvement Data Engineers are involved in projects related to dataingestion, transformation, storage, and analytics.
Tools and platforms for unstructured data management Unstructured data collection Unstructured data collection presents unique challenges due to the information’s sheer volume, variety, and complexity. The process requires extracting data from diverse sources, typically via APIs. Data durability and availability.
link] Meta: Tulip - Schematizing Meta’s data platform Numerous heterogeneous services make up a data platform, such as warehouse datastorage and various real-time systems. The schematization of data plays a vital role in a data platform. The author shares the experience of one such transition.
The history of big data takes people on an astonishing journey of big data evolution, tracing the timeline of big data. The Emergence of DataStorage and Processing Technologies A datastorage facility first appeared in the form of punch cards, developed by Basile Bouchon to facilitate pattern printing on textiles in looms.
An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining data processing systems and solutions on the Microsoft Azure cloud platform. A Data Engineer is responsible for designing the entire architecture of the data flow while taking the needs of the business into account.
3EJHjvm Once a business need is defined and a minimal viable product ( MVP ) is scoped, the data management phase begins with: Dataingestion: Data is acquired, cleansed, and curated before it is transformed. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.)
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
The sources of data can be incredibly diverse, ranging from data warehouses, relational databases, and web analytics to CRM platforms, social media tools, and IoT device sensors. Regardless of the source, dataingestion, which usually occurs in batches or as streams, is the critical first step in any data pipeline.
Efficient Scheduling and Runtime Increased Adaptability and Scope Faster Analysis and Real-Time Prediction Introduction to the Machine Learning Pipeline Architecture How to Build an End-to-End a Machine Learning Pipeline? The final sample used for training and testing the model is the output of data preprocessing.
Known as the Modern Data Stack (MDS) , this suite of tools and technologies has transformed how businesses approach data management and analysis. What is a modern data stack? A data stack, in turn, focuses on data : It helps businesses manage data and make the most out of it. Modern data stack architecture.
A brief history of datastorage The value of data has been apparent for as long as people have been writing things down. In a data lake raw data can be stored and accessed directly. The data lakehouse concept shares the goals of hybrid architectures, but is designed from the ground up to meet modern needs.
The task of integrating, manipulating, and merging data from diverse structured and unstructured sources into a structure utilized to build analytics solutions falls within the purview of an Azure Data Engineer, a highly qualified specialist. As a result, they can work on a number of projects and use cases.
Data lakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content